 夜雨聆风
夜雨聆风如今,“AI改变科研”成了流行语,但对民族植物学和民族生物学研究者而言,这句话往往略显空泛。巴西学者Michelle Cristine Medeiros Jacob联合此前介绍过的学者Ulysses Paulino Albuquerque等共36名学者发表于Scientific Reports的一篇研究Prioritizing neglected food species in nutritional studies using expert-knowledge and explainable AI给大家提供了一个可操作的例子:在有限经费和人力条件下,哪些被忽视的食物物种应优先进入营养成分和膳食消费研究?其方法使用了“专家知识+可解释AI”的组合策略,这一思路完全可以迁移到民族植物学的多种议题上(方法部分略长,详见备注)。
一、先做好“人类最擅长的部分”:清单与专家打分
研究的第一步并非直接交给AI,而是组建跨学科专家团队(图1),包括植物学、真菌学、藻类学、昆虫学、鱼类学及野生脊椎动物学专家,并由数据科学家(one expert in data science)提供技术支持。团队主要完成三项工作:一是编制全国性的“被忽视食物物种清单”,严格依托系统综述、长期饮食数据、官方数据库和法规(如巴西“社会生物多样性产品”清单),并结合专家共识筛选,最大程度减少主观偏差,最终获得涵盖369种物种的清单。二是为每个物种挑选可量化特征,如地理分布(出现州数)、保护状态、野生/栽培、商业化种植情况、营养数据是否存在及相关菜谱数量等。三是邀请评审专家(见备注,与编制清单的专家不同,避免学者“又当运动员又当裁判”),在不知物种学名和俗名的前提下,仅依据上述6个特征,用1–5分量表打“成分研究优先级”和“消费研究优先级”,并标注置信度。同时,在后续建模阶段将评审专家的学科背景(如是否来自营养科学)作为模型中的解释变量,用于分析不同学科专家的决策差异。说白了,这一步就是我们平时做民族植物学研究的常规流程:列清单、定指标、请专家判断。AI做的事情并不神秘,只是把这些经验整理出来,算一算哪些因素更重要,让结果更直观。
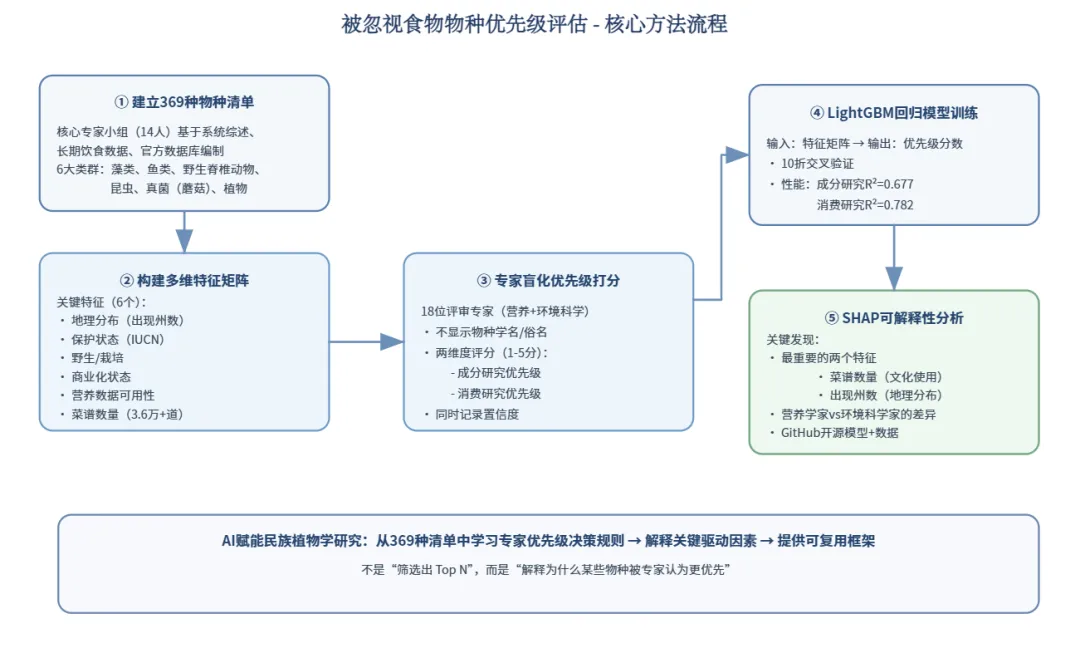
图1 被忽视食物物种优先级评估的方法流程
二、AI具体做了什么?
在获得物种特征和专家评分后,研究团队引入LightGBM(梯度提升树模型)预测优先级分数,并用SHAP(Shapley加性解释)分析模型决策过程。具体操作包括:使用10折交叉验证训练回归模型(见备注),使模型学习“哪些物种更易被专家赋予高优先级”;模型表现良好,成分研究优先级R²≈0.68,消费研究优先级R²≈0.78,说明模型捕捉到了专家决策中的稳定模式;通过SHAP分析每个特征对预测的贡献,得到可视化的“特征重要性”和“特征对优先级的影响”图谱(图2),而非黑箱分数。SHAP图结果显示,无论营养学家还是环境科学家,最重要的特征是物种相关菜谱数量和出现州数,即“被做成菜的频次”和“空间分布广度”比保护等级或类群归属更能解释专家心中的优先级。此外,模型还显示评审专家学科背景变量能够区分不同学科在优先级判断上的侧重点,从而揭示跨学科决策逻辑的差异。这并非AI自行“创新”,而是将专家分散在脑中的决策规则提炼成可讨论、可验证的证据(AI贡献还可见备注最后部分)。
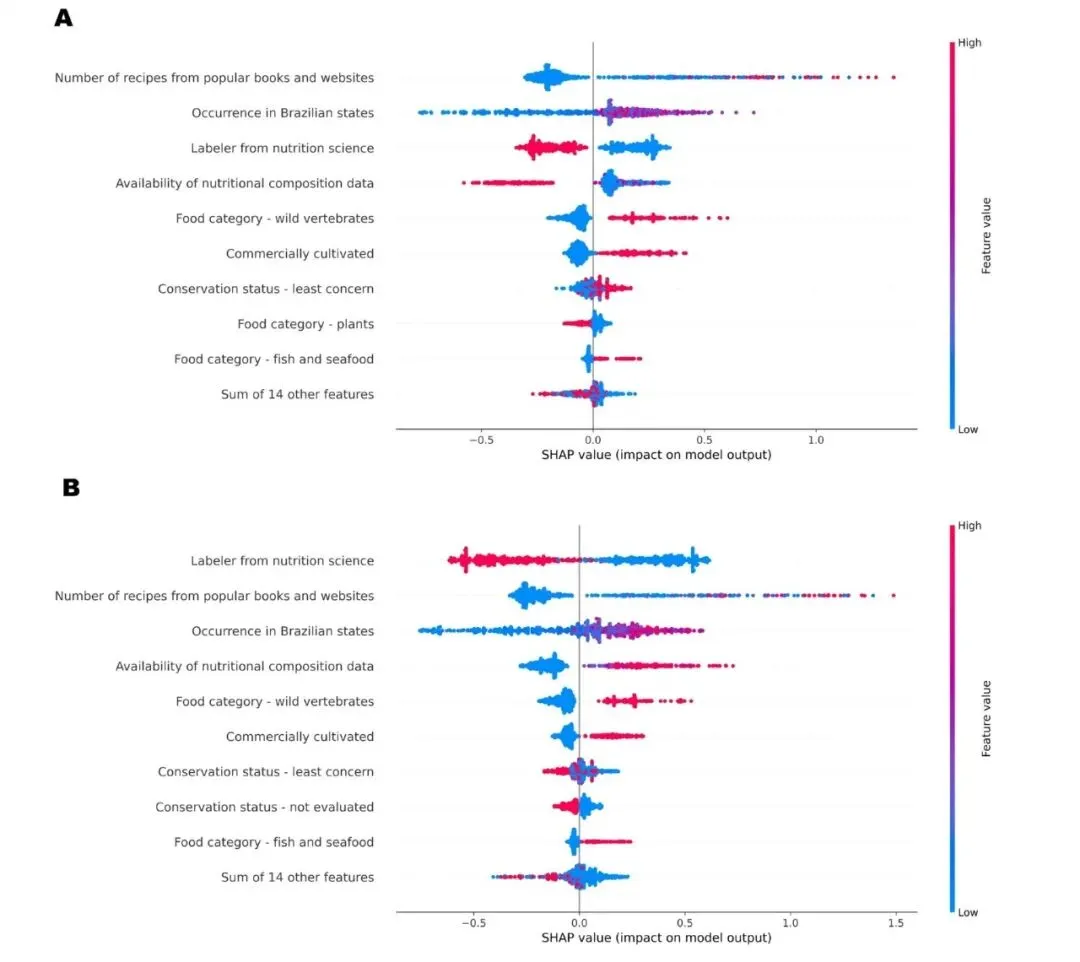
图2 用于确定物种研究优先级的因素:(A)食物成分研究;(B)食物消费研究。SHAP 值反映了各特征对模型预测优先级评分的贡献程度。
三、对民族植物学有什么启发?可以从这三步开始
方法论上,这项研究做了三件民族植物学非常需要、但传统方法难以同时完成的事情:首先,它将“文化使用”量化。研究通过3.6万余道菜谱,把物种在日常生活中的活跃度转化为可计量变量,而不是停留在“常见/罕见”的主观印象。其次,它把“多位专家的直觉”转化为可分析模型,通过机器学习与SHAP展示不同特征的边际贡献,使研究者能够清楚看到哪些因素真正影响优先级判断。第三,它利用可解释AI作为跨学科对话工具,显示营养学家与环境科学家关注重点的异同,从而为跨学科协作提供共同语言。对应到民族植物学研究中,可以将访谈、菜谱、药方、仪式记录与市场调查等资料进行结构化整理,并据此开展三个可操作步骤:一是在构建物种清单时为每个物种设计可量化特征,不仅记录“可食用/药用”,还可加入空间分布、文献或访谈出现频次、市场交易与产品化情况,以及已有营养或药理数据,为后续模型提供输入;二是组织“盲化优先级打分”,仅提供特征信息而非物种名称,让专家或社区知识持有者为优先调查、保护或推广打分,并标注置信度;三是与数据科学家合作运行可解释模型,即便是简单的树模型结合SHAP,也足以揭示不同群体判断的共性与差异,以及反复被使用的决策变量,如文化价值、药用广度、市场潜力或濒危程度。通过这种方式,AI并不会替代田野工作,而是将田野数据和专家经验转化为可复用、可比较、可与政策对接的决策工具,并显著增强“如何组织、解释与传达答案”的能力。
四、AI是民族植物学的放大镜
这项巴西研究将模型和代码开源,供其他地区针对本土被忽视物种的研究改造使用。对民族植物学研究者而言,核心启示是:只要将田野、访谈、菜谱、口述传统整理成结构化数据,AI就可成为强大放大镜——放大隐含在传统知识中的模式、不同学科和利益相关者的共识与张力,以及在政策和资源分配讨论中的话语权。与其担心“AI会取代民族植物学”,不如尽早让民族植物学成为“AI时代不可替代的数据与知识源”。这篇研究提供了清晰的起点。
备注:按“数据来源→特征构建→专家打分→机器学习与可解释性”这条主线,方法部分的具体步骤如下。
1. 研究区域与总体设计
研究以巴西为案例国,理由是:巴西是全球生物多样性最丰富的热带国家之一,但被忽视物种在居民饮食中占比极低、在国家食物成分表中严重缺失。 研究目标有两个:先建立全国性的“被忽视食物物种清单”,再基于这个清单构建一个“优先级评估框架”,预测哪些物种更应该优先进入食物成分与膳食消费研究(我个人认为这个研究非常有意思,尤其是在城市民族植物学研究中可以借鉴)。
2. 被忽视食物物种清单的建立
2.1 专家小组组成与角色
先组建一个核心专家小组(core expert panel),共 14 人,包括 13 个分物种组的专家+1个数据科学专家,覆盖6大食物类群:藻类、陆生野生脊椎动物、鱼类与海鲜、昆虫、真菌(蘑菇)、植物。 这些专家由第一作者团队基于发表记录与系统综述等工作邀请,例如有的专家刚做过对应类群的系统综述或全国清单(如野生食用菌)。 大约三分之一核心专家有与传统人群(原住民、河岸社区、手工渔民等)直接合作的经验,并且在6个食物类群中的4个类群里,至少有来自不同地区的专家,以保证全国视角。
2.2 清单构建的信息来源与“被忽视”界定
核心专家采用系统性与半系统性的资料源: 各类系统综述与综述性论文 近30年不同地区食物消费的长期数据集 官方数据库(如IBAMA)和其他正式文件 针对植物等类群,借助官方“社会生物多样性产品”清单(如MAPA/MMA 2021号联合法令),保证“被忽视物种”的界定尽量客观而非完全主观。 基于这些信息,在6个类群中编制出369种“被忽视食物物种”的全国性清单,作为后续分析基础。
3. 特征(features)选择与数据收集
3.1 特征选择
核心专家与第一作者共同确定用于刻画每个物种的特征变量,因为文献中没有现成的统一指标集合。 通过非系统性文献回顾与小组讨论,最终选定6个主要特征: 在巴西的区域分布:以“出现于多少个州”为计数(地理分布广度); - 保护现状:按IUCN九个威胁类别记录(包括未评估和数据缺乏);
- 来源:野生或栽培(origin);
- 商业化栽培状态:是否已有商业化生产(是/否);
- 营养数据可用性:无数据/有种级别数据/有属级别数据/仅有俗名数据;
- 菜谱数量:涉及该物种的菜谱总数。
3.2 菜谱数据收集
菜谱数据用于量化“文化使用”和“烹饪应用性”。 数据源包括三类: 巴西国家统计局的家庭预算调查(POF/IBGE)中记录的菜谱和饮食准备方式; 以被忽视物种或传统菜肴为主题的纸质或电子食谱书; 巴西访问量最高的三个菜谱网站中与这些物种相关的菜谱。 通过人工或半自动检索,统计每个物种出现的菜谱数量,作为一个关键特征变量(recipes)。 所有特征数据的采集时间为2023年4–10月,详尽数据源见Supplementary Information 5。
4. 专家打分:优先级与置信度
4.1 评审专家(ad hoc evaluators)的招募与构成
在核心专家之外,又招募了一组“临时评审专家”(ad hoc evaluators),要求: 背景为营养科学或环境科学; 有与至少一个被忽视食物类群相关的研究经验。 通过团队的专业网络发放标准化招募表,所有符合条件且愿意参与者均被纳入,并可作为论文共同作者。 最终共有18名评审专家:72.2%来自营养科学,27.8%来自环境科学。 营养专家中,食物成分与膳食消费方向大致各占约38%,约23%同时涉足两领域。 环境专家中60%专攻民族生物学(ethnobiology),40%兼有民族生物学与生态学背景。 文中将“是否来自营养科学”作为一个二元变量“Labeler from nutrition science”,用于比较不同学科背景的优先级模式(即在机器学习建模阶段,将评审专家学科背景作为解释变量纳入模型,以比较不同学科专家的优先级判断模式,如“Labeler from nutrition science”)。
4.2 评分流程与工具
评分前进行大约30分钟在线培训,统一任务理解;同时提供“变量词典”,详细解释每个变量和各类分类选项。 每位评审专家得到一份包含369种物种数据的表格,其中已填入前述6个特征(3.1提到的)变量。 为避免物种名带来既有偏见,表格中不显示物种的学名或俗名,只标注其所属大类(藻类、陆生野生脊椎动物、鱼、昆虫、蘑菇、植物),要求专家完全根据特征信息(即3.1提到的6个特征)来判断优先级,即为减少熟悉度带来的偏见,专家主要依据特征变量而非物种背景信息进行评分 对每个物种,专家需要在两个维度上打优先级分数(1–5的Likert量表,1=非常低,5=非常高): 该物种被纳入“营养成分研究”的重要性(composition priority); 该物种被纳入“膳食消费研究”的重要性(consumption priority)。 同时,对于每个打分,专家还要给出一个1–5的“置信度评分”,反映其对自身判断的信心,这两个置信度变量也被记录下来(后在分析中可选用)。 根据巴西伦理规范(CNS 510/2016),因不涉及个人敏感信息,且仅收集专家的“专业意见”,本研究不需要伦理委员会审批。
5. 数据分析与建模流程
5.1 描述性分析
首先对清单物种的特征做描述性统计(均值、中位数、标准差、四分位数等),以了解不同类群在分布、保护状态、商业化、营养数据可用性、菜谱数量等方面的整体模式与差异。
5.2 构建监督学习回归模型
目标:用物种特征(自变量)预测专家给出的两个优先级评分(成分研究优先级、消费研究优先级),并量化各特征的重要性。 模型类型:监督学习中的回归模型(target为连续1–5分)。
5.2.1 交叉验证
使用10折交叉验证(10‑fold cross‑validation): 将数据分成10等分; 每次用9份训练,1份验证,循环10次; 以减少对训练/验证划分偶然性的依赖,提高泛化性能估计的稳定性。
5.2.2 模型选择:LightGBM
对若干常见模型架构进行比较,最终选择 Light Gradient Boosting Machine(LightGBM)作为回归框架,因为在本数据集上其RMSE (Root Mean Squared Error,均方根误差)最低。 - LightGBM通过梯度提升树(gradient boosting decision trees)逐棵生成新树,修正前一阶段的误差,适合处理非线性特征与特征间复杂交互。
5.3 可解释性分析:SHAP
在训练最终LightGBM模型之后,引入SHAP(SHapley Additive exPlanations)来解释模型输出。 - SHAP 基于合作博弈论的Shapley值,计算每个特征对单个预测结果的边际贡献,可定量回答“这个物种的高/低优先级,是哪些特征推出来的以及推了多少”。
利用多种SHAP可视化形式: - summary beeswarm plot:展示全局特征重要性排序及高/低特征值对预测方向的影响。
- dependence & force plots等,用来分析某个特征值从低到高变化时对优先级分数的影响方向与幅度。
这样既得到“平均意义上的重要特征排序”,也能看到“在特定物种或特定子样本里,特征是如何作用的”。
5.4 实现工具与性能指标
主要使用的Python工具:Pandas(数据处理)、scikit‑learn(交叉验证、预处理等)、LightGBM包(建模)、SHAP包(解释)。 性能评估采用: - RMSE(Root Mean Squared Error)评估预测与实际专家评分的偏差大小;
- R²(决定系数)评估模型对优先级评分方差的解释比例。
最终模型在成分优先级与消费优先级上的R²分别约为0.677与0.782,表明模型能较好捕捉专家打分的模式。 所有数据库与分析脚本在GitHub(https://github.com/eliasjacob/paper_bionut)公开,便于他人复现或迁移到其他国家与物种集合。
6. AI主要做了什么?
6.1没有再把369种“筛小”,而是针对369种,学习“谁更优先”
每个物种都有一组特征:地理分布、保护状态、是否野生/栽培、商业化情况、营养数据是否存在、相关菜谱数量等。
评审专家针对每个物种打了两个1–5分的优先级(成分研究优先级、消费研究优先级),再加一个置信度分。
AI(LightGBM模型)用这些特征去“拟合”专家的打分:即在369种内部建立一个“优先级函数”,预测每种的优先级高低,并评估拟合好不好(R²≈0.68 / 0.78)。
6.2用可解释AI去“解释为什么”
通过AI(SHAP)分析,量化了各个特征对“优先级高/低”的贡献,从而告诉你:在专家群体的实际决策中,哪些变量真正在起作用。结果发现:菜谱数量和在多少个州出现,是影响优先级最重要的两个正向因素;保护状态、是否昆虫/藻类等,对优先级影响反而很小。还可以比较营养学家vs环境科学家的差异:前者更看重“在菜谱中的使用”,后者更看重“地理分布广度”。
所以,AI的角色可以总结为:不是“帮专家从369变成50”,而是:在这369种之内,给每种一个更可重复、可推广的“优先级评分模型”;把专家脑海里隐性的决策规则(比如“有很多菜谱就优先”)显性化、量化、可视化出来。换句话说:AI解释和放大了专家对369种的判断逻辑,并提供了一个可在其他国家/其他物种集合上复用的优先级评估框架。
参考文献:
Jacob, M.C.M. et al., 2026. Prioritizing neglected food species in nutritional studies using expert-knowledge and explainable AI. Scientific Reports, 16: 11766. https://doi.org/10.1038/s41598-026-39484-6
