 夜雨聆风
夜雨聆风全文共 4373 字,阅读约需 10 分钟
作者 | 傅榕锋 OceanBase 高级技术专家,seekdb M0 研发团队负责人
如果你在用 OpenClaw,你大概率经历过这样的场景:
昨天下午你和 Agent 花了两个小时排查一个线上问题。过程中它帮你查了日志、读了配置、试了好几种方案,最后定位到是连接池配置导致的。你们还顺便讨论了项目里几个服务之间的依赖关系,以及下周要做的重构计划。
第二天早上,你让它继续昨天聊到的重构。它回了一句:「你好!请问你说的是哪个重构?能给我一些背景吗?」
昨天那些讨论,它全忘了。
这不是偶发现象。MEMORY.md 里的基本信息——你的名字、偏好、常用工具——这些它记得住,因为每次都会加载。但昨天对话里的具体细节——排查过程中发现的关键线索、讨论过的方案取舍、约定好的下一步计划——这些留在了 session 历史和 `memory/` 目录的文件里。新 session 开始后,Agent 需要主动搜索才能找回这些细节,但它不一定知道该搜什么,也不一定搜得准。换成 idle 模式能缓解 session 切割的问题,但治标不治本:session 越长,累积的 token 越多,Agent 回复越慢。
根本矛盾是:OpenClaw 的记忆机制是为「单次对话」设计的,而用户期望的是一个「长期相处的私人助理」。
这就是 seekdb M0 要解决的问题。
seekdb M0 官网:https://m0.seekdb.ai/

OpenClaw 的记忆为什么会崩
先别急着看方案。搞清楚问题出在哪,方案才会有说服力。
OpenClaw 有记忆机制——MEMORY.md 文件和基于 SQLite 的语义检索。但这套机制在长期使用中会陷入两个恶性循环。
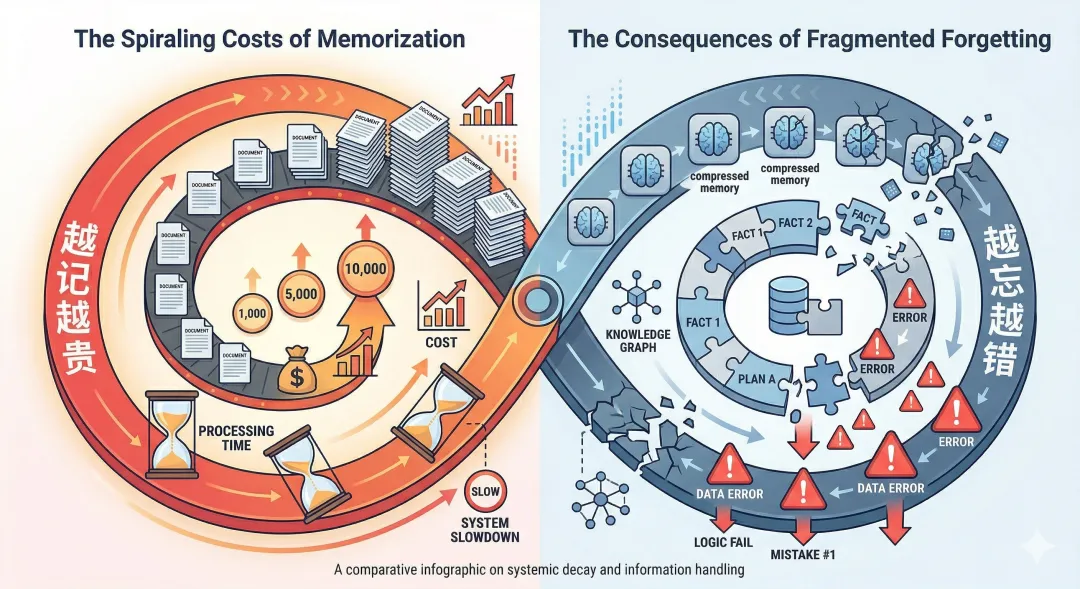
循环一:越记越贵。
Agent 把重要信息写入 MEMORY.md。这个文件会被全量加载到每次请求的系统提示词里。用的时间越长,MEMORY.md 越大,每次 API 调用的 input token 越多,响应越慢。Bootstrap 文件有单文件 20K 字符的默认上限(总计 150K),但早在到达上限之前,臃肿的上下文就已经开始挤占 Agent 的工作空间了。
更糟糕的是,Agent 知道信息可能会丢,于是更积极地往 MEMORY.md 里塞东西——加速膨胀。
循环二:越忘越错。
当 session 太长时,OpenClaw 会触发两套机制来应对。
一是 compaction——用 LLM 把旧对话分段总结压缩,腾出上下文空间;
二是 memory flush——在 compaction 前启动一个嵌入式 agent,让它自行决定把哪些重要信息写入 memory/YYYY-MM-DD.md。但 compaction 的总结本质上是有损压缩,而检索侧的切片逻辑按行和字符预算硬切(默认 400 token 一块),不识别语义边界。关键上下文可能被切断,检索召回质量差。Agent 找不回需要的信息就犯错,犯错就返工,返工产生更多对话,更快触发下一次压缩。
工具调用是加速器。 这是很多 OpenClaw 用户没意识到的一点。Agent 调用工具产生的中间结果——web_fetch 返回的网页、exec 输出的命令结果——单条最大 400K 字符,会快速填满 session。这些中间过程不适合写进 MEMORY.md,但可能包含有价值的信息。无论选哪条路,工具调用都会加剧恶性循环。
两条路的本质矛盾是:记住的代价是昂贵,遗忘的代价是犯错。
需要第三条路。

seekdb M0:记忆独立于上下文
seekdb M0 是一个 OpenClaw 云端记忆插件,核心理念一句话:不把所有记忆塞进 system prompt,而是在每次对话开始前,只检索与当前话题相关的记忆片段注入上下文。

和 MEMORY.md 的全量加载不同,seekdb M0 把记忆拆解为独立的「事实」存储在云端数据库中。每条事实都有向量表示和全文索引。对话开始前,seekdb M0 用混合检索(BM25 + 向量相似度)找到最相关的几条记忆注入上下文;对话结束后,自动从对话中提取新事实,与已有记忆比对后决定新增、更新还是跳过。
这意味着:
MEMORY.md 不再膨胀——记忆存在云端,不占系统提示词空间
session 重置不再是灾难——记忆是持久化的,新 session 开始时自动召回
跨设备同步——换一台机器,记忆还在
整个过程对用户透明——你只管和 Agent 聊天,M0 在后台自动管理记忆。
但如果只是「把 MEMORY.md 搬到云端」,seekdb M0 的价值就有限了。真正的差异在记忆管理的方式上。

seekdb M0 做了哪些事
两阶段记忆管理:先提取,再决策
OpenClaw 原生的记忆持久化依赖 compaction 总结和 memory flush agent——前者把整段对话(含全部工具输出)压缩成摘要,后者让 LLM 自行决定把什么写入文件。两者都是全量处理对话内容,token 开销大,信息有损。seekdb M0 不这么干,它把「存什么」和「怎么存」拆成两个独立的阶段。
第一阶段:事实提取。对话结束后,seekdb M0 只提取 user 和 assistant 之间的对话文本(跳过所有工具调用的中间输出),用 LLM 抽取出原子化的事实。比如「用户叫张三,是数据库工程师,在杭州工作」会被拆成三条独立事实。
提取时有几条硬规则:时间信息必须保留(「去年去了夏威夷」不会被简化成「去了夏威夷」);保持原语言不翻译;敏感信息一律不提取。
第二阶段:记忆决策。 提取出的事实不是直接写入数据库,而是先和已有记忆做比对。M0 用向量检索找到最相似的已有记忆,然后让 LLM 判断:这条事实应该新增(ADD)、更新已有记忆(UPDATE)、删除矛盾记忆(DELETE),还是已经被覆盖可以跳过(NONE)?实际运行中,为了避免误删,插件侧会把 DELETE 当作 NONE 处理——auto-capture 只新增和更新,永远不主动删除已有记录。
新事实:「去年五月去了夏威夷」已有记忆:「去过夏威夷」→ 决策:UPDATE(补充了时间信息)新事实:「不喜欢吃披萨了」已有记忆:「喜欢吃披萨」→ 决策:UPDATE(偏好发生了变化)新事实:「是软件工程师」已有记忆:「名字是 John」「是软件工程师」→ 决策:NONE(已有记忆已覆盖)
有一个有趣的实现细节:送给 LLM 做决策时,已有记忆的 ID 会被替换成临时编号(0、1、2…),避免模型幻觉长整型 ID。如果模型返回的 ID 无法映射回真实记忆,系统会优雅降级为新增。
这种两阶段设计的好处是关注点分离——提取阶段保证事实的质量和合规性,决策阶段保证记忆库不会无限膨胀。
工具调用自动压缩:零 LLM 开销
前面说了,工具调用的中间输出是 session 膨胀的主要推手。seekdb M0 的处理方式很直接:用确定性规则压缩,不花一个 LLM token。
当工具结果被持久化到会话历史时,seekdb M0 的 tool_result_persist 钩子会介入,把原始输出替换为结构化摘要:
原始:curl 返回了一个 3000 行的 JSON 响应压缩后:工具:web_fetch状态:success输出:3000 行 / 48K 字符预览:{"users": [{"id": 1, "name": "Alice"...(300 字符)
压缩比极高(几万字符 → 几百字符),且完全是规则化的——不需要 LLM 理解内容,只需要保留「做了什么、结果如何、简要预览」。
在事实提取阶段,seekdb M0 直接跳过所有 tool/toolResult 类型的消息,只看人和 Agent 之间的对话。这意味着即使一次对话涉及大量工具调用,事实提取的 LLM 输入也被控制在很小的范围内。
与 OpenClaw 原生的做法相比——compaction 时把完整 session(含全部工具输出)送进 LLM 压缩——这种方式从源头控制了送入 LLM 的数据量,而不是等到溢出了再惰性压缩。
经验系统:从应届生到专家
记忆解决的是「记住用户是谁、喜欢什么」的问题。但 OpenClaw 用户还有另一个困扰:Agent 有 skill,但没有实践经验。
一个装了各种 skill 的 OpenClaw Agent,就像一个刚从学校毕业的学生——专业知识有了,但真正上手办事时,会遇到各种课本里没写过的问题。
举个例子:线上服务报 503,Agent 排查时发现日志里满是「connection refused」,但数据库正常。来回折腾二十分钟后才发现问题在连接池——一条慢查询卡住了所有连接。kill 掉慢查询,服务恢复。
这种排障经验不会写在任何 skill 的说明文档里——「数据库健康但服务报 connection refused 时,检查连接池是否被慢查询耗尽」——这是纯粹的实践智慧,只有踩过坑才知道。
问题是:下次另一个 OpenClaw 用户遇到一模一样的症状,他的 Agent 又得从头摸索二十分钟。
人类有同样的困境——新人排障靠试错,老师傅一眼就能看出问题。但人和 Agent 有一个根本区别:人不能共享大脑,Agent 可以。

这就是 seekdb M0 的经验系统要做的事:让一个 OpenClaw Agent 踩过的坑,所有 OpenClaw Agent 都能受益。
第一个 Agent 花二十分钟排查出的结论,第二个 Agent 在遇到相似症状时直接就能看到——不是因为它自己经历过,而是因为有别的 Agent 已经经历过并分享了经验。
经验(experience)和记忆(memory)是两种不同的东西。 记忆是个人事实——「用户喜欢深色模式」「用户住在杭州」。经验是通用智慧——「数据库健康但服务连不上时优先检查连接池」「部署到容器时需要设置 LANG=C.UTF-8 否则中文会乱码」。
M0 的经验系统有四个阶段:
自动蒸馏:当一次对话成功完成且涉及工具调用时,seekdb M0 会在后台异步分析这次交互,提炼出可复用的经验。这个过程是非阻塞的,不影响正常对话。
分级验证:新经验不会立刻对外公开。它有一个生命周期——Draft(刚提取,仅对创建者可见)→ Published(正向反馈累积达到阈值后进入公开池,所有用户可检索)→ Deprecated(负向反馈比例过高,标记淘汰)。
自动注入:下次有 Agent 遇到类似场景时,seekdb M0 会在对话开始前检索相关经验,和记忆一起注入上下文。Agent 不需要主动去「查经验」,相关经验会自动出现在它的视野里。
反馈闭环:Agent 在对话中被注入了某条经验后,本轮对话的执行结果(成功或失败)会作为反馈信号自动上报。成功的执行驱动经验晋升,反复失败的执行让低质量经验被淘汰。
这套机制的关键在于:经验中不包含原始对话内容,只保留蒸馏后的通用知识。一个用户的隐私信息不会通过经验系统泄露给其他用户。隔离是共享的前提。

一句话安装
OpenClaw 的哲学是「让 Agent 自己干」,seekdb M0 的安装也遵循这个原则。你只需要对自己的 Agent 说一句话:
阅读 https://m0.seekdb.ai/SKILL.md 并按说明安装与配置 m0。Agent 读取这份文档后,会自主完成全流程:检测 OpenClaw 版本 → 获取 Access Key → 下载插件源码 → 写入 openclaw.json 配置 → 重启 Gateway。全程无需用户手动操作。
人类开发者也可以用更直接的方式验证服务:
# 确认服务正常curl -s https://m0.seekdb.ai/health# 创建记忆实例curl -s -X POST https://m0.seekdb.ai/api/instances/ \-H "Content-Type: application/json" \-d '{"name": "my-memory"}'
返回的 ak 字段就是你的 Access Key,之后所有记忆操作都通过这个 Key 认证。

动手试一试
告诉 Agent 一些关于你的事情:
我叫李明,是一名前端工程师,在上海工作。我喜欢 TypeScript 和 React,讨厌写 CSS。周末喜欢打羽毛球。
对话结束后,seekdb M0 会自动提取出 5-6 条事实,经过记忆决策后存入云端。
开一个新 session,测试召回:
帮我写一个组件你没有指定技术栈,但 M0 已自动检索到你的技术偏好,Agent 会主动提及「技术栈是 React + TypeScript 吗?」——而不是从零问起。它已经知道你是谁了。
再看看经验的效果:
假设之前有其他 OpenClaw 用户的 Agent 在排障过程中总结出了一条经验——「当服务返回 connection refused 但数据库进程正常时,优先检查连接池是否被慢查询耗尽,而不是反复重启服务」。这条经验经过多次验证后被发布到公开池。
现在你的 Agent 遇到了类似的 503 报错,seekdb M0 在对话开始前自动检索到了这条经验并注入上下文。你的 Agent 不会再花二十分钟反复重启,而是直接去检查慢查询——五分钟内解决问题。

写在最后
最后官宣一下:seekdb M0 今天正式上线了。
回到最初的问题:为什么你的 OpenClaw 会记忆退化?因为它的记忆依赖 MEMORY.md 全量加载和被动的搜索检索。MEMORY.md 越写越大,上下文越来越挤;历史记忆散落在memory/文件中,Agent 需要主动搜索才能想起来,但它不一定知道该搜什么。记得多了会贵,记得少了会忘。这是本地记忆架构的固有局限,不是配置能解决的。
seekdb M0 选择的路是:把记忆从上下文中解放出来——独立存储、按需检索、跨 session 持久化。不再全量加载,而是在对的时间想起对的事情。
更让我兴奋的是经验系统。OpenClaw 社区每天有大量 Agent 在日常工作中积累实践经验,但这些经验是孤立的——每个 Agent 都在独立试错。
OpenClaw Agent 有了 skill,就像毕业生有了专业知识。但真正让它们成为专家的,是经验。而和人类不同的是,Agent 之间可以直接共享大脑。
这是 seekdb M0 真正想做的事。
👉相关链接:
seekdb M0 云端记忆服务:https://m0.seekdb.ai
PowerMem 开源项目:https://github.com/oceanbase/powermem
seekdb D0 体验入口:https://d0.seekdb.ai
