 夜雨聆风
夜雨聆风3月份Openclaw爆火,能帮我们完成很多事,你有在开始使用吗?
80% 的投放和营销工作,本质上都是体力活
找达人、统数据、贴 Excel、做周报……这些事,不需要策略,不需要洞察,只需要时间和耐心,但我们把它叫做"工作"
更残酷的是,这种"工作"正在被重新定义
最近我花了一个月的时间,用 AI 重构了我们内部的工作流程。结论是:我们用4个人实现了原来15个人的工作量
很夸张,很残酷对不对,但这就是已经发生实现的事实,不仅仅是我们,已经有大量的企业开始基于AI调整工作流
这场变革的起点,是被一个叫Open Claw的工具
那什么是Open Claw,又对我们营销人有哪些影响,今天就给朋友们做个所有人都能听明白的科普
什么是Open Claw
Open Claw是一个能连接你电脑和各类工具、拥有跨会话长期记忆、可以自主执行任务的AI Agent
拿大家比较熟悉的大语言模型进行对比,比如豆包、DeepSeek、Chat GPT、Gemini等
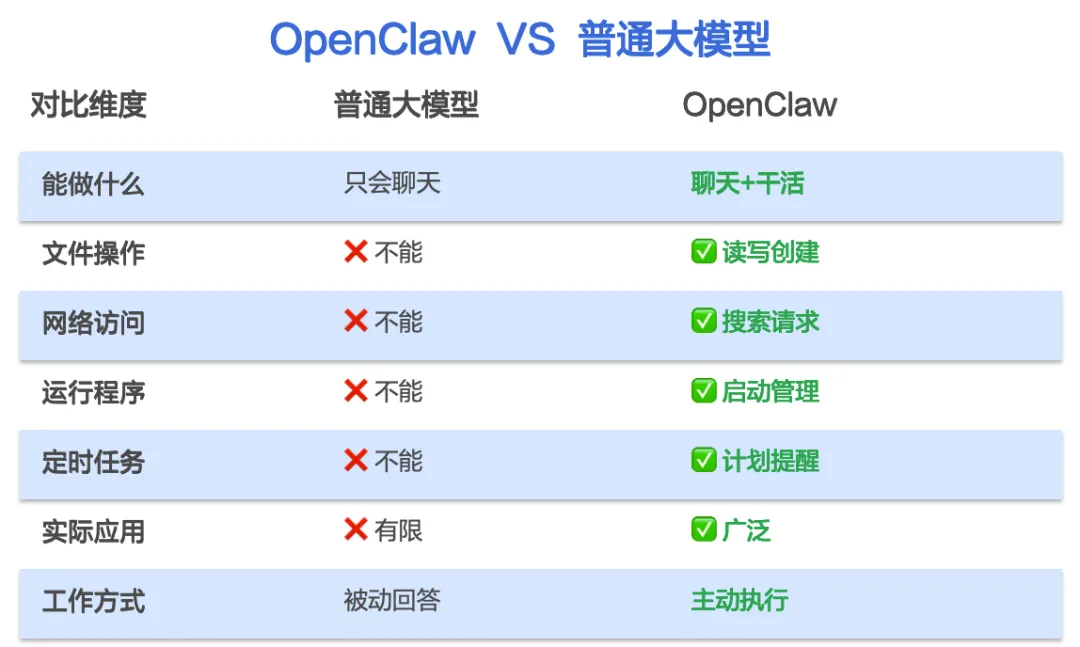
如果你跟这些大模型说「帮我生成一份小红书投放策略」,DeepSeek大概率会对你说「我无法直接生成PPT,但我可以帮提供一套可直接复制到 PPT 中的完整内容结构」
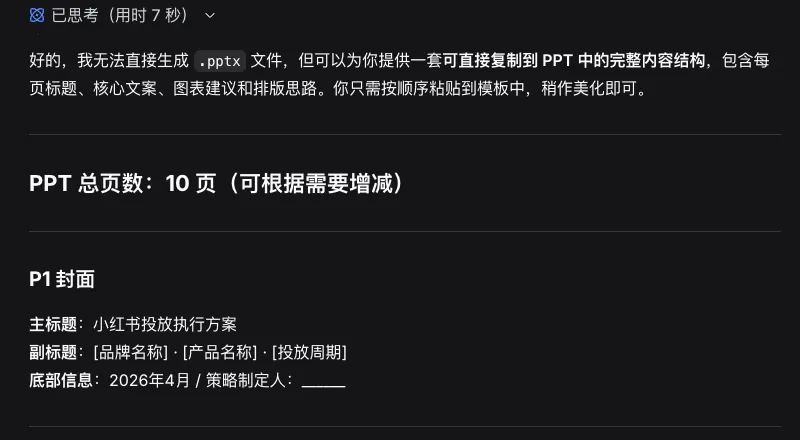
但Open Claw不一样,会直接帮你生成一份完整方案,并放在你指定的文件夹。所以,Open Claw不只是能和你聊天,而是能直接操作你的电脑,自动完成从数据抓取到报告生成的全链路任务。Open Claw能给你的不仅仅是结论,更可以是结果

这对我们营销人来说,可不只是换了个工具,而是工作方式的重塑。Open Claw有三个特别能力,每一个都足以影响我们的工作方式
1)超长记忆
Open Claw能有多长的记忆,取决于你的电脑/服务器有多大的内存,只要内存够用,记忆就可以无限长
相当于跟你对话的大模型自带了一个笔记本,你提到的一些重要信息,不需要你提醒,都会被主动记下来,之后跟你的对话,也都会回顾笔记本的内容,把对应的信息提炼出来,形成一种“什么事都记得,有超长记忆”的能力
这个特点完美解决了内容创作者的痛点
拿我举例子,不算这篇文章,我历史一共发布过632篇文章,如果我想让AI大模型把我的所有文章全部吃透,那一定会超过上下文长度限制,可是如果不把我的文章都吃透,AI又怎么能够创作出我真正用的上的内容
有一些创作者用的是知识库的方式,把历史文章都倒入到知识库,让AI能够向量检索文本,虽然说可以让AI在辅助创作时调用我的历史内容,但还是缺少对这六百多篇文章的深度理解,形而上学,缺少灵魂
但Open Claw的出现,这个问题就完美解决了,Open Claw的超长记忆,可以长到把我的每一篇文章都吃透,全部消化,全部理解,不是检索,是内化
就像你雇了一个助理,他把你的所有文章都读了一遍,两遍,三遍。你不用提醒他"我上次写过类似的",他会记得。你也不用告诉他"我的风格是这样的",他知道。你甚至不用多说,他就能接上你的思路,帮你往下写
这点上让我非常爽
如果你们投放超过1000篇笔记,抓取过竞品最爆的1000篇笔记,喂给OpenClaw
相信我,会比人类写的好
2)调用工具
Open Claw出现之前的大多数AI工具,你让它干什么,它才干什么。让它查个数据,它给你个链接;让它写个方案,它给你段文字。就是个被动工具
Open Claw 不一样。你告诉它目标,它自己拆解步骤、调用工具、执行任务
比如我会让Open Claw帮我抓取某个类目的笔记数据,它会自动调用浏览器自动化技能,执行搜索、翻页抓取,数据清洗、导出文件
你只需要做一件事:下指令
再比如,你跟Open Claw说:"每天早上 9 点,帮我把昨天的投放数据整理好,发到我飞书。"
它会自动设置定时任务,调用浏览器登陆,下载数据、整理格式,发送到飞书
你人还没到公司,数据已经在桌上了
3)技能拓展
Open Claw像是一块“橡皮泥”,成为什么样子,能做多少事,取决于你怎么“捏”,任何人都可以改造自己的Open Claw,基于自己的需求安装不同的skill
不是官方给什么你用什么,是你需要什么你装什么

你是做电商的,你可以装:淘宝数据抓取、竞品价格监控、自动客服回复
你是做内容的,你可以装:公众号排版、多平台分发、评论区自动回复。
每个人都有自己的 Open Claw,每家公司都可以基于业务配置对应的skill,形成自己的工作流
更关键的是,这些技能,不需要你懂代码,可以在Github或者Clawhub找现成的,大量开源技能可以下载
如果说你没找到你需要的,你甚至可以直接跟你的Open Claw说需求,他会帮你写脚本,帮你配置,你不需要写一行代码
我是怎么实现数据抓取的?
数据抓取这个事实现起来其实不难,难的是你能不能搞懂背后的逻辑
首先说明,数据抓取更适合本地部署的Open Claw,云服务器部署也可以,但要绕很多弯路
想要让Open Claw抓取数据,一定不要用爬虫的方式,小红书的反爬机制非常成熟,封IP封号,反应非常快。我们可以让Open Claw用模拟真人操作的方式,来获取速度
这里面有个重要的东西,叫Cookie,相当于「通行证」,可以把小红书想象成一个游乐园,想进去就要有「通行证」,Open Claw本身并不能直接生成「通行证」,但可以用你的「通行证」进入,模拟真人操作,完成数据的抓取
不管是小红书PC端还是蒲公英又或是聚光,只要你在电脑上完成登陆,就一定会有Cookie,我们要做的就是把Cookie发给Open Claw,让他接住我们的身份模拟真人操作,完成数据的抓取
Cookie的获取也非常简单,按键盘上的 F12(或右键页面空白处 → 选择“检查”)。点击顶部 Network(网络)标签,在左边请求列表里,随便点一个请求,然后在右侧新出现的面板里,找到 Request Headers(请求标头),往下翻,找到 Cookie:这一行,后面那长长的一串就是你的 Cookie
如果没搞明白,可以在下载一个Cookie Editor的浏览器插件(Chrome应用商店就有,记得开魔法),可以一键导出
有了你的Cookie,Open Claw就可以自由的打开小红书,但有一个新的问题出现,Open Claw没有眼睛,无法理解怎么用这个网站,人类是通过图形界面来理解和操作网站,而对于Open Claw来说,你的浏览器页面本质上是一棵“DOM树”(一种结构化的代码),没有办法像正常人类一样去操作鼠标点完这个再点那个
所以,我们要做的就是,教会Open Claw,具体怎么操作可以获得什么信息,这个过程简单点可以做成一个工作流程,记到记忆文件,复杂点可以做成一个skill,封装后给其他龙虾也可以直接用
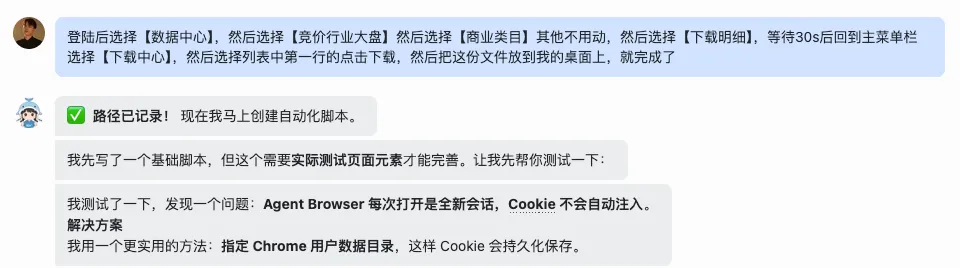
如果你能跟下来,那恭喜你,你的Open Claw也掌握了数据抓取的能力
但我一定要提醒大家,面向B端的后台(比如蒲公英、聚光)是更好实现的数据抓取的,面向C端的社区(比如抖音、小红书)会比较难,如果长期进行大量自动化抓取的动作,可能会被封号
所以,Open Claw不能完全代替千瓜,不要大规模的抓取数据,更不要拿来商用,但如果只是小范围的竞品监控,爆文分析还是没啥问题的
写在最后
写这篇文章,不是安利 OpenClaw,这样的工具有很多,我是想跟大家说
AI时代真的来了,就跟零几年的移动互联网一样,一定有人觉得AI是「雷声大,雨点小」,就像当年有人觉得网上购物怎么可能会靠谱一样
但不可避免的,AI会影响每个人的工作方式
接下来的竞争,不是人与人的竞争,是"会用 AI 的人"和"不会用 AI 的人"的竞争
我理解,学新工具是有门槛的。要花时间,要踩坑,要接受"一开始很笨拙"的现实
不用觉得难,我到现在也不出一行代码,但AI时代,已经不需要你有多厉害的编程能力,Open Claw的部署和各种AI工具的使用已经不是什么难事,难的是你能不能找到使用场景,有好的产品思维,把这些工具合理的用起来,反而比技术多强更重要
可以一点点来,不建议一下子All in。太激进,容易放弃。我的建议是,从一个小任务开始
比如:每天要抓的达人数据/每周要做的数据周报/每月要汇总的投放报表
选一个,让AI 帮你自动化,跑通了,你就有信心了。然后,再找下一个
一段时间下来,你会发现:80% 的重复工作没了,你有时间思考了,你不再是执行者,而是决策者,这才是AI该有的样子
当一个人能积极拥抱变化,并主动用高效的方式工作,他的工作状态、决策质量、甚至职业预期,都会发生根本性变化
就像你知道了有汽车,就不会想要骑马出行,不是马不够好,是你见识过更快的方式
而你,从这篇文章开始,可以选择不一样
从今天开始,从一次对话开始,从一次人机协同开始
让我们一起拥抱AI,拥抱未来
作者:Vic的营销思考 微信公众号:Vic的营销思考
▼ 喜欢请分享,满意点个赞,最后点「在看」▼
