 夜雨聆风
夜雨聆风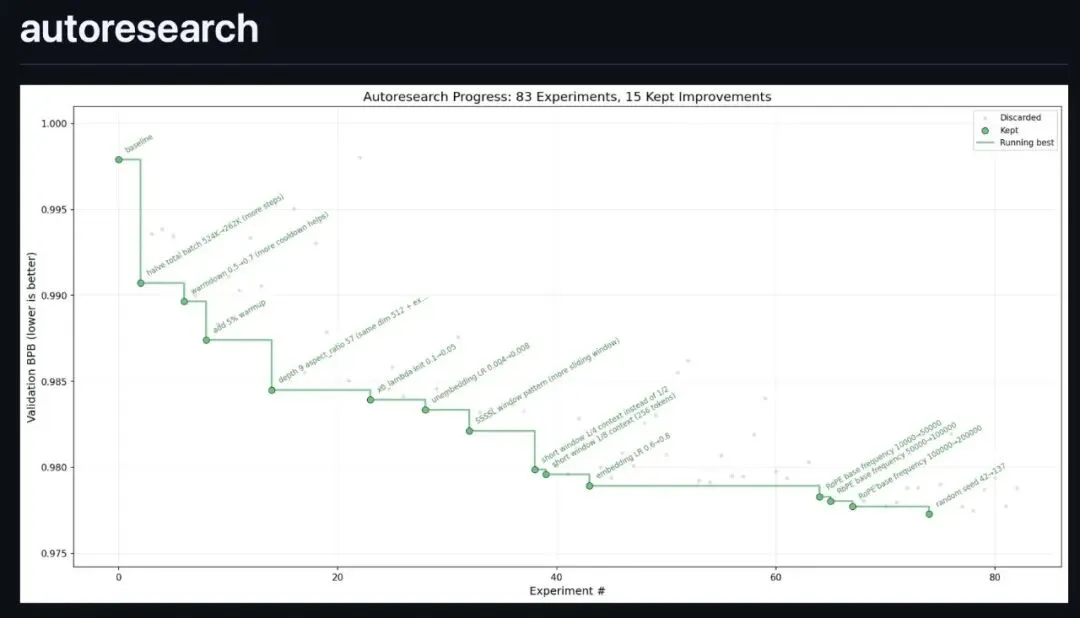
"One day, frontier AI research used to be done by meat computers in between eating, sleeping, having other fun..." —— Andrej Karpathy, 2026
2026 年 3 月,Andrej Karpathy 发布了一个名为 autoresearch 的开源项目,它标志着 AI 研究范式的一次重要转变:从人类主导的实验迭代,到 AI Agent自主进行科研探索。这个项目虽然代码量不大(核心训练代码仅 630 行),却蕴含着深刻的思想——让 AI 自己成为研究者。
一、从 Vibe Coding 到 Agentic Engineering
要理解 autoresearch 的意义,我们需要先了解 Karpathy 对 AI 开发范式的演进思考。
1.1 传统编程:人类主导一切
在传统软件开发中,程序员需要:
理解需求 设计架构 编写代码 测试调试 迭代优化
这个过程完全由人类驱动,AI 最多扮演辅助角色。
1.2 Vibe Coding:随性的人机协作
2025 年初,Karpathy 提出了 "Vibe Coding" 概念,形容那种:
人类用自然语言描述需求 AI 生成代码 人类快速验证和调整 适合原型开发和快速试错
这种方式提高了效率,但人类仍然是核心决策者。
1.3 Agentic Engineering:AI 自主研究
到了 2026 年,Karpathy 进一步提出了 "Agentic Engineering":
人类不再直接编写代码 人类定义研究目标和评估标准 AI Agent自主设计实验、修改代码、评估结果 人类只需在开始时设置规则,之后可以"睡大觉"
autoresearch 正是这一理念的实践。
二、autoresearch 的核心设计
autoresearch 的核心思想非常简单:给 AI Agent一个真实的 LLM 训练环境,让它自主实验,通过反复迭代找到最优配置。
2.1 项目架构:极简主义
整个项目只有三个核心文件:
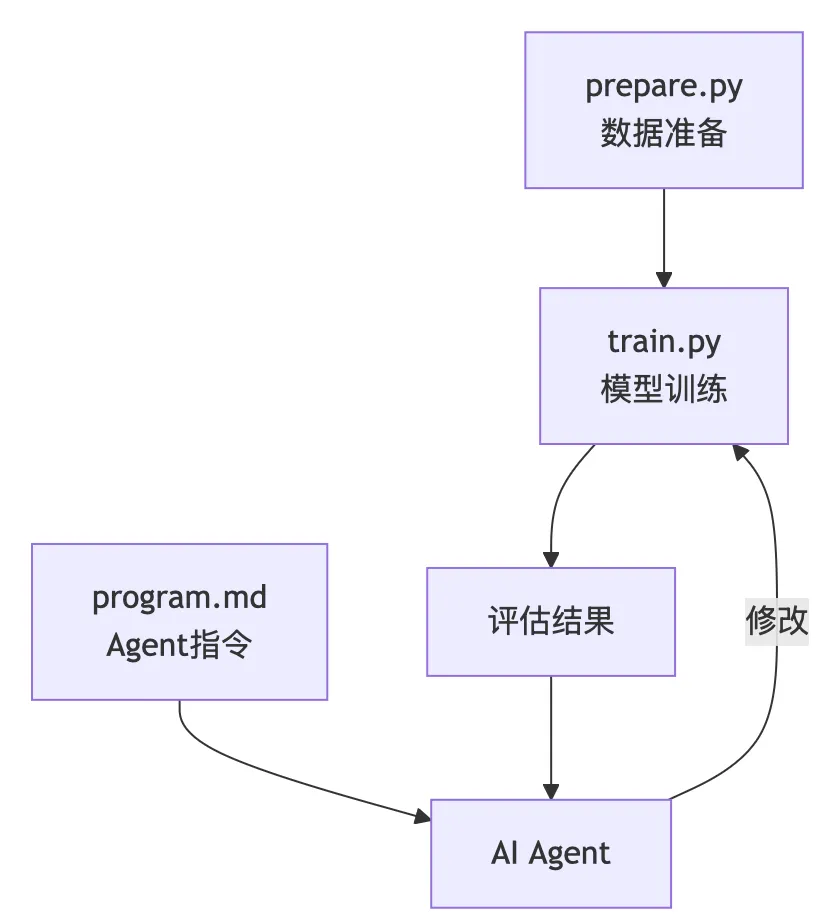
prepare.py(不可修改)
下载训练数据(ClimbMix 400B 数据集) 训练 BPE 分词器 提供数据加载器和评估函数 定义固定常量(序列长度 2048、时间预算 300 秒等)
train.py(AI Agent修改的唯一文件)
包含完整的 GPT 模型定义 优化器实现(Muon + AdamW) 训练循环 所有超参数配置
program.md(人类编写的"研究纲领")
定义 AI Agent的行为规则 设置实验流程 指定评估标准
| prepare.py | ||
| train.py | ||
| program.md |
这种设计确保了:
单文件修改:智能体只修改train.py,保持范围可控 固定时间预算:训练总是运行5分钟,便于公平比较 自包含:无需外部依赖,单GPU即可运行
2.2 固定时间预算:公平的比较基准
autoresearch 采用了一个巧妙的设计:每次训练严格限制在 5 分钟(墙钟时间,不包括启动和编译)。
这个设计有几个重要意义:
公平比较
无论模型大小、批次大小如何变化,训练时间相同 评估指标 val_bpb(验证集 bits per byte)可以直接比较 避免了"训练更久效果更好"的混淆因素
平台适配
在不同算力平台上,5 分钟能训练的 token 数不同 但每个平台都能找到该平台下的最优配置 实现了"为你的硬件定制最优模型"
实验效率
约 12 次实验/小时 一夜(8 小时)可运行约 100 次实验 快速迭代,快速收敛
2.3 自主研究循环
AI Agent的工作流程如下:
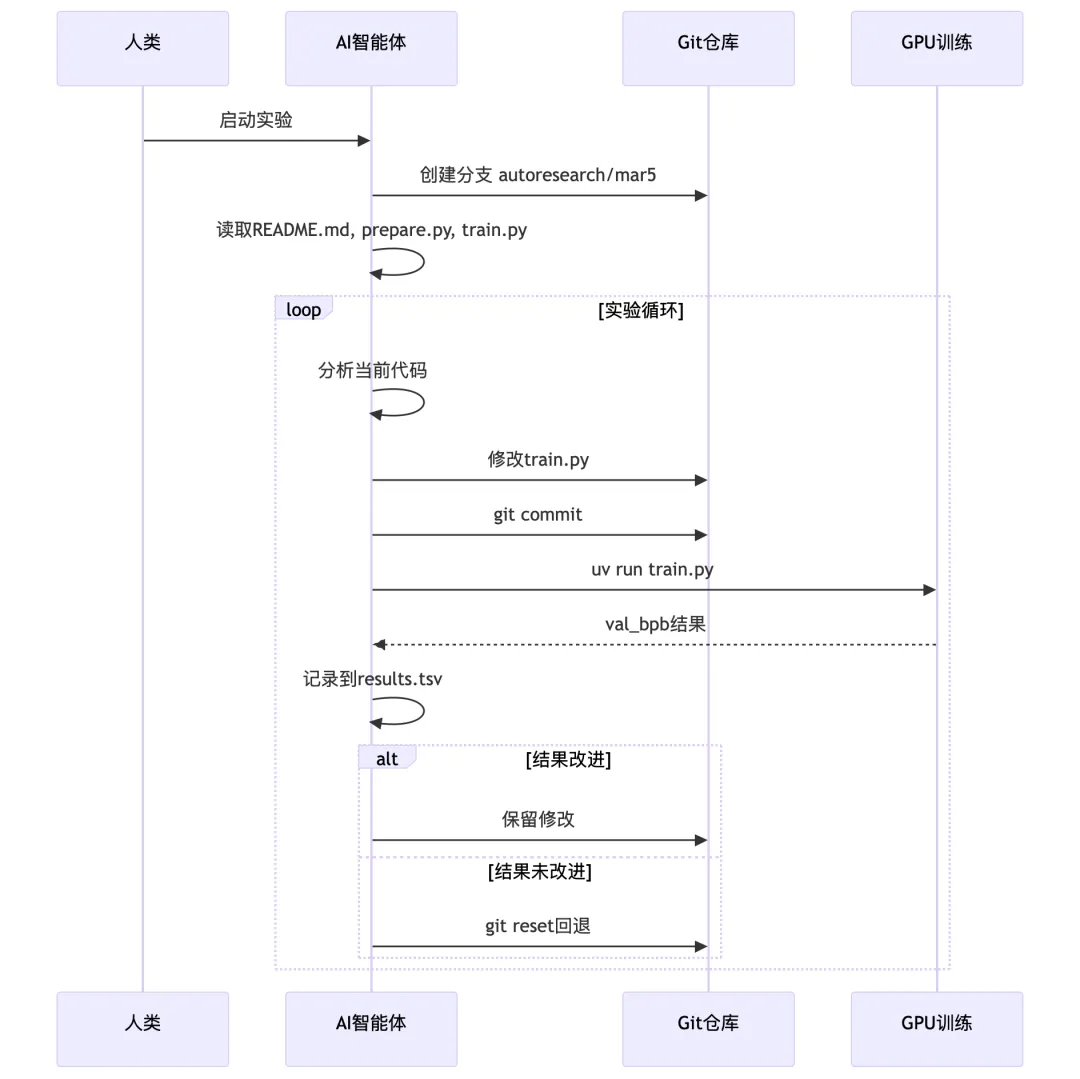
关键规则:
只修改 train.py,不动 prepare.py 不安装新依赖,只用现有库 val_bpb 降低才算成功 更简单的代码更受青睐(简约准则)
永不停止:
一旦开始,AI Agent会持续运行 不会询问人类"是否继续" 直到人类手动中断
三、技术亮点:创新架构解析
autoresearch 不仅仅是流程创新,其训练代码 train.py 也包含多项前沿技术。
3.1 Value Embedding(ResFormer)
传统 Transformer 中,每一层的注意力机制只关注当前层的输入。但在深层网络中,这可能导致注意力集中问题——后续层过度依赖前面某些层的信息。
ResFormer 通过引入 Value Embedding 解决这个问题:
# 在第一层计算 value embeddingve = self.value_embeds[str(i)](idx)# 在后续层通过残差连接混合if ve isnotNone: gate = 2 * torch.sigmoid(self.ve_gate(x[..., :32])) v = v + gate.unsqueeze(-1) * ve工作原理:
第一层的 value embedding 作为全局信息源 后续层通过可学习的门控机制混合 近似实现了跨层注意力,但计算成本更低
效果:缓解注意力集中,让信息流动更均衡。
3.2 Muon 优化器:正交化动量
autoresearch 使用了一个创新的优化器:MuonAdamW,它结合了两种优化策略:
Muon(MomentUm Orthogonalized by Newton-schulz)
传统优化器(如 Adam)将参数视为扁平向量,而 Muon 利用参数的矩阵结构:
# 对梯度进行正交化X = g.bfloat16()X = X / (X.norm(dim=(-2, -1), keepdim=True) * 1.02 + 1e-6)# Newton-Schulz 迭代for a, b, c in polar_express_coeffs[:ns_steps]: A = X.mT @ X B = b * A + c * (A @ A) X = a * X + X @ B核心思想:
将权重矩阵的更新方向正交化 强制更新在所有方向上"平衡" 防止模型过度关注某些简单模式
AdamW(用于非矩阵参数)
用于 embedding、bias、标量参数 标准的自适应学习率
组合策略:
矩阵参数(权重矩阵)→ Muon 非矩阵参数 → AdamW 不同参数组使用不同学习率
3.3 滑动窗口注意力模式
autoresearch 实现了灵活的注意力窗口模式:
WINDOW_PATTERN = "SSSL"# S=短窗口, L=长窗口工作原理:
S(Short):使用一半上下文长度(1024 tokens) L(Long):使用完整上下文长度(2048 tokens) 模式循环应用:SSSLSSSL...
优势:
减少计算复杂度(从 O(n²) 到 O(n×w)) 保留长距离依赖能力(每 4 层有 1 层全注意力) 平衡效率与性能
3.4 自适应学习率缩放
学习率根据模型维度自动调整:
dmodel_lr_scale = (model_dim / 768) ** -0.5原理:
基于"学习率 ∝ 1/√d_model"的理论 在 768 维基准上调优 自动适配不同模型大小
3.5 软上限(Softcap)输出
在 logits 输出时使用软上限:
softcap = 15logits = softcap * torch.tanh(logits / softcap)作用:
防止 logits 过大 保持梯度稳定 提高训练稳定性
四、实践指南:如何使用 autoresearch
4.1 环境准备
硬件要求:
单块 NVIDIA GPU(推荐 H100) Python 3.10+ uv[1] 包管理器
安装步骤:
# 1. 安装 uvcurl -LsSf https://astral.sh/uv/install.sh | sh# 2. 安装依赖uv sync# 3. 下载数据并训练分词器(约 2 分钟)uv run prepare.py# 4. 测试训练(约 5 分钟)uv run train.py4.2 启动自主研究
将你的 AI Agent(如 Claude、Codex)指向这个仓库,并提示:
请阅读 program.md,让我们开始新的实验!先完成设置。AI Agent会:
创建新的 git 分支(如 autoresearch/apr9) 运行基线实验 开始迭代改进 记录结果到 results.tsv
4.3 结果解读
每次实验会输出:
val_bpb: 0.997900 # 验证集 bits per byte(越低越好)training_seconds: 300.1 # 训练时间total_seconds: 325.9 # 总时间(含启动)peak_vram_mb: 45060.2 # 峰值显存mfu_percent: 39.80 # 模型 FLOPs 利用率total_tokens_M: 499.6 # 训练的 token 数num_steps: 953 # 训练步数num_params_M: 50.3 # 参数量(百万)depth: 8 # 层数核心指标:val_bpb,越低越好。
4.4 小算力平台适配
如果你没有 H100,可以调整参数:
降低模型复杂度:
减小 DEPTH(从 8 降到 4)降低 vocab_size(从 8192 降到 4096)减小 MAX_SEQ_LEN(从 2048 降到 256)
调整批次大小:
降低 TOTAL_BATCH_SIZE(保持 2 的幂次)调整 DEVICE_BATCH_SIZE
简化注意力模式:
使用 WINDOW_PATTERN = "L"(全注意力)
使用更简单的数据集:
TinyStories(GPT-4 生成的短故事) 数据熵更低,小模型也能学到东西
社区已经创建了多个分支:
autoresearch-macos:MacOS支持 autoresearch-mlx:MLX框架 autoresearch-win-rtx:Windows RTX autoresearch-amd:AMD GPU
五、总结与展望
autoresearch 是一个里程碑式的项目,它展示了 AI 自主研究的可能性。虽然目前还处于早期阶段,但它指明了一个方向:AI 不仅可以做研究助手,还可以成为研究者本身。
关键启示:
固定时间预算确保公平比较 单文件架构降低复杂度 自动化循环实现持续优化 技术创新(Muon、Value Embedding)提升性能
未来方向:
多Agent协作研究 跨领域知识迁移 自动论文撰写 开源社区共建
正如 Karpathy 在项目开头所说:"Research is now entirely the domain of autonomous swarms of AI agents running across compute cluster megastructures in the skies."
这不再是科幻,而是正在发生的现实。
参考资料
[1]uv: https://docs.astral.sh/uv/
[2]GitHub: https://github.com/karpathy/autoresearch
[3]Andrej Karpathy's AutoResearch: Automating ML with AI Agents: https://www.datacamp.com/tutorial/guide-to-autoresearch
[4]Value Residual Learning: https://arxiv.org/pdf/2410.17897
[5]Muon Optimizer文档: https://docs.nvidia.com/nemo/emerging-optimizers/0.1.0/_modules/emerging_optimizers/orthogonalized_optimizers/muon.html
[6]autoresearch-macos: https://github.com/miolini/autoresearch-macos
[7]autoresearch-mlx: https://github.com/trevin-creator/autoresearch-mlx
[8]autoresearch-win-rtx: https://github.com/jsegov/autoresearch-win-rtx
[9]autoresearch-amd: https://github.com/andyluo7/autoresearch
[10]https://karpathy.ai/
