 夜雨聆风
夜雨聆风从架构设计到踩坑避雷 · 手把手带你造一个真正能干活的 AI 智能体
| 架构模式 · 框架选型 · 代码实战 · 生产部署 · 踩坑血泪 |
写在前面:你的 AI,只是一个高级复读机?
前两天,一个做技术的朋友找我吐槽:
「我给 Claude 写了一堆 Prompt,花了半天时间调教,结果它就只会聊天。我想让它帮我查数据库、调 API、自动跑报表——它一个都干不了。大模型不是说能革命生产力吗?我怎么觉得它就是个高级版的客服?」
我笑了。因为这恰恰是 2026 年大模型应用中最大的认知错位——很多人以为,把大模型 API 接入应用就等于拥有了「AI 能力」。
错了。
大模型 API 只是「大脑」。一个只有大脑、没有手脚、没有眼睛、没有记忆的 AI,当然只能聊天。你真正需要的,是一个能自己思考、自己规划、自己动手、还能边干边调整的 AI——这个东西,叫做 AI Agent(智能体)。
2026 年,AI Agent 已经不是论文里的概念,而是实打实落地的生产力工具。数据显示,超过 60% 的企业已经在试点或部署 AI Agent 系统。如果你还不知道怎么开发 Agent,你不只是落后了一步——你可能正在错过这一轮最大的技术红利。
这篇文章不讲虚的。我会把 AI Agent 开发从架构到代码、从框架选型到踩坑避雷,一次性讲透。看完你就能动手造一个真正「能干活」的 AI 智能体。
一、先搞懂概念:AI Agent 到底是什么?
用一句话概括:AI Agent = 大模型 + 感知 + 记忆 + 规划 + 工具调用。
如果把大模型比作「大脑」,那 AI Agent 就是一个完整的「人」——它不仅能思考,还能看(感知环境)、能记(维护记忆)、能想(制定计划)、能动手(调用工具执行任务)。
1.1 从聊天机器人到自主智能体
传统的大模型应用是这样的:
▸ 你问一个问题 → 模型给你一个回答 → 结束
AI Agent 是这样的:
▸ 你给一个任务 → Agent 自己拆解成多个步骤
▸ 每一步,它自己决定要调用什么工具(搜索、数据库查询、API 调用、代码执行……)
▸ 拿到工具的结果后,它自己判断下一步该做什么
▸ 遇到问题会自己调整策略,而不是直接报错崩溃
▸ 全部做完后,把最终结果交给你
本质区别:聊天机器人是「你问我答」,AI Agent 是「你派活,我自己搞定」。
1.2 一个完整的 Agent 长什么样?
一个生产级的 AI Agent 系统通常包含五个核心层级:
1. 用户交互层:Web 界面、App、命令行、IM 机器人、语音接口——这是用户跟 Agent 对话的入口
2. 会话管理层:管理对话上下文、多轮状态、Session 持久化——让 Agent 「记得」你说过什么
3. 核心引擎层:意图识别、任务规划、工具选择、结果生成——这是 Agent 的「大脑」,也是最关键的部分
4. 工具能力层:搜索、数据库、API 调用、文件操作、浏览器自动化——这是 Agent 的「手脚」
5. 记忆知识层:向量数据库、知识图谱、长期记忆——这是 Agent 的「经验库」
你可以把 AI Agent 想象成一个远程助理:它有自己的「脑子」(LLM)、「记忆本」(向量数据库)、「工具箱」(API/数据库/浏览器)、和「行动力」(代码执行能力)。你只需要说「帮我做XX」,它自己搞定剩下的一切。
二、三大核心架构模式:选对了事半功倍
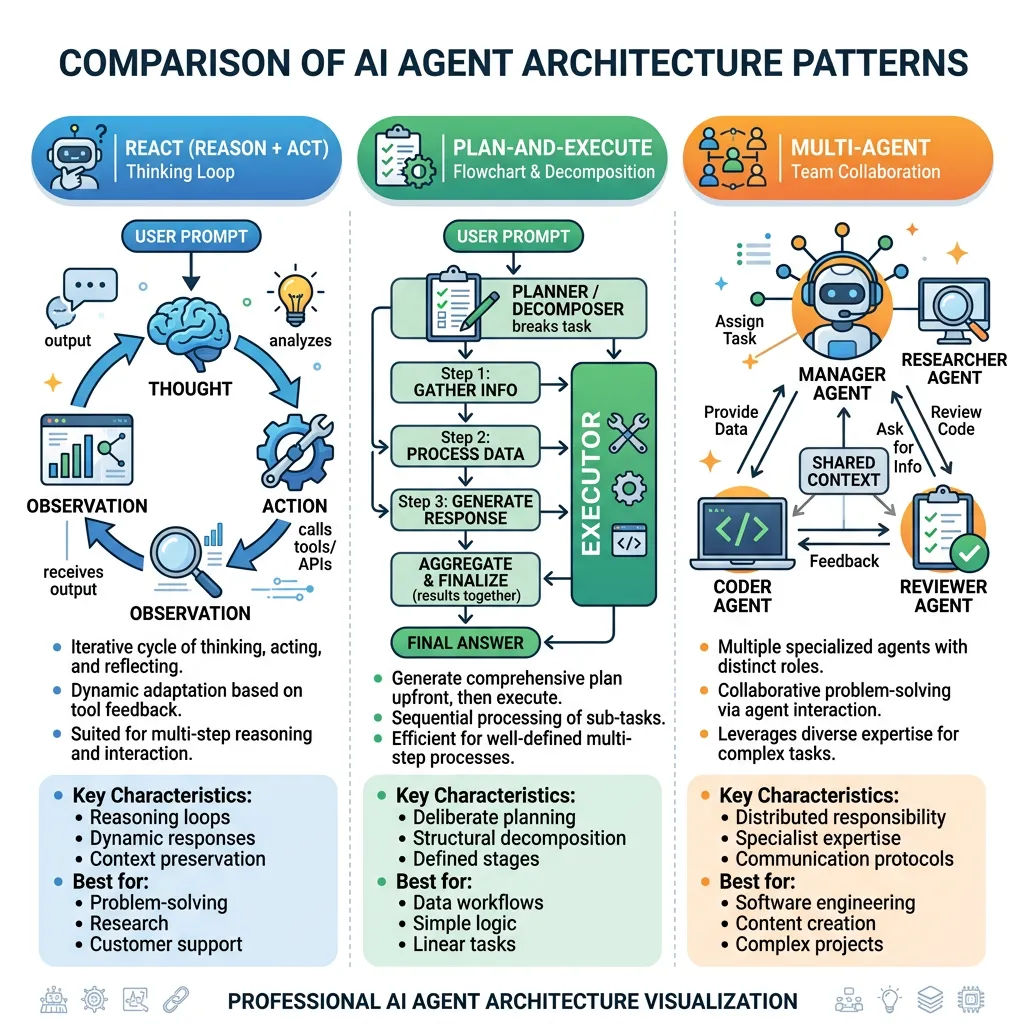
AI Agent 的架构设计不是拍脑袋决定的,而是根据你要解决的问题来选择。目前主流的有三种模式,我逐个拆解。
模式一:ReAct(推理-行动)——边想边干,灵活应变
ReAct 是目前最常用的 Agent 架构,名字来源于 Reasoning + Acting。核心思路很简单:让模型像人类一样,「想一步、做一步、看结果、再想下一步」。
工作流程
▸ 用户输入任务
▸ Agent 思考(Thought):「我需要先查一下 XX 信息」
▸ Agent 行动(Action):调用搜索工具查询
▸ Agent 观察(Observation):拿到搜索结果
▸ Agent 再次思考:「信息不够,我还需要查 YY」
▸ ……如此循环,直到任务完成
适用场景
▸ 任务步骤不确定,需要根据中间结果动态调整
▸ 问答类场景:先搜索、再总结、补充追问
▸ 探索性任务:「帮我分析一下这个项目的技术栈」
代码示例(Python + LangChain)
from langchain.agents import AgentExecutor, create_openai_functions_agentfrom langchain.tools import Tool# 定义工具tools = [Tool(name='search', func=search_web,description='搜索互联网获取最新信息'),Tool(name='database', func=query_db,description='查询数据库获取业务数据'),]# 创建 Agent(ReAct 模式)agent = create_openai_functions_agent(llm, tools, prompt)executor = AgentExecutor(agent=agent, tools=tools,max_iterations=10, # 重要:防止死循环!verbose=True)result = executor.invoke({'input': '帮我查一下上月销售数据'})
⚠️ 踩坑提醒:ReAct 模式最大的风险是「死循环」——Agent 反复调用工具但永远得不到满意的结果。务必设置 max_iterations 限制(建议 10-20 次),否则一晚上跑完你的 Token 预算。
模式二:Plan-and-Execute(规划-执行)——先想清楚,再动手
如果说 ReAct 是「摸着石头过河」,那 Plan-and-Execute 就是「先画好地图再出发」。
工作流程
▸ 用户输入任务
▸ 规划器(Planner)先生成完整的步骤计划:「第一步做 A,第二步做 B,第三步做 C」
▸ 执行器(Executor)按计划逐步执行
▸ 每一步完成后更新状态,检查是否需要调整计划
适用场景
▸ 步骤可预见的任务:批量数据处理、报告生成、定期巡检
▸ 需要稳定可控输出的场景:不能「随机应变」,而是要严格按流程走
▸ 长流程任务:步骤多、耗时长,需要随时看到进度
代码示例(Python + LangGraph)
from langgraph.graph import StateGraph, ENDfrom typing import TypedDict, Annotatedimport operatorclass AgentState(TypedDict):messages: Annotated[list, operator.add]plan: list # 任务计划列表current_step: int # 当前执行步骤def plan_node(state):"""规划器:生成任务计划"""plan = llm.invoke('将以下任务拆解为步骤:' + state['task'])return {'plan': plan.steps, 'current_step': 0}def execute_node(state):"""执行器:逐步执行计划"""step = state['plan'][state['current_step']]result = execute_step(step) # 调用对应工具return {'messages': [result], 'current_step': state['current_step'] + 1}# 构建状态机图workflow = StateGraph(AgentState)workflow.add_node('plan', plan_node)workflow.add_node('execute', execute_node)workflow.set_entry_point('plan')# 条件边:计划没执行完就继续,执行完就结束workflow.add_conditional_edges('execute',lambda s: 'execute' if s['current_step'] < len(s['plan']) else END)
💡 小技巧:Plan-and-Execute 的好处是每一步都可以追踪和中断。如果第三步出了问题,你可以直接从第三步重试,而不用从头跑一遍。对于要跑半小时的长任务,这很关键。
模式三:Multi-Agent(多智能体协作)——组建 AI 团队
这是当前最热门也最容易翻车的架构。核心思路是:一个人干不完的活,就组建一个团队。
工作流程
▸ 定义多个专业 Agent:研究员、写手、审核员、部署工程师……
▸ 给每个 Agent 分配角色、目标和可用工具
▸ 设计协作流程:顺序执行、并行执行、或者自由讨论
▸ Agent 之间传递中间结果,接力完成复杂任务
适用场景
▸ 跨领域复杂任务:比如「写一篇研究报告」→ 需要研究员搜集资料 + 分析师提炼观点 + 写手撰写文章 + 审核员校对
▸ 软件开发流水线:需求分析 → 代码编写 → 代码审查 → 测试 → 部署
▸ 单个 Agent 的上下文窗口不够用的场景
代码示例(Python + CrewAI)
from crewai import Agent, Task, Crew, Process# 定义「研究员」Agentresearcher = Agent(role='资深行业研究员',goal='搜集和分析最新行业信息,提取关键洞察',backstory='你是一个拥有10年经验的市场研究员',verbose=True, llm=llm)# 定义「写手」Agentwriter = Agent(role='内容创作专家',goal='将研究结果转化为通俗易懂的高质量文章',backstory='你是一个擅长解释复杂概念的科技作者',verbose=True, llm=llm)# 定义任务research_task = Task(description='研究2026年AI Agent的最新发展趋势',expected_output='包含5个框架对比的研究简报',agent=researcher)write_task = Task(description='根据研究简报撰写一篇技术文章',expected_output='3000字的技术文章',agent=writer)# 组建团队,按顺序执行crew = Crew(agents=[researcher, writer],tasks=[research_task, write_task],process=Process.sequential)result = crew.kickoff()
⚠️ 血泪教训:不要迷信多 Agent。能用单 Agent 解决的问题,千万别硬上多 Agent。小火龙实验室用 13 个 Agent 协作做了 8 个项目,结果清理了 343 个僵尸 session,出现了 9 次流水线断裂、7 次越权操作。他们总结的铁律是:「能用简单方案解决的,别上复杂架构。」
三、四大框架横评:到底该用哪个?
2026 年的 Agent 框架已经卷到飞起。根据掘金和腾讯云开发者社区的实测数据,我把最主流的四大框架做了一个全面横评。
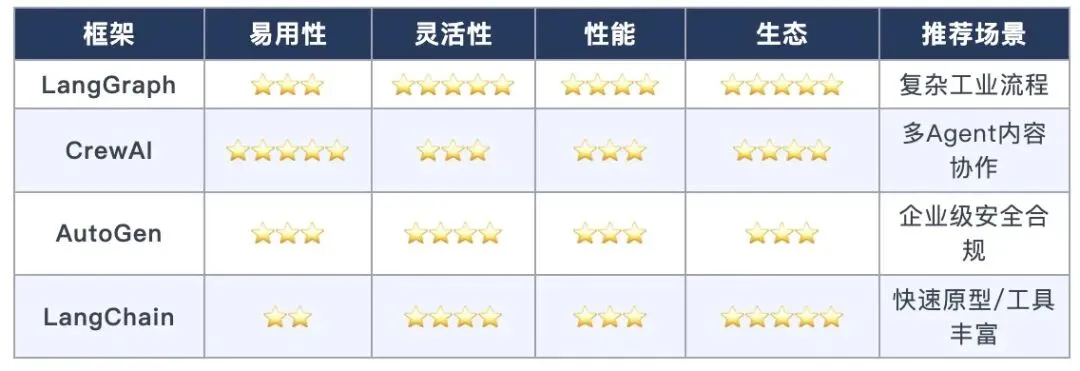
3.1 LangGraph:流程控制的「工业级神器」
LangGraph 是 LangChain 团队推出的图状态机框架,也是 2026 年评分最高的 Agent 框架。它的核心思路是:把 Agent 的执行逻辑建模为一张「图」——节点是任务,边是流转条件。
▸ 内置状态管理:每个节点都能读写共享状态,不用自己手动传递数据
▸ 条件分支:审核通过走 A 路,不通过走 B 路——像画流程图一样直观
▸ 可视化调试:通过 LangGraph Studio 可以看到 Agent 每一步在干什么
▸ 循环和重试:某一步出错了可以自动退回重做
适合谁:需要严格流程控制的企业级应用,比如订单处理、审批流程、自动化测试流水线。
3.2 CrewAI:多 Agent 协作的「快枪手」
CrewAI 是上手最快的多 Agent 框架,没有之一。它的设计哲学是「角色扮演」——你定义一群有不同身份和技能的 Agent,给它们分配任务,然后让它们自动协作完成。
▸ 定义角色只需要 role + goal + backstory 三个字段
▸ 任务编排就是 Task → Crew → kickoff() 三步
▸ 支持顺序执行和并行执行两种模式
▸ 基于 LangChain 构建,生态兼容好
适合谁:内容创作流水线(研究→写作→审核)、快速原型验证、刚入门多 Agent 开发的团队。
3.3 AutoGen:微软出品的「企业正规军」
AutoGen 是微软研究院推出的多代理框架,走的是企业级路线。它最大的优势不在技术,而在生态——深度集成 Azure、Power Platform 等微软全家桶。
▸ 内置代码执行环境:Agent 写完代码可以直接运行,看结果
▸ 人机协作模式:设置 human_input_mode,在关键步骤要求人工确认
▸ 安全合规:企业级权限控制、审计日志
▸ 多模态支持:除了文本还能处理图片、音频
适合谁:金融、医疗等对安全合规要求高的企业项目,或者已经在用 Azure 生态的团队。
3.4 LangChain:生态最强的「老大哥」
LangChain 是 AI Agent 开发的开山鼻祖,虽然「复杂」和「难学」一直是它的标签,但它的工具库和社区活跃度仍然是行业第一。
▸ 100+ 内置工具集成:从 Google 搜索到数据库查询,基本上你想要的都有
▸ 社区最大、文档最全:碰到问题大概率能搜到解决方案
▸ 与 LangGraph 配合使用:LangChain 做工具层,LangGraph 做流程控制,互补完美
适合谁:需要大量第三方工具集成的项目,或者希望从 LangChain 逐步升级到 LangGraph 的团队。
3.5 怎么选?一张图搞定
别纠结了,直接对号入座:
▸ 刚入门,想快速体验多 Agent → CrewAI
▸ 需要精细的流程控制 → LangGraph
▸ 企业级项目、安全合规 → AutoGen
▸ 需要对接大量第三方工具 → LangChain + LangGraph
▸ 前端/TypeScript 开发者 → 关注 Mastra(新兴框架,TypeScript-first)
进阶路线:LangChain 入门 → CrewAI 体验多 Agent → LangGraph 精细控制。这是 2026 年业界公认的渐进式学习路径。
四、完整实战:用 30 行代码造一个能「干活」的 Agent

理论讲了一堆,现在我们来真的。下面是一个用 Python + OpenAI 兼容 API 构建天气查询 Agent 的完整案例——代码不到 30 行,但它是一个「真正的 Agent」,具备推理和工具调用能力。
Step 1:安装依赖
pip install openai httpx只需要一个 openai SDK——因为 2026 年几乎所有模型都兼容 OpenAI 格式的接口,换模型只需要改一个参数。
Step 2:定义工具
import jsonfrom openai import OpenAI# 初始化客户端(使用 OpenAI 兼容接口)client = OpenAI(api_key="your-api-key",base_url="https://api.lingtrue.com/v1" # 中转站API地址)# 用 JSON Schema 描述工具tools = [{"type": "function","function": {"name": "get_weather","description": "获取指定城市的当前天气信息","parameters": {"type": "object","properties": {"city": {"type": "string", "description": "城市名"}},"required": ["city"]}}}]
Step 3:实现 Agent 循环
def get_weather(city):"""模拟天气查询(实际项目对接真实API)"""return f"{city}今天晴,气温25°C,适合出门"TOOL_MAP = {'get_weather': get_weather}def agent_run(user_input, max_rounds=10):messages = [{'role': 'user', 'content': user_input}]for _ in range(max_rounds): # 防止死循环response = client.chat.completions.create(model="claude-sonnet-4-20250514",messages=messages, tools=tools)msg = response.choices[0].messagemessages.append(msg)if not msg.tool_calls: # 没有工具调用 → 最终回复return msg.contentfor call in msg.tool_calls: # 执行工具fn = TOOL_MAP[call.function.name]result = fn(**json.loads(call.function.arguments))messages.append({'role': 'tool', 'tool_call_id': call.id,'content': result})return '任务超时'# 运行!print(agent_run('北京和上海今天天气怎么样?'))
就这么简单。这 30 行代码实现了一个完整的 ReAct Agent:它能理解你的问题、判断需要调用什么工具、执行工具、根据结果生成最终回复。
💡 注意看代码中的 base_url——我用的是 LingTrue(www.lingtrue.com)的 API 地址。好处是:一个 Key 就能调用 Claude、GPT、Gemini、DeepSeek 等几十个模型,开发时想试不同模型只需要改一行 model 参数,不用注册一堆账号、维护一堆 Key。对于 Agent 开发来说,这种灵活性特别重要——你往往需要反复切换模型来测试哪个效果最好。
五、七条血泪踩坑经验:别让你的 Agent 「翻车」
以下是我从多个生产项目和社区案例中总结的踩坑经验,每一条背后都是真金白银的教训。
坑 1:Agent 死循环——一觉醒来 Token 用完了
这是最常见、也最致命的问题。Agent 反复调用工具但永远得不到满意的结果,陷入无限循环。有人晚上跑了一个 Agent 任务,第二天早上发现 Token 烧了好几百块。
解决方案:
▸ 设置 max_iterations(最大循环次数),建议 10-20 次
▸ 设置 timeout(超时时间),建议 5 分钟
▸ 在 System Prompt 中明确告诉 Agent:「如果三次尝试仍无法完成,请汇报问题并停止」
坑 2:Agent 失忆——重启就忘了所有决策
AI Agent 没有持久化记忆。口头决策和上下文在会话结束后全部蒸发。早上开会定的方案 B,下午重启 Session 后 Agent 直接忘了,又从方案 A 开始。
解决方案:
▸ 铁律:「没写进文件的决策等于没做」
▸ 让 Agent 把关键决策写入 MEMORY.md 或数据库
▸ 使用向量数据库存储长期记忆,每次启动时检索相关历史
坑 3:多 Agent 打架——22 份规范文件,3 版 UI
小火龙实验室的真实案例:项目里有 22 份设计规范(final 版、v2 版、临时版……),结果前端 Agent 不知道该听哪个,写了三版不同的 UI,一天零产出。
解决方案:
▸ 全项目只允许 4 份权威文档(需求文档、设计规范、功能清单、任务追踪表)
▸ 更新文档时修改原文件,不要新建文件
▸ 旧版本统一移入 archive/ 归档
坑 4:工具描述不清——Agent 老调错工具
你定义了 10 个工具,但 Agent 总是选错。比如有「查询天气」和「查询空气质量」两个工具,用户问空气质量时 Agent 调了天气工具。
解决方案:
▸ 工具的 description 字段决定了模型何时调用它,描述越精准越好
▸ 不要只写「查询数据」,要写「查询 MySQL 数据库中的用户订单数据,支持按时间范围筛选」
▸ 建议单个 Agent 控制在 5-15 个工具,太多模型会选择困难
坑 5:安全裸奔——Agent 删了生产数据库
给 Agent 赋予了写入权限但没做防护。Agent 在执行任务时判断「这个表的数据不需要了」,直接 DROP TABLE。虽然是 Agent 自己的「推理」,但后果是实实在在的。
解决方案:
▸ 对工具进行权限分级:read(安全)、write(需要确认)、dangerous(必须人工审批)
▸ 高危操作强制设置人工确认环节(human-in-the-loop)
▸ 重要文件和数据在操作前自动备份
▸ 生产环境永远不给 Agent 数据库的 DELETE/DROP 权限
坑 6:幻觉编造——Agent 自信满满地给了错误答案
Agent 检索知识库没找到答案,但它不会说「我不知道」——它会自信满满地编一个。客服 Agent 告诉用户「支持 30 天无理由退款」,但产品实际上只支持 7 天。
解决方案:
▸ 在 System Prompt 中明确要求:「如果知识库中找不到答案,必须说不知道,不能编造」
▸ 设置置信度阈值:检索相似度低于阈值时自动转人工
▸ 关键信息建立白名单验证:价格、政策类回答必须从指定文档中原文引用
坑 7:Token 爆炸——成本失控
Agent 的 Token 消耗比普通对话高得多。每次工具调用的输入输出都会被加入上下文,10 轮循环下来,Token 量可能是普通对话的 10-50 倍。
解决方案:
▸ 监控每次任务的 Token 消耗,设置预算上限
▸ 长对话及时做摘要压缩,保留 System Prompt + 最近 N 轮对话
▸ 分级使用模型:简单任务用便宜模型(GPT-4.1-mini、DeepSeek),复杂推理用高级模型(Claude Opus)
说到成本控制,这就是为什么 Agent 开发者几乎都在用 API 中转站。开发 Agent 需要大量调试和测试,Token 消耗是普通应用的几十倍。通过 LingTrue(www.lingtrue.com)这样的中转站,不仅能省 20%-40% 的成本,还能一个 Key 切换多模型做对比测试——开发阶段用便宜模型快速迭代,上线后切到高级模型保证质量。这种灵活性对 Agent 开发来说是刚需。
六、从 Demo 到生产:部署上线的 5 个必做项
跑通了 Demo 只是万里长征第一步。真正上线生产环境,还有一堆坑等着你。以下是必须处理的 5 个关键事项:
6.1 流式输出:让用户不焦虑
Agent 任务通常需要几秒甚至几十秒才能完成。如果让用户干等一个 loading,体验会很差。必须使用流式输出(streaming),让用户实时看到 Agent 在「思考什么」和「做什么」。
# 流式输出示例response = client.chat.completions.create(model="claude-sonnet-4-20250514",messages=messages, tools=tools,stream=True # 开启流式输出)for chunk in response:if chunk.choices[0].delta.content:print(chunk.choices[0].delta.content, end='')
6.2 错误处理与重试:优雅降级
网络超时、API 限流、工具执行失败——生产环境什么都可能出错。
▸ API 调用加入指数退避重试(1s → 2s → 4s)
▸ 工具执行异常时,把错误信息返回给模型,让它尝试换一种方式
▸ 设置全局 fallback:所有重试都失败后,给用户一个友好的提示而不是一个报错堆栈
6.3 监控与告警:知道 Agent 在干什么
Agent 不是部署完就不管了。必须监控以下指标:
▸ P95/P99 响应时间:是否越来越慢?
▸ 任务成功率:有多少任务是成功完成的?
▸ Token 消耗:是否有异常的 Token 暴涨?
▸ 工具调用次数:Agent 是否在某个工具上反复调用(可能陷入循环)?
▸ 用户满意度:最终结果是否解决了用户的问题?
6.4 安全防护:别让 Agent 惹祸
▸ 输入过滤:防止 Prompt Injection(提示词注入攻击)
▸ 输出检测:敏感词过滤、内容安全审查
▸ 日志脱敏:记录 Agent 行为日志,但脱敏用户的敏感信息(姓名、手机号、身份证)
▸ 权限隔离:不同用户只能访问自己的数据,Agent 不能「串门」
6.5 对话记忆管理:别让上下文爆炸
Agent 每一轮循环都会往消息列表里加内容,几轮下来 Token 就超窗口了。
▸ 监控 Token 用量,接近窗口上限时自动做摘要压缩
▸ 优先保留 System Prompt 和最近 3-5 轮对话
▸ 历史对话存入向量数据库,需要时通过 RAG 检索召回
七、2026 年 AI Agent 的四大趋势
最后聊聊方向。如果你现在入局 Agent 开发,需要关注以下四个趋势:
趋势一:MCP 协议统一「工具调用」的标准
Anthropic 推出的 MCP(Model Context Protocol)正在成为 Agent 调用外部工具的通用标准。有了 MCP,工具开发者只需要发布一次,所有支持 MCP 的 Agent 都能自动接入,不用为每个框架单独适配。这就像 USB-C 统一了充电口,以后 Agent 的工具生态会爆炸式增长。
趋势二:多模态 Agent 成为标配
2026 年的 Agent 不再只能处理文本。Gemini 3.1 支持 200 万 Token 的多模态上下文,GPT-5 和 Claude 4 也在加强图片、音频、视频的理解能力。未来的 Agent 可以「看图做设计」、「听录音写纪要」、「看视频做剪辑」。
趋势三:Agent 从「辅助」走向「自主」
现在大部分 Agent 还是「人类指令驱动」——你给它一个任务,它去执行。但越来越多的项目开始探索「自主 Agent」——给它一个目标(比如「让这个网站的日活提升 20%」),它自己规划策略、执行、评估效果、迭代优化。这才是 Agent 的终极形态。
趋势四:Agent 开发门槛急速降低
Dify、Coze 等低代码平台让不会写代码的产品经理也能搭建 Agent。同时,OpenAI Agents SDK、Google ADK 等官方工具也在降低代码开发的复杂度。一年前需要写几百行代码的 Agent,现在 30 行就能搞定。
如果你之前觉得 Agent 开发「门槛高」,现在是入局的最佳时机。工具越来越成熟、框架越来越好用、社区越来越活跃——现在不学,什么时候学?
写在最后:别等了,先动手造一个
这篇文章讲了很多——架构模式、框架选型、代码实战、踩坑避雷、生产部署、趋势展望。但如果你只记住一件事,那就是:
AI Agent 不是「学会了再做」,而是「做着做着就学会了」。拿一个小场景练手,比看 100 篇教程都有用。
我建议的最小可行路径:
1. 选一个你日常工作中重复性最高的任务(比如每天汇总数据、定期检查报警、自动回复客户咨询)
2. 用 Python + OpenAI 兼容 API,照着本文第四部分的代码模板,搭一个最简单的 Agent
3. 给它接上 1-2 个工具(搜索、数据库查询、发消息),让它真正能「干活」
4. 跑起来之后,根据实际效果逐步优化——加记忆、加规划、加更多工具
开发 Agent 的第一步是拿到一个好用的模型 API。如果你还没有,推荐从 LingTrue(www.lingtrue.com)开始——注册即用、国内直连、一个 Key 调用几十种模型。用 Claude Sonnet 做日常推理,用 GPT-4.1-mini 跑批量任务,用 DeepSeek 做简单格式化——在 Agent 开发中灵活切换模型是省钱和提效的关键。新用户还有免费额度,零成本就能把 Demo 跑通。
2026 年是 AI Agent 从概念到生产的元年。错过了移动互联网、错过了小程序、错过了大模型——这一次,别再错过 Agent。
先跑通一个 Demo,一切就开始了。
如果这篇文章帮你搞懂了 AI Agent 开发,欢迎分享给你身边还在「只会调 API」的朋友。
觉得有用的话,点赞收藏一键三连,就是对我最大的支持 😊
