 夜雨聆风
夜雨聆风hi,我是超级个体实践者周知,
我们知道的东西很多。但知道的东西之间,没有连线。
这就是2026年被低估的认知危机——
你的信息资产在膨胀,你的认知净值在缩水。
先说清楚:什么是"认知净值"
财务净值的公式你肯定熟:资产 - 负债 = 净值。
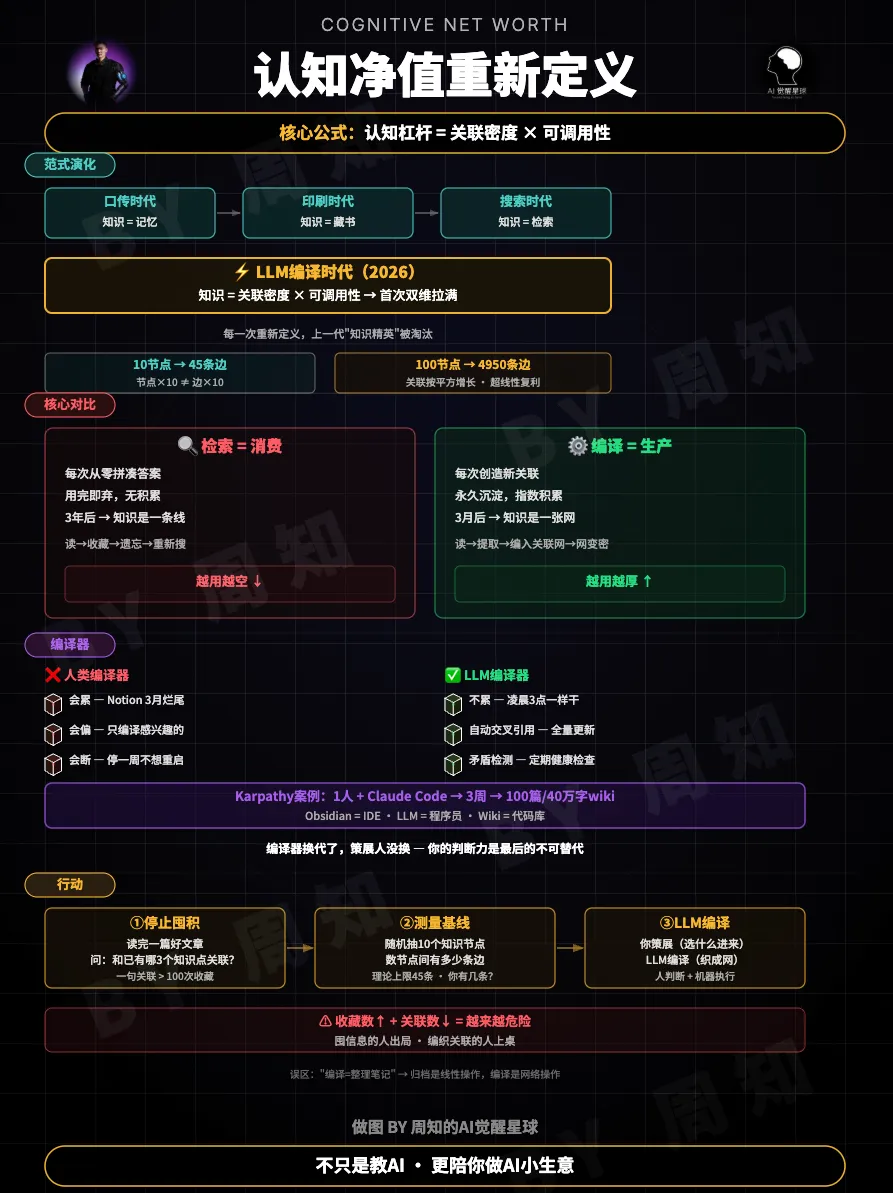
认知也有净值。只不过算法不一样。
认知净值 = 关联密度 × 可调用性。
关联密度:你脑子里(或者你的知识系统里)的知识点之间,有多少条连线?A和B之间的因果关系你知道吗?C和D之间的矛盾你标记过吗?
可调用性:需要的时候,你能在30秒内找到并使用这条关联吗?
一个数学直觉帮你感受一下这件事的量级。10个知识节点之间,最多45条连线。100个节点,4950条。节点翻了10倍,连线翻了100倍。
知识的价值增长从来不是线性的。它跟着关联数走,按平方增长。
这意味着什么?
意味着你辛苦积攒的那些孤立信息——收藏的文章、听完的课、标注的笔记——如果它们之间没有连线,它们的认知净值趋近于零。
像一堆散落的珍珠。每颗都值钱。但没有线串起来,就不是项链。卖不出项链的价。
为什么你的认知净值一直在缩水
过去10年,整个互联网都在教你一件事:获取更多信息。
订阅更多公众号。听更多播客。刷更多短视频。"终身学习"变成了一个不容置疑的政治正确。
没有人告诉你:获取信息和积累认知是两件事。
获取信息是往仓库里搬箱子。积累认知是把箱子里的零件组装成机器。
搬了1000个箱子但一台机器都没组装出来的人,仓库越大越焦虑——因为他隐约知道这堆东西"应该有用",但就是用不起来。
这就是今天大部分知识工作者的状态。
Notion里几百个页面。微信收藏夹塞满了"以后再看"。浏览器书签栏三行放不下。
认知净值?接近零。扎心,但真的。
因为这些信息之间没有一条连线。它们是散装的。问你一个需要交叉调用的问题,你得从头搜。搜到了还不确定几篇之间是什么关系。
搜索是临时工。编译才是正式员工。
Karpathy给了一个答案
2026年4月,Karpathy(OpenAI联合创始人)发了一条推文,几天超过1200万人看。
他说他最近把大量时间花在一件事上:用LLM搭个人知识库。
他的做法:把原始素材(论文、文章、代码、图片)扔进一个raw/文件夹,然后让LLM"编译"出一个结构化的markdown wiki——100篇文章,40万字,交叉引用,自动维护。
关键词是"编译"。
他精确描述了传统方式的问题——大部分AI知识工具都是RAG模式,上传文档、检索片段、拼凑回答。能用,但LLM每次都从零开始发现知识,没有积累。
而他的wiki不一样。每次加入新素材,LLM会读完它、提取核心、更新所有相关页面的交叉引用、标注矛盾、补充缺失的概念页。
知识被编译了一次,然后持续保鲜。不用每次从头拼。
同样40万字的素材,扔进RAG问一个跨5篇文档的复合问题,答案勉强能看。用编译过的wiki问同一个问题,答案质量差一个量级。
差距就在关联密度。RAG存的是散装信息。Wiki编译的是关联网络。
编译器换代了
你可能想说:编译比检索好,这不是常识吗?百科全书就是编译产物。教科书就是编译产物。
对。人类知道编译好已经几千年了。谁都知道。
问题从来不是"要不要编译"。是"谁来编译"。
人类是一个很差劲的编译器。
三个致命缺陷。别问我怎么知道的,全踩过。
会累。 Notion用了3个月开始烂尾。Obsidian半年后标签体系崩溃。每一代笔记工具都死于维护疲劳。
会偏。 你只编译感兴趣的部分。交叉引用需要同时记住两篇文章的细节,工作记忆塞不下。
会断。 忙几天就停更。停一周重启成本高到你宁愿从头来。
LLM编译器解决了这三个问题。
不累。100篇文档逐篇处理,凌晨3点一样干。交叉引用自动化——你加一篇新素材,它自动找到wiki里所有相关页面做更新。矛盾检测——定期扫描哪些数据互相打架,哪些声明被新来源推翻了。
Karpathy一个人加Claude Code,3周建起40万字的研究wiki。
重点不是快。重点是这个编译器永远在线,永远不烂尾,而且越用关联越密。
他的描述很精准——Obsidian是IDE,LLM是程序员,wiki是代码库。你不写wiki,你探索和提问。LLM负责维护。
但有一件事LLM做不了:决定什么值得编译。
选什么进系统,这是你的判断力。LLM编译、组织、维护。你策展。
编译器换代了。策展人没换。
怎么提升你的认知净值
说到这里,行动路径已经清楚了。
第一步:停止囤积,开始编译。
下次读到一篇好文章,不要按收藏键。问自己:这篇文章和我已有的哪3个知识点有关联?写下来。哪怕只是在备忘录里写一句"这篇关于XX的观点和之前看的YY是矛盾的"——这一句话的价值超过100次收藏。
第二步:测量你的关联密度基线。
打开你的笔记系统,随机抽10个知识点。数一数它们之间有多少条显性的交叉引用。10个节点理论上限是45条边。你有几条?
这个数字就是你当前的认知净值密度。大部分人会发现答案是个位数。
第三步:让LLM替你做编译。
不管你用Claude Code、Cursor还是什么工具——把你的原始素材交给LLM,让它帮你建交叉引用、标注矛盾、写概念页。你负责策展(选什么进来),LLM负责编译(把进来的东西织成网)。
我自己的做法:过去一年搭了35个skill的生态系统,每个skill是一个认知节点。它们之间的协同协议和边界声明就是节点间的边。这些边让我面对新任务时不用从零想"怎么做"——关联网络已经预编译了大量路径。
有知识积累需要高效调用的人——创业者、知识工作者、内容创作者。你已经在输入信息了,缺的是编译。
纯消费型学习者。看个乐呵的话检索够用。
"编译=整理笔记。" 不对。整理笔记是归档——把东西放进对的文件夹。编译的核心动作是创造关联——让A和B之间产生一条原本不存在的连线。你的系统没在创造交叉引用,它就还在归档。
你的收藏夹里躺着多少篇文章?
你的知识节点之间有多少条边?
第一个数字越大,第二个越小,你就越危险。
认知净值的游戏规则变了。囤信息的人出局,编织关联的人上桌。
你选哪边?
心里有念,亦能执剑。
不只是教AI,更陪你做AI小生意。
我是用AI开一人公司的周知,下回聊。
