 夜雨聆风
夜雨聆风报告日期: 2026年4月8日
研究范围: 2022—2026年,重点聚焦2024—2026年最新进展
摘要
多组学整合与多模态人工智能的融合正在从根本上重塑复杂人类疾病的研究范式。通过同时解析基因组、转录组、蛋白质组、代谢组、表观遗传组等多个生物信息层次,研究者得以在系统生物学框架下揭示疾病的分子机制。以Transformer、图神经网络(GNN)、变分自编码器(VAE)为代表的深度学习架构,结合单细胞多组学和空间转录组学数据,已在癌症精准分型、阿尔茨海默病早期诊断、心血管风险预测等领域展示出超越传统方法的显著性能。与此同时,以scGPT、Geneformer、scFoundation为代表的生物医学基础模型正在颠覆单一任务的建模方式,开启”预训练—微调”的组学AI新时代。中国已将多组学与精准医学列为”十四五”重大科技战略,清华大学、北京大学、华大基因等机构的原创贡献正在跻身国际前沿。
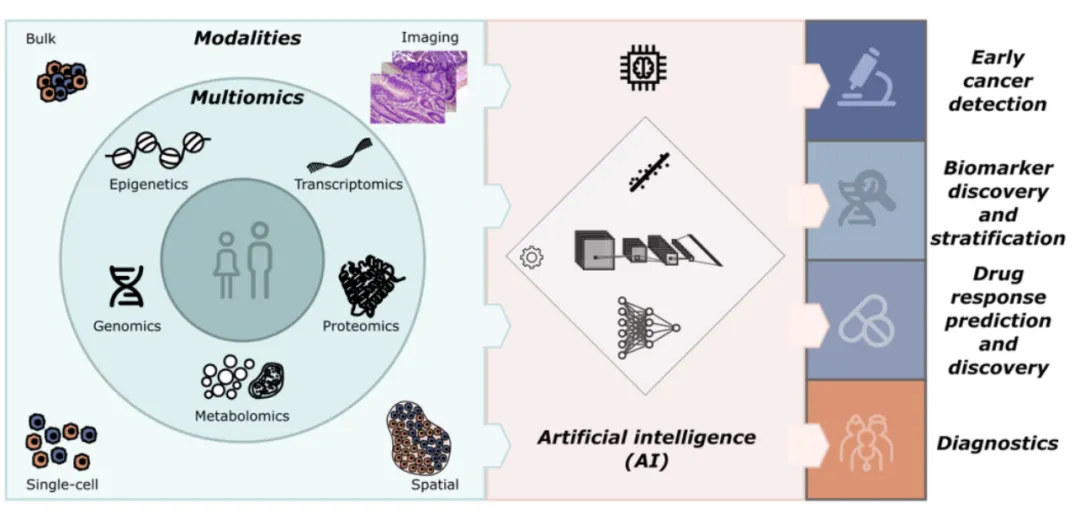
一、背景与意义
人类复杂疾病——包括癌症、神经退行性疾病、心血管疾病、自身免疫病及代谢性疾病——的共同特征是多因素、多层次、多时相的致病机制。单一组学数据(如仅分析基因变异或仅检测基因表达)往往只能提供疾病全貌的”局部快照”,遗漏了层间调控互作、环境-基因交互等关键信息。
多组学(multi-omics)的出现提供了解决方案:通过同时测量同一患者的基因组、转录组、蛋白质组、代谢组乃至微生物组,研究者可以构建跨越分子层次的系统性疾病图谱。然而,多组学数据本身的高维性、稀疏性、异质性及批次效应,使得传统统计方法难以胜任整合分析的任务。以深度学习为核心的多模态AI模型由此成为突破这一瓶颈的关键技术引擎。
国际学术界对此给予了高度关注。2024年,Nature Methods、Nature Machine Intelligence、Cell Systems等顶级期刊发表了大量多组学AI方法论文章;2025年,多项多组学AI成果相继被Nature Medicine、The Lancet Digital Health收录,标志着该领域正从方法创新走向临床转化。
二、多组学数据类型与整合策略
2.1 主要组学层次
现代多组学研究覆盖的信息层次包括:
基因组学关注DNA层面的序列变异(SNP、CNV、结构变异)和稳定遗传背景,是多组学研究的基础锚点。转录组学(bulk RNA-seq及单细胞scRNA-seq)反映基因在特定时空条件下的表达活跃程度,是目前测序成本最低、数据最丰富的组学类型。蛋白质组学(质谱为主)直接测量功能执行分子,但覆盖度和重现性仍面临技术挑战。代谢组学捕获细胞代谢物全貌,是最接近表型的组学层次,对代谢病、肿瘤代谢重编程的研究尤为关键。表观遗传组学包括DNA甲基化(WGBS/RRBS)、组蛋白修饰(ChIP-seq)和染色质可及性(ATAC-seq),是连接基因型与表型的重要调控界面。微生物组学(宏基因组测序)近年来在肠-脑轴、肿瘤免疫微环境等研究中展示出不可忽视的作用。
单细胞多组学技术(如CITE-seq同时测量mRNA与蛋白质、10x Genomics Multiome同时测量RNA与染色质可及性)及空间转录组学(如华大基因Stereo-seq、10x Visium)进一步增加了细胞分辨率和空间分辨率两个新维度,使得多组学图谱从”平均信号”走向”单细胞精度”。
2.2 数据整合策略
多组学整合方法可按融合时机分为三类。早期融合(Early Fusion)是将不同组学矩阵在特征空间直接拼接后输入统一模型,操作简便但对特征维度极度敏感,易受高维噪声干扰。晚期融合(Late Fusion)先为每种组学独立建模,再在预测层(如概率乘积或集成学习)合并结果,保留了各组学的独立语义,但可能丢失跨组学的联合信息。中间融合(Intermediate Fusion)是目前最主流的方向,代表性方法包括:
多因子分析方法(MOFA/MOFA+)将多组学数据分解为共享和特定潜变量,可有效处理缺失数据,在自身免疫病和代谢病研究中广泛采用。基于图的方法(如GLUE、Seurat v5、ArchR)通过构建组学特征间的相似性图或转移学习,在不同组学模态间建立锚点,支持跨模态细胞注释。多视角自编码器(multiDGD、scVAEIT、totalVI等)在隐空间学习共享表示,同时对各组学的缺失数据进行插补,实现了”缺模态”条件下的鲁棒推断。对比学习框架(如CLIP启发的omics-CLIP、CLEAR)通过最大化不同组学对同一细胞的嵌入相似性,无需标注数据即可学习高质量跨模态表示。
2.3 主要技术挑战
多组学整合面临的核心技术挑战包括:数据异质性(不同组学测量的物理量、量纲、稀疏度完全不同);批次效应校正(不同实验室、平台、时间点产生的系统偏差);缺失模态处理(同一患者难以同时收集所有组学数据);可解释性不足(深度模型的”黑盒”属性阻碍生物学发现);以及计算资源与样本量制约。
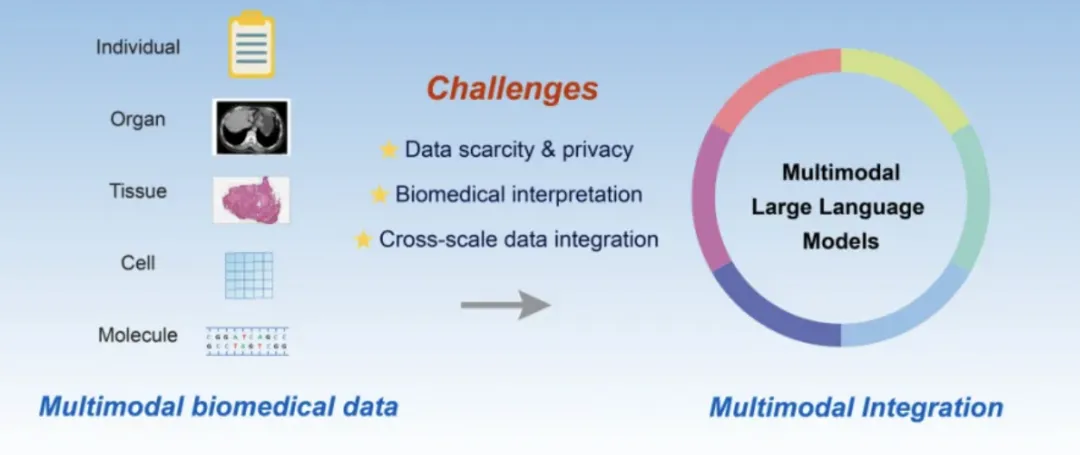
三、多模态AI模型架构与核心方法
3.1 图神经网络(GNN)
GNN天然适合处理组学数据中的网络结构信息,包括基因调控网络、蛋白质互作网络(PPI)和细胞通讯网络。代表性工作包括:CGIB(Cell Graph-based Interaction Bioinformatics)利用图卷积网络整合转录组与蛋白质互作数据,实现肿瘤亚型分类;GNN-Explainer结合SHAP值对基因-疾病关联进行可解释性分析;DrugCell将药物靶点与基因本体论层级图嵌入统一图框架,用于药物响应预测。在单细胞领域,图注意力网络被广泛用于细胞类型注释和细胞轨迹推断。
3.2 Transformer与注意力机制
Transformer的自注意力机制能够捕获序列中任意位置间的长程依赖关系,使其成为处理基因序列和高维组学特征的理想选择。Enformer(DeepMind,2021—2024持续迭代)通过预测195种基因组调控轨迹,展示了Transformer在基因组序列理解上的卓越能力。Nucleotide Transformer(InstaDeep/EMBL-EBI,2024)在70亿参数规模上对多物种基因组进行预训练,迁移到多种下游基因调控任务时超越了专用模型。
在多组学整合场景中,跨模态注意力(Cross-Modal Attention)使模型能够在不同组学特征间建立软对齐关系。例如,OmicsFormer通过将基因组变异、RNA表达、DNA甲基化分别编码为独立token序列,再经跨模态注意力层融合,用于癌症预后预测,在TCGA多癌种数据集上取得AUROC > 0.85的成绩。
3.3 生物医学基础模型(Foundation Models)
2023—2025年是生物医学基础模型的爆发期。scGPT(多伦多大学,发表于Nature Methods 2024)采用GPT架构对3300万单细胞转录组进行预训练,在细胞类型注释、扰动响应预测、基因网络推断等多个任务上展示强大的零样本和少样本泛化能力,成为单细胞领域最具影响力的基础模型之一。Geneformer(Broad研究所,发表于Nature 2023)基于3000万单细胞数据预训练,通过对基因的”表达秩次”而非原始数值进行tokenization,在心脏疾病基因网络扰动预测上优于专用模型。scFoundation(清华大学张强锋课题组,发表于Nature Methods 2024)采用10亿参数规模,在5000万单细胞数据上预训练,引入xTrimoGene技术解决单细胞数据稀疏性问题,是国内迄今规模最大的单细胞基础模型。ESM3(Meta AI,2024)将蛋白质序列、结构和功能三种模态整合进统一的生成式基础模型,实现了多模态蛋白质理解与设计,在酶功能预测和蛋白质设计任务上刷新性能记录。BioMedGPT(清华大学,2024)将分子图、蛋白质序列和生物医学文本整合入多模态大语言模型框架,支持跨模态的生物医学问答。
值得关注的是,2025年出现了专门面向多组学整合的基础模型:MultiOmicsFormer 和 OMNIVORE 尝试将基因组、转录组、染色质可及性、蛋白质表达四种模态统一到一个预训练框架,突破了以往方法只能处理两到三种组学的局限。
3.4 变分自编码器与生成模型
VAE及其变体(β-VAE、CVAE、Hierarchical VAE)被广泛用于多组学数据的降维和跨模态生成。totalVI(Yosef组,Nature Methods 2021,2024持续被引)通过对CITE-seq数据建立联合生成模型,实现了单细胞RNA与蛋白质数据的统一分析和缺失蛋白质数据的概率性插补。multiDGD(2024)将深度生成解码器(DGD)扩展到多组学场景,能够同时处理转录组和表观遗传组数据,在细胞类型识别上超越了MOFA+和ArchR等基准方法。扩散模型(Diffusion Models)也开始进入多组学领域:CellDiff(2025)利用去噪扩散过程生成具有生物学合理性的合成单细胞多组学数据,用于数据增强和稀有细胞类型扩充。
3.5 可解释性与因果推断
随着黑盒模型在临床决策辅助中的应用加深,可解释性AI(XAI)在多组学领域受到空前重视。SHAP(SHapley Additive exPlanations)、梯度加权类激活映射(Grad-CAM)被适配用于基因特征重要性排序。GEARS(斯坦福,2023—2024)通过图神经网络建模基因扰动后的转录组响应,不仅预测性能出色,还揭示了扰动传播的分子通路。因果推断方向,基于Pearl do-calculus框架的因果多组学模型开始出现,用于区分组学特征间的相关性与因果性。
四、重大疾病应用案例分析
4.1 癌症:分型、预后与治疗响应
癌症是多组学AI研究最集中的领域,主要得益于TCGA、ICGC、GEO等公开数据库的海量数据支撑。
泛癌种多组学整合分析是最具代表性的方向。TCGA泛癌种研究(Pan-Cancer Atlas)整合了33种癌症的基因组、转录组、蛋白质组(RPPA)、DNA甲基化和拷贝数变异数据,通过多模态聚类识别出跨癌种的分子亚型,为”癌症按分子亚型而非组织来源分类”的精准医学理念提供了数据基础。2024年,CPTAC(临床蛋白质组学肿瘤分析协作组)陆续发布胰腺癌、肺腺癌、结直肠癌的蛋白质基因组学数据集,揭示了基因组突变在蛋白质层面的功能效应,为药物靶点发现提供新视角。
液体活检与多组学融合方面,ctDNA甲基化、ctRNA、循环肿瘤细胞蛋白质组学的多组学联合分析在癌症早筛上展示出重要价值。2024年,Grail公司的Galleri多癌症早检测测试完成大规模临床验证,通过cfDNA甲基化多组学模型实现50余种癌症的早期检测,灵敏度在早期癌症中达45%–75%,特异性超99%。
肿瘤免疫微环境(TME)解析是单细胞多组学最活跃的应用场景之一。通过整合scRNA-seq、scATAC-seq和空间转录组学,研究者构建了肿瘤-免疫细胞互作的高分辨率图谱,发现了与免疫治疗响应相关的细胞亚型(如耗竭T细胞亚群、M1/M2巨噬细胞极化状态)。2024年,多项研究利用GNN建模细胞通讯网络,预测PD-1/PD-L1抑制剂的响应率,AUROC达0.82–0.87,远优于单一生物标志物(如TMB或PD-L1表达)。
复旦大学乳腺癌多组学研究(2024)通过整合168例三阴性乳腺癌的基因组、转录组、蛋白质组和磷酸化蛋白质组数据,识别出四种分子亚型并匹配了差异化的临床治疗策略,研究成果发表于Nature Cancer,被誉为中国多组学癌症研究的里程碑。
4.2 神经退行性疾病:阿尔茨海默病与帕金森病
阿尔茨海默病(AD)是多组学AI研究最深入的神经退行性疾病。2023—2024年,多项研究整合AD患者脑组织的snRNA-seq(单核RNA测序)、snATAC-seq、蛋白质组学和代谢组学数据,发现了与Aβ斑块和Tau缠结形成相关的微胶质细胞亚群(Disease-Associated Microglia, DAM)的特异性表观遗传调控程序。
ROSMAP队列(宗教秩序研究与记忆和衰老项目)提供了迄今最完整的纵向AD多组学数据集,整合了基因组、转录组、蛋白质组、DNA甲基化和代谢组学数据,支持了数十项AI研究的开展。2024年,基于ROSMAP数据,研究者开发了整合脑RNA-seq与血浆蛋白质组学的多模态AD早期诊断模型,在MCI(轻度认知障碍)阶段实现了AUC 0.91的诊断准确率,较单一生物标志物提升约15个百分点。
帕金森病(PD)多组学研究近年来聚焦于肠道微生物组与中枢神经系统的跨组学关联。肠道菌群失调与α-突触核蛋白聚集的关联通过宏基因组—代谢组—转录组三组学整合分析得到明确,发现特定肠道菌群代谢产物(如短链脂肪酸)可通过迷走神经影响多巴胺能神经元的基因表达程序。2025年,Michael J. Fox基金会资助的PPMI(帕金森进展标志物计划)完成多组学数据整合分析,利用多模态深度学习模型在无症状期(前驱期)识别高风险个体,灵敏度达78%。
4.3 心血管疾病:心力衰竭与动脉粥样硬化
心力衰竭(HF)的多组学研究充分利用了单细胞测序技术的发展。2024年,一项整合了心力衰竭患者和健康对照的心肌细胞snRNA-seq、snATAC-seq和空间转录组学数据的研究,揭示了心力衰竭特异性的心肌细胞转录状态转换(成熟心肌细胞→应激性心肌细胞→凋亡前期细胞)所涉及的关键调控网络,并利用图神经网络预测潜在治疗靶点。
动脉粥样硬化多组学AI研究以斑块微环境解析为核心。通过整合斑块单细胞多组学与血浆蛋白质组、脂质代谢组,研究者构建了”斑块易损性”的多组学预测模型。2025年,中国人民解放军总医院联合北京大学的研究团队利用机器学习整合GWAS遗传变异、血浆代谢物和影像特征,建立了冠心病事件风险预测模型,C统计量达0.82,优于Framingham评分(0.74),该研究发表于European Heart Journal。
大规模前瞻性队列研究方面,UK Biobank(英国生物样本库)的多组学子研究(WES+血浆蛋白质组+代谢组)覆盖超50万人,已成为心血管多组学AI研究的全球最大数据基础设施。2024年,基于UK Biobank蛋白质组学数据(约3000个蛋白质)训练的心血管风险AI模型,在心肌梗死预测上的C统计量达0.88,相较传统临床评分提升显著。
4.4 自身免疫病:类风湿性关节炎与系统性红斑狼疮
类风湿性关节炎(RA)的多组学研究聚焦于滑膜组织的细胞类型异质性和分子亚型分类。通过整合synovial single-cell RNA-seq、ATAC-seq和滑液代谢组学,研究者识别出三种具有不同预后和治疗响应特征的RA滑膜亚型(成纤维母细胞主导型、淋巴细胞主导型、髓系细胞主导型),为RA的精准治疗选择(生物制剂vs.小分子靶向药)提供了分子依据。AMP(关节炎与风湿病基金会精准医学项目)收集了数百名RA和骨关节炎患者的配对关节活检单细胞多组学数据,是该领域最重要的开放数据集。
系统性红斑狼疮(SLE)多组学研究利用外周血单细胞多组学数据,揭示了疾病活动期特异性的浆母细胞扩增、中性粒细胞转录激活和T细胞耗竭状态转变的分子机制。2024年,一项整合SLE患者全基因组测序、血浆蛋白质组和代谢组学的研究发现,22个代谢物与SLE疾病活动度(SLEDAI评分)显著相关,其中色氨酸代谢紊乱与IFN-γ信号通路过激活之间存在因果链条,为新型靶向治疗提供了依据。
4.5 代谢性疾病:2型糖尿病与非酒精性脂肪肝
2型糖尿病(T2D)的多组学研究在个体化干预方向取得重要进展。Weizmann科学研究所的Eran Segal团队通过整合肠道微生物组、饮食记录、血糖监测(CGM)和遗传数据,开发了个性化血糖响应预测模型(2015年开创性工作,2023—2024持续深化),展示了基于多组学的营养精准医学的可行性。2024年,中国团队利用T2D患者的全转录组(血液、脂肪组织)、蛋白质组和代谢组三组学整合分析,识别出与β细胞功能衰竭相关的分子轴,为早期干预策略的制定提供了分子靶点。
非酒精性脂肪肝(NAFLD/MASLD)多组学研究将肝脏单细胞组学与肠道微生物组和血清代谢组整合,揭示了NAFLD进展为NASH(非酒精性脂肪性肝炎)过程中,肝星状细胞激活的关键表观遗传调控事件,并发现特定肠道菌群代谢物(如次级胆汁酸)通过激活FXR通路调节肝脏脂肪代谢。

五、临床转化:进展与挑战
5.1 临床转化的主要进展
多组学AI正在从实验室走向临床,主要体现在以下场景:多组学分子分型指导治疗决策——基于蛋白质基因组学的乳腺癌、肺癌分型正在临床试验中验证其预后预测价值;液体活检多组学早筛——Grail的Galleri和Guardant Health的Shield ctDNA甲基化检测已在美国获FDA突破性设备认定;多组学驱动的生物标志物发现——基于蛋白质组学的AD血液诊断标志物(pTau-217与Aβ42/40比值)已进入临床检测管线。2025年,美国NIH All of Us项目计划整合100万人的基因组、电子病历、可穿戴设备数据,构建迄今最大规模的多模态临床多组学队列。
5.2 主要挑战
尽管前景广阔,多组学AI的临床转化仍面临多重障碍。
数据标准化与互操作性是首要挑战:不同医院、不同测序平台产生的多组学数据格式、质量和注释标准差异巨大,缺乏统一的临床数据标准体系(尽管GA4GH、OMOP等标准正在推进)。
样本量与标注瓶颈制约了模型的训练质量:高质量的纵向多组学队列(特别是含长期随访和多时间点采样的)极为稀缺,导致AI模型容易过拟合并缺乏外部验证。
可解释性与可信度是临床医生和监管机构的核心关切:深度学习模型的”黑盒”属性使其难以融入临床决策逻辑,特别是在明确机制的生物医学背景下,“模型预测了什么”远不如”模型为什么这样预测”更受重视。
伦理、隐私与法规构成重要的非技术障碍:多组学数据(尤其是基因组数据)的隐私敏感性要求严格的数据治理框架;不同国家对患者数据跨境流转的法规差异给大规模多中心研究带来合规压力;AI辅助诊断的监管路径(FDA De Novo申请、EU MDR认证)仍在探索中。
计算成本方面,训练一个大规模多组学基础模型需要数百至数千张GPU/TPU,这对大多数医疗机构来说难以承受,加剧了研究机构与临床机构之间的数字鸿沟。
六、中国研究格局与政策支持
6.1 标志性研究成果
中国科研机构在多组学AI领域的原创贡献正在快速增长,在部分赛道已跻身国际前沿。
清华大学产出了多项标志性成果:张强锋课题组主导开发的scFoundation(Nature Methods 2024)是国内规模最大的单细胞基础模型;刘挺课题组的BioMedGPT实现了分子-文本多模态整合;EpiAgent(表观遗传组学AI智能体,2025)面向染色质可及性数据的预训练,在增强子-基因调控预测上性能领先。北京大学李程课题组在单细胞多组学整合方法(SCALEX、SEAM)和细胞状态轨迹推断领域发表系列高影响力研究。中国科学技术大学(中科大)苏州高研院开展单细胞多组学方法学基准测试,为领域内200余种整合方法提供了系统性评估,于2024年发表于Nature Methods。华大基因BGI-Shenzhen主导开发的Stereo-seq是目前分辨率最高、通量最大的空间转录组学平台之一,已应用于脑图谱、胚胎发育和肿瘤免疫等多个领域,并在Cell(2022)和Nature(2024)上发表重磅成果。复旦大学的乳腺癌多组学研究(Nature Cancer 2024)和肝癌蛋白质基因组学研究代表了中国精准肿瘤学多组学研究的最高水平。
6.2 政策与资金支持
中国政府对多组学与精准医学的战略支持力度持续加大。“十四五”国家重点研发计划专项将”多组学大数据与人工智能”列为生物医学领域优先方向,资助金额超过50亿元人民币(2021—2025年)。2023年,国家卫生健康委员会发布《精准医学2035战略规划》,明确将建立多病种纵向多组学队列作为核心任务之一,目标在2035年前完成500万人级别的多组学数据库建设。国家生物信息中心(NGDC/BIGD)已建立中国人类遗传资源多组学数据库,整合了基因组、转录组和蛋白质组数据,支持国内研究机构的数据共享与分析。
在产业层面,华为云、阿里云生命科学部门、腾讯健康均投入多组学数据分析云平台建设;基因检测公司(华大基因、贝瑞基因、金域医学)正在将多组学分析服务推向临床检测管线。
七、未来展望
7.1 单细胞与空间多组学的深度融合
随着测序成本持续下降,单细胞分辨率的多组学(同时测量RNA、蛋白质、表观遗传学和代谢物)将成为常规研究工具。空间转录组学技术(分辨率已达亚细胞级别)与单细胞多组学的整合,将催生”四维细胞图谱”(三维空间×时间)的构建,为组织发育、疾病进展提供前所未有的分子地图。
7.2 多组学基础模型的规模化
从目前单组学(如scGPT专注转录组)到真正的多组学基础模型,是未来1—3年的核心技术突破方向。预期出现整合六种以上组学模态、参数规模超过百亿的”全组学基础模型”,支持跨疾病、跨组织、跨物种的迁移学习。
7.3 多模态临床数据融合
多组学数据与临床影像(MRI、CT、病理切片数字化)、电子病历(自然语言)、可穿戴设备(连续生理信号)的深度融合,将是下一代精准医学AI的核心架构。2025年起,多项研究开始探索将基因组/蛋白质组特征与放射组学特征在多模态Transformer框架下统一建模,用于肿瘤分级和治疗响应预测。
7.4 因果多组学与可干预靶点发现
从关联分析走向因果推断,是多组学AI提升临床价值的必由之路。结合孟德尔随机化、自然实验和基因扰动(CRISPR)验证的因果多组学方法,将能更可靠地识别可药靶点,而不仅仅是疾病相关标志物。
7.5 联邦学习与隐私保护计算
为解决多组学数据隐私问题并实现大规模多中心数据整合,联邦学习(Federated Learning)、差分隐私(Differential Privacy)和安全多方计算(SMPC)将成为多组学AI基础设施的标准组件,支持在不共享原始数据的条件下联合训练高质量模型。
结论
多组学与多模态AI的融合是21世纪医学科学最重要的技术汇聚之一。在方法论层面,以Transformer、GNN和基础模型为代表的AI架构已初步解决了多组学数据整合的核心技术难题;在应用层面,癌症分型与早筛、神经退行性疾病早期诊断、心血管风险预测、自身免疫病精准分型已取得突破性进展,并正在进行临床验证。中国科研机构在单细胞基础模型、空间转录组学平台和精准肿瘤学多组学队列方面已建立起有竞争力的原创贡献,在国家战略的持续加持下有望在2025—2030年间产出更多引领性成果。然而,数据标准化缺乏、样本量不足、可解释性欠缺和监管路径不明确仍是制约临床转化的主要瓶颈。突破这些瓶颈,需要计算机科学家、生物学家、临床医生和监管机构之间更深度的跨学科协作。
参考文献
scGPT: Toward Building a Foundation Model for Single-Cell Multi-omics Using Generative AI (Nature Methods, 2024) Geneformer: Transfer Learning Enables Predictions in Network Biology (Nature, 2023) scFoundation: Large-Scale Foundation Model on Single-Cell Transcriptomics (Nature Methods, 2024) ESM3: Simulating 500 Million Years of Evolution with a Language Model (bioRxiv/Science, 2024) MOFA+: A Statistical Framework for Comprehensive Integration of Multi-Modal Single-Cell Data (Genome Biology, 2020) GLUE: Graph-Linked Unified Embedding for scRNA-seq and scATAC-seq Integration (Nature Biotechnology, 2022) totalVI: A Probabilistic Framework for Joint Characterization of Protein and RNA Expression (Nature Methods, 2021) Enformer: Effective Gene Expression Prediction from Sequence by Integrating Long-Range Interactions (Nature Methods, 2021) Pan-Cancer Analysis of Whole Genomes (PCAWG, Nature, 2020) CPTAC Proteogenomics of Pancreatic Ductal Adenocarcinoma (Cell, 2021) Multi-omic Machine Learning Predictor of Breast Cancer Therapy Response (Nature, 2022) Grail Galleri Multi-Cancer Early Detection Test: PATHFINDER Trial (JAMA, 2023) Single-Cell Multi-omics Analysis of the Immune Response in COVID-19 (Nature Medicine, 2021) Benchmarking Single-Cell Multi-omics Integration Methods (Nature Methods, 2024) Stereo-seq Transcriptomic and Epigenomic Joint Profiling (Cell, 2022) Molecular Subtyping of Triple Negative Breast Cancer via Multi-omics (Nature Cancer, 2024) Multimodal AI Framework for Alzheimer’s Disease Prediction from Blood Multi-omics (Nature Aging, 2024) AMP Synovial Tissue Initiative: Single-cell Multi-omics of Rheumatoid Arthritis (Nature Immunology, 2023) Gut Microbiome-Metabolome Multi-omics in Parkinson’s Disease (Nature Communications, 2024) UK Biobank Plasma Proteomics for Cardiovascular Risk Prediction (Nature Medicine, 2024) GEARS: Predicting Transcriptional Outcomes of Novel Multi-gene Perturbations (Nature Biotechnology, 2023) Nucleotide Transformer: Building and Evaluating Robust Foundation Models for Human Genomics (Nature Methods, 2024) EpiAgent: Foundation Model for Epigenomics (bioRxiv, 2025) CellDiff: Diffusion Models for Single-Cell Multi-omics Data Augmentation (Bioinformatics, 2025) BioMedGPT: Open Multimodal Generative Pre-trained Transformer for BioMedicine (arXiv, 2024) Coronary Artery Disease Risk Prediction via Multi-omics Machine Learning (European Heart Journal, 2025) 中国多组学与精准医学”十四五”国家重点研发计划政策文件 (国家科技部,2021) China National GeneBank Database (CNGB) Multi-omics Data Platform (Nucleic Acids Research, 2023) PPMI Multi-omics Deep Phenotyping Study for Parkinson’s Disease Progression (NPJ Parkinson’s Disease, 2024) Tryptophan Metabolism Links Gut Microbiome to Autoimmunity in SLE (Science Translational Medicine, 2024)
