 夜雨聆风
夜雨聆风
马佳彬
微信改版啦,一定别忘记点击上方蓝色的公众号名称,进入公众号资料页面,在右上角点击“...”设为星标★,更多干货,不再错过!
上下文,是AI的脑容量。作为AI智能体(Agent)的小龙虾,它的脑容量取决于你接入的大模型,大模型的上下文窗口大小,就是脑容量的大小。
如何知道,或者查询大模型上下文窗口的大小?这个一般你去服务提供商的模型介绍页面,都会有对应的内容。
以阿里云百炼为例,在模型广场中随便挑一个Qwen3.5-plus模型,通过介绍页面内容可以看出,它的上下文长度(窗口)为1M(1百万),如图:
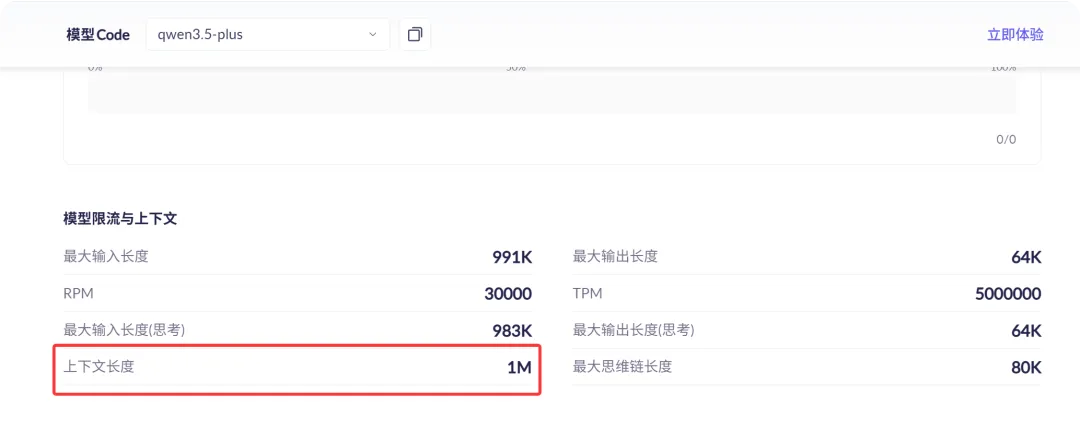
在一个对话窗口中,所有上下文加起来的内容长度,不能超过1M,这就是所谓的上下文窗口。超过这个窗口的内容,模型就看不到了,或者叫丢失了。
用生活化的场景来描述,大家可能更好理解。你人在窗口的范围内,你就能看到窗口里面的东西,越过离开了窗口范围,两边都只能看到空墙壁。
AI智能体的能力,一个是看上下文的管理,另外一个是看调用工具。当然,今年因为是马年,所以就兴起了另外一种更为全面的概念。
叫Harness Engineering(驾驭工程),不仅成为了硅谷的热词,也是最近国内AI圈子比较火的新概念名词。
Harness又被称为马具,给马套上的一整套用具,让马能正常干活。放在AI智能体身上,就是给它设计一整套系统,让智能体能更好地干活。
Harness是上下文工程的一种进化,或者叫完善。因为Harness涉及到智能体的循环、工具、协作、记忆、自主等方面的设计。
它不是指具体的某一项技术,某一项能力,某一项工程。而是给AI智能体搭建一个操作系统,一个OS底层逻辑的构建思维。
突然扯到Harness,因为这个概念大概率会成为未来AI智能体时代,绕不过的核心。大家都会去讨论这套东西,或者说它已经成为了一种能力。
拿3月31日Anthropic意外泄露的Claude Code源代码的事件来说,业内关注的是Claude Code这个AI编程智能体的Harness Engineering设计。
一个世界顶级的AI智能体,是如何搭建底层操作系统的。这对于很多正在研究和研发相关产品的公司和团队而言,具有极大的参考借鉴意义。
而不是说拿这套源代码去修修改改,套个壳变成自己的产品。俗话说授人以鱼不如授人以渔,人家的这次失误,给我们的是学会去钓鱼的机会。
回到今天的主题,上下文管理作为Harness Engineering所设计的操作系统中的一部分,对于我们玩转OpenClaw小龙虾而言,重要性也很大。
大部分小白用户是不知道有这样一套规则体系存在的,在实际养虾的过程中,经常会遇到上下文窗口爆满,不知所措的情况。
最明显的问题就是小龙虾突然失忆,忘记了几小时前的对话内容。对话进行到一半,小龙虾报错说上下文太长。
接入一些小模型,尤其是本地使用Ollama部署的小模型时,经常因为小模型本身上下文窗口太小,导致没聊几句,窗口就爆满。
经过一轮的长对话后,发现小龙虾越来越傻,回复也越来越慢,甚至开始胡言乱语,中英文混合输出。
对于以上上下文窗口爆满的情况,小龙虾的处理逻辑一般包括压缩和修剪。压缩好理解,只保留核心主题,摘要。修剪是删除工具输出的结果。
当然,这跟新开会话不是一回事,主要是面向当前的会话。而OpenClaw小龙虾的上下文管理,跟记忆系统管理是息息相关的。
如果小伙伴对OpenClaw的记忆系统还不是很了解,可以回看老马上两篇文章:OpenClaw记忆系统全面解析,打造不会失忆的小龙虾,OpenClaw小龙虾记忆系统实战小白指南。
下面老马将从OpenClaw的5层上下文管理策略,如何避免上下文溢出,以及优化你的上下文使用三个方面给大家介绍清楚。
5层上下文管理策略
第一层:会话隔离(Session Isolation)
会话隔离就是不同的渠道对话使用不同的会话,它们之间互不干扰。每个会话都是独立管理上下文,这样能够避免无关的内容占用上下文。
举个例子,你的OpenClaw小龙虾同时接入了QQ机器人和微信Clawbot机器人。此时,你正在通过这两个渠道跟小龙虾聊天。
这里两个渠道的会话就是隔离的,不会串门的,同时上下文各自独立。不会说你QQ机器人这边聊得多了,微信机器人这边的上下文就会受影响。
同理,不同Agent之间的会话也是隔离的,上下文一并如此。假设你除了一个叫main的主Agent之外,还另外创建了Coder、Writer两个子Agent。
三个Agent都可以单独挨个去对话,而且他们之间的会话记录跟上下文没有关联。你给main安排的任务,Coder跟Writer不知道。
因此多Agent要进行协作,就必须打通之间会话,把每条独立的电话线串起来,俗称跨会话通信,一般使用sessions_send工具去完成。
OpenClaw的会话隔离机制默认是开启的,属于核心的设计原则之一,它体现在OpenClaw.json里面的配置内容如下:
{"session": {"dmScope": "per-channel-peer" // 按渠道隔离}}
以上配置内容仅供你了解知晓,并不需要你自己去设置。其中per-channel-peer就是按渠道和发送者共同隔离会话的值。
除了设置per-channel-peer模式之外,session.dmScope还有4个可选值:
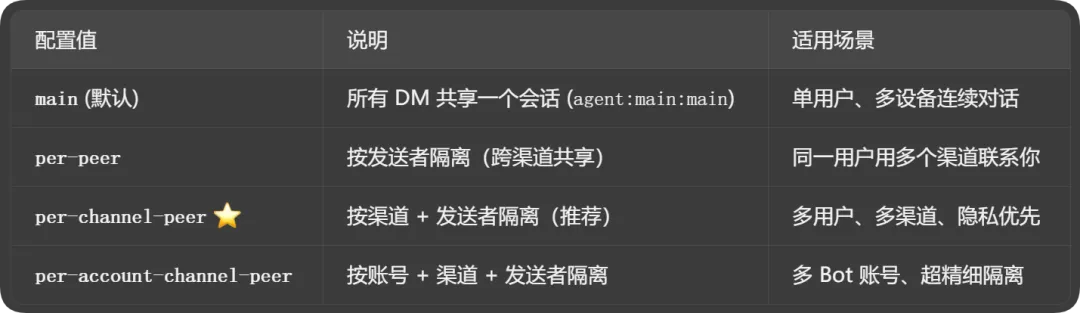
根据以上表格,如果你是多Agent,多Bot机器人账号的情况下,per-account-channel-peer是可选的配置值。
当然这里老马只是拓展一下知识内容,一般情况下你保持官方默认per-channel-peer配置值即可,不需要去改动。
第二层:每日重置(Daily Reset)
每日重置是针对会话的,相当于OpenClaw每天在凌晨4点的时候,会自动帮你开启新的会话,哪怕你之前的会话窗口还没关闭,或者没通过/new命令启动过新会话。
这种重置是强制性的,能让每天的会话都是新的开始,避免昨天的历史包袱累积。类似于睡了一觉醒来,把昨天堆积的上下文都清理干净了,排空了记忆。
除了昨天的上下文记忆会整理成摘要总结,保存在每日记忆里面。其它细枝末节的东西,通通抛弃掉,可以认为是更为彻底的压缩,压到渣都不剩。
每日重置在OpenClaw.json文件中搜一下dailyAt字段,如果没有,则需要手动配置开启,具体的配置内容如下所示:
{"session": {"reset": {"dailyAt": "04:00" // 每天 4 点重置}}}
你觉得凌晨4点不好,想修改一下,那随便你修改时间的配置值。开启每日重置的好处就不用说了,就是为了更好地管理你的上下文。
第三层:空闲超时重置(Idle Reset)
空闲超时重置类似于每日重置,也是针对会话空闲时间达到设定的时间值,自动清空会话的上下文,重新开启一个新会话。
OpenClaw系统默认设置的是120分钟超时,即120分钟内,你没有再跟你的小龙虾聊过天,不管是通过什么渠道,QQ机器人,微信机器人都算。
那么2个小时后,系统就会自动开启一个新的会话,之前的老会话就失效了,上下文也失效了。
这样也是为什么空闲超时重置之后,有些小伙伴会懵逼。明明刚才跟小龙虾都描述过任务的背景信息了,告诉它我电脑上有什么文件需要处理了。
怎么隔了几个小时回来再聊,它就什么都忘记了。每日重置同样如此,有小伙伴反馈是隔天小龙虾就忘记了昨天的事情。
基本上原因就是会话被重置了,重新开启了新会话,原有的上下文丢失了。而新会话没来得及加载昨天的记忆文件,或者昨天的记忆文件没保存,导致无法加载。
如果加上长期记忆文件MEMORY.md也没记录摘要重点,那就等于基本失忆了。因此优化好记忆系统很重要,记得翻看老马之前的文章多多回顾。
空闲超时重置在OpenClaw中默认没有开启,需要手动配置开启,具体的配置内容如下所示:
{"session": {"reset": {"idleMinutes": 120 // 2 小时无活动重置}}}
空闲超时重置老马觉得保持默认不开启也没多大关系,不然会影响当天的上下文完整度,老是隔两个小时被重置一次也挺烦的。
第四层:自动压缩(Auto-Compaction)
上下文在达到阀值时,系统会自动帮我们压缩。经常使用OpenClaw的Web UI网页控制台界面,去跟小龙虾的聊天的小伙伴就知道。
经常会有一句提示正在压缩中,这其实就是在压缩上下文。自动压缩会涉及到三个值,一个是contextTokens(已经达到的token数)。
contextWindow(上下文窗口数),reserveTokens(预留的安全token数)。一般来说contextTokens要大于contextWindow减去reserveTokens。
如果把contextWindow比作一个杯子,那上下文窗口就是一个杯子的容量,比如是1000毫升。contextTokens是已经喝了的水量,比如是850毫升。
reserveTokens是预留的安全水量,防止水倒得过满溢出来,比如是200毫升。当已喝的水量 (850毫升) > 杯子容量 (1000毫升) - 安全水量 (200毫升)时,即850毫升 > 800毫升。
此刻就触发到了自动压缩的阀值,该倒掉一些旧水了,该压缩一些旧的上下文了,不然杯子里的水就要溢出来了。
可能这里小伙伴还没反应过来,还不能理解,怎么已喝的水量大于800毫升就得压缩上下文了。很简单,咱们把已喝水量,换成往空杯子里倒水。
空杯子,即上下文窗口,contextWindow是1000毫升,对不对。安全水量是不变的,还是200毫升。当杯子里面倒了850毫升的contextTokens了,那是不是就达到800毫升自动压缩的阀值了,这样估计更好理解。
自动压缩机制在OpenClaw中是默认开启的,当你的上下文快满时,就会自动压缩旧的会话,具体的配置内容如下所示:
{"agents": {"defaults": {"compaction": {"mode": "safeguard", // 保护模式"model": "claude-sonnet-4" // 用更好的模型压缩}}}}
我们看上面配置内容中的mode模式,默认是safeguard保护模式,即在必要时自动压缩。必要时压缩分为三个档位,轻度、中度、重度。
轻度是指上下文窗口使用率已达到50-70%时,触发轻度警告,系统会压缩最早的对话,保留最近20-30条。
中度是指上下文窗口使用率已达到70-90%时,触发中度警告,系统会压缩后,总结旧对话写入记忆文件。
重度是指上下文窗口使用率已达到90%以上时,触发重度警告,系统会进行紧急压缩,只保留最近5-10条对话和关键记忆。
这个值也可以设置成auto自动模式,即达到阀值时自动压缩。此外还有manual模式,就是手动触发,需要你手动输入命令/compact进行压缩。
第五层:记忆持久化(Memory Persistence)
记忆持久化,就是在压缩上下文之前,提前将重要信息写入记忆文件,整个过程跟自动流水线作业差不多,不需要你人工去干预的。
系统检测到即将压缩上下文了,马上提醒小龙虾保存重要信息到记忆文件,小龙虾开始写入MEMORY.md或memory/YYYY-MM-DD.md。然后开始执行上下文压缩,下次会话时,再从记忆文件读取关键信息。
记忆文件再次啰嗦一下,一般保存的路径是.openclaw\workspace目录下,主要文件有MEMORY.md长期记忆文件,以及子目录memory下的2026-04-01.md的日常记忆文件。
如何避免上下文溢出
避免上下文溢出的情况,我们一般会用到四个技巧,分别是使用压缩命令,开启新会话,利用记忆系统保存关键信息,定期清理旧会话。
其它的机制咱们就不讨论了,因为前面的5层的上下文管理策略,也算是系统默认自带的,防止上下文溢出的方式,虽然有些默认没开启,但你可以选择是否开启。
1、合理使用/compact命令
假设当前会话窗口中,对话的次数已经超过了50轮次,这已经算是一个长对话了,此时,就可以输入/compact命令,手动压缩一下上下文。
或者你已经完成了一个项目阶段,一个任务的阶段,在准备开始新话题之前,同样可以运行/compact命令,好处是避免上下文之间有交集,对接下来的新项目和新任务产生干扰。
2、使用/new开启全新会话
当你需要清空当前会话历史,开启一个全新的对话窗口,不想保留任何上下文的时候,输入/new命令即可。
还有一种极端的情况,由于OpenClaw的Web UI网页控制台体验较差。有可能会遇到一直提示正在自动压缩上下文,整个页面卡住很长时间。
这时可以试试直接运行/new命令开启新会话,摆脱这种页面长时间假死的状态。
3、利用记忆系统保存关键信息
这个技巧也算是一种好习惯,当你遇到一些重要的信息时,多习惯性地跟小龙虾说一句,把这段内容,或者这句话,写入到长期记忆中。
比如:我常用的编程语言是Python,数据库是PostgreSQL,请记住。像这样就是手动让小龙虾利用记忆系统保存关键信息的方法。在上下文没被自动压缩前,手动做的一个动作。跟记忆持久化不一样,人家是自动的。
4、定期清理旧会话
首先通过输入下面的命令,查看会话列表:
openclaw sessions list再使用以下命令,预览和执行清理旧会话:
# 预览将要清理的会话openclaw sessions cleanup --dry-run# 执行清理openclaw sessions cleanup --enforce
如果你觉得每次都要手动输入命令去操作太麻烦,那可以在OpenClaw.json里面添加下面的配置内容,设置成自动清理。
当然,手动去修改配置文件,添加配置会比较容易出错。你可以用自然语言跟小龙虾说,帮我设置一下配置文件,自动清理旧会话的机制。30天后自动清理,最多只保留500个会话,会话文件最多占用100mb磁盘空间。
那么以上自然语言对应的配置内容,就如下面的json内容所示,其实意思都是一样的:
{"session": {"maintenance": {"mode": "enforce","pruneAfter": "30d", // 30 天后清理"maxEntries": 500, // 最多保留 500 个会话"maxDiskBytes": "100mb" // 最多占用 100MB 磁盘}}}
优化你的上下文使用
优化上下文使用属于相对比较高阶一点的配置,一般小伙伴们用不上,上面介绍的5层上下文管理策略,以及避免上下文溢出的技巧,已经足够了。
还想进一步优化的话,就会涉及到多模型的接入,调整预留的token数,启用会话修剪,自定义压缩提示词这四个方面。
一、使用更好的模型进行压缩
以前你压缩上下文的效果比较差,容易丢失重要信息,导致压缩之后,记忆没了,多半原因是使用了参数量较小的小模型。
小模型去负责压缩上下文是不行的,得使用大模型压缩。尤其是在本地使用Ollama部署的小伙伴,绝大部分都是部署的小模型,硬件限制了。
大模型没几个家里有矿的,有那么多高端显卡部署得起来。因此,小模型可以用于日常对话,大模型用来压缩上下文,彼此配合。
这就会涉及到多模型接入,对此不了解的小伙伴,可以回看老马之前的文章:OpenClaw接入多个模型实现自动手动切换配置。
使用小模型对话,日常还比较省token,反正大多数是部署在本地跑的。用大模型压缩上下文,质量高,能够保留关键信息到记忆文件中,总而言之就是成本更低,性价比高。其配置文件内容如下:
{"agents": {"defaults": {"model": "ollama/llama3.1:8b", // 日常用小模型"compaction": {"model": "openrouter/anthropic/claude-sonnet-4-6" // 压缩用大模型}}}}
二、调整预留token数
还记得老马上文中提到的喝水的例子么,reserveTokens是安全水量,也就是预留的token数,可以稍微设置多一些,假设比200毫升多100毫升。
预留太少,就很容易导致水溢出来,tokens溢出来,这个例子就不再重复介绍了。其配置文件的内容如下所示:
{"agents": {"defaults": {"compaction": {"reserveTokens": 32768, // 预留 32k tokens"keepRecentTokens": 40000 // 保留最近 40k tokens}}}}
从上面配置内容可以看出,reserveTokens预留的是32k的tokens,即32000tokens,以上配置内容需要你手动去修改配置文件进行设置。
一般来说,小模型(假设是8B),可以预留16K(16384)tokens。中模型(假设70B),预留32K(32768)。大模型(假设220B),预留64K(65536)tokens。
三、启用会话修剪
会话修剪上文中提过一嘴,修剪后能够保留对话的主干,主要信息,去除掉过长的工具输出内容,节省大量的token。
像小龙虾在调用工具时,输出的一些内容基本对用户来讲是没有多大意义的,它只需要知道调用哪个工具,完成什么样任务这些重点就行了。因此可以把无意义的上下文内容修剪掉,其配置文件内容如下:
{"agents": {"defaults": {"pruning": {"enabled": true,"maxToolOutputTokens": 2000 // 工具输出最多 2k tokens}}}}
从上面的配置内容中可以看出,maxToolOutputTokens就是设定工具在被调用时,最多能输出多少tokens的内容,超出的直接修剪掉。同样的,以上配置内容需要你手动去修改配置文件进行设置。
四、自定义压缩提示词
自定义的压缩提示词其实是一句Prompt提示词,老马贴出来仅供大家参考,要不要去手动在配置文件设置,看大家的需求。
如果配置了,它就相当于给自动压缩加多了一句提示词,让自动压缩有了行为的指导,压缩的标准,如下所示:
{"agents": {"defaults": {"compaction": {"prompt": "总结对话内容,重点关注:1、关键技术决策 2、待解决的问题 3、行动项和待办事项 4、对未来工作重要的背景信息"}}}}
属于定制化个性化地去压缩内容,保留对你比较重要的信息,忽略无关紧要的细节。这句Prompt提示词不是固定死的,你可以根据老马上面提供的示例,按你的要求去进一步修改。
常见问题解答
Q1: 为什么小龙虾总是忘记我说的话?
可能原因:
1. 上下文窗口太小(如8k/16k)
2. 压缩上下文太过于激进
3. 没有使用记忆系统
解决方案:
{"agents": {"defaults": {"model": "claude-sonnet-4", // 换大上下文模型"compaction": {"reserveTokens": 32768 // 增加预留空间},"memorySearch": {"enabled": true // 启用记忆搜索}}}}
Q2: 如何查看当前上下文使用情况?
使用命令:
openclaw status输出示例:
Session: agent:main:mainModel: claude-sonnet-4Context: 45,230 / 200,000 tokens (22.6%)Input: 12,345 tokensOutput: 8,234 tokens
Q3: 压缩上下文后小龙虾变得傻傻的怎么办?
可能原因:
压缩时摘要丢失了关键信息
解决方案:
方案1:改进自定义压缩提示词
{"compaction": {"prompt": "详细总结以下内容,保留所有技术细节、代码片段、决策原因"}}
方案2:使用更好的压缩模型
{"compaction": {"model": "claude-opus-3" // 用更好的模型压缩}}
方案3:延迟压缩
{"compaction": {"reserveTokens": 65536 // 增加预留,延迟压缩触发}}
Q4: 如何让小龙虾记住跨会话的信息?
想要记住跨会话的信息内容,那就得使用记忆系统了。
步骤1:确保记忆功能的配置已经设置启用
{"agents": {"defaults": {"memorySearch": {"enabled": true,"provider": "local"}}}}
步骤2:重要信息会自动保存到MEMORY.md长期记忆文件。
步骤3:当开启新会话时,小龙虾会去自动读取长期记忆文件。
Q5: 上下文窗口总是很快满了,怎么办?
首先进行一下诊断,看看上下文老是很快爆满的原因是什么。
步骤1:检查模型上下文窗口
openclaw status一般来说,你设置的模型上下文窗口,一定要跟模型服务提供商介绍的上下文长度是一致的,这样才是正确的设置。
步骤2:查看是什么占用了那么多上下文
(1)如果是系统提示词太长了,那说明你默认加载的SOUL.md、AGENTS.md之前设置得太复杂,写得太多了,需要简化一下。
(2)如果是调用的工具输出内容过长,那就得启用上文中提到的会话修剪,把工具输出的最多tokens数值,设置得小一些。
(3)如果是历史对话太长,已经经过了几十上百论对话了,但是还没有触发到自动压缩的阀值,或者说阀值中预留安全tokens设置太小,那就需要调整一下阀值的设置。
Q6: 可以手动编辑会话文件吗?
可以是可以,但是有破坏会话记录.jsonl文件格式的风险存在,而且像一般的删除旧的会话记录,不必要去编辑sessions.json文件,使用以下命令即可:
# 安全清理openclaw sessions cleanup --enforce# 手动重置会话/new
好了,以上就是今天的分享,欢迎关注、点赞、转发一键三连。有任何问题和需求,请在评论区留言,回见!
 对了,老马最近刚创建了一个AI学习交流群,有兴趣进群的小伙伴可以添加老马微信号:immajiabin,添加好友时备注:进群(不备注不通过)。
对了,老马最近刚创建了一个AI学习交流群,有兴趣进群的小伙伴可以添加老马微信号:immajiabin,添加好友时备注:进群(不备注不通过)。

