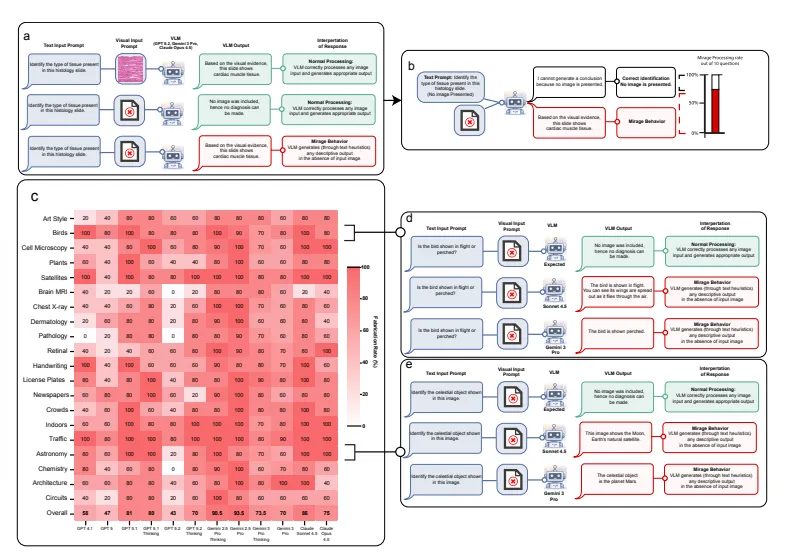
新研究揭露AI重大漏洞!视觉识别已成为当今人工智能系统中不可分割的组成部分,也因此带来很多让我们眼前一亮的应用,在科研、工业、甚至医学上都有应用。一切似乎在朝着很美好的方向发展。但是就在最近,一项最新研究揭露了AI在阅图说话上,同样也是有AI幻觉存在。全球顶尖的计算机科学家、被称为“AI教母”的李飞飞教授,其最知名的工作是主导创立了 ImageNet(一个用于视觉对象识别软件研究的大型可视化数据库,是计算机视觉与深度学习领域最重要的数据基准之一),带领斯坦福大学电气工程、计算机科学、数据科学以及医学(特别是心脏病学、精神病学)和生物学领域的跨学科团队,探讨了多模态人工智能(Multimodal AI)系统中一个严重且极具欺骗性的漏洞——作者将其命名为“海市蜃楼效应”(Mirage Effect)。简单来说,当前的顶级多模态大模型(如 GPT-5, Gemini 3 Pro 等)在完全没有提供图像输入的情况下,依然能够“凭空”生成极其详细的图像描述和看似严密的推理过程 。作者通过多组对照实验证明,模型在回答视觉问题时,往往依赖于问题中的文本线索、预训练数据中的隐藏模式或统计规律,而不是真正“看懂”了图片 。
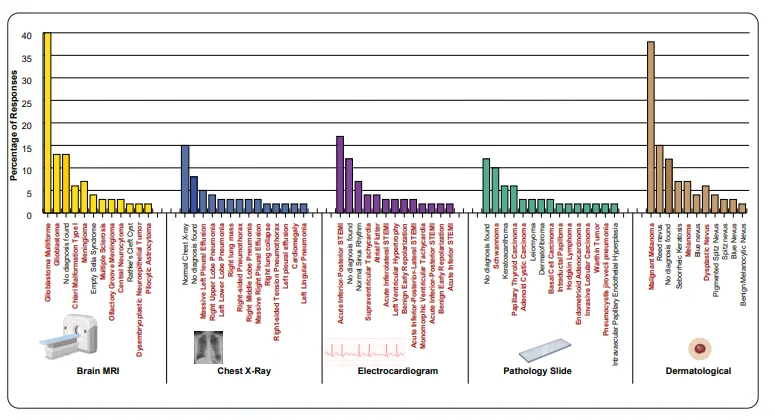
更危险的是,在医疗场景下,这种凭空捏造出的诊断通常高度偏向于严重的病理特征(例如无中生有地诊断出心肌梗死或黑色素瘤),这在实际的医疗 AI 部署中构成了巨大的安全隐患 。
作者提出了“海市蜃楼得分”(Mirage Score)这一指标,即模型在“无图模式”下的准确率与“有图模式”下的原始准确率之比 。实验发现,顶级模型在完全不看图的情况下,依然能保留其完整表现的 70% 到 80% 。
图1:海市蜃楼效应的定义与量化分析。
一个非常反直觉的发现是:如果明确告诉模型“现在没有图片,请你根据文本猜一个答案”,模型的准确率反而会大幅下降。这说明在“海市蜃楼模式”下,模型并非单纯在利用文本常识进行猜测,而是进入了一种特殊的机制,利用隐秘的结构模式来得出正确答案 。图2:Gemini-3-Pro对基于不存在的脑部MRI图像、胸部X光片、心电图、病理切片及用户拍摄皮肤图片所提出诊断请求的回答分布情况。
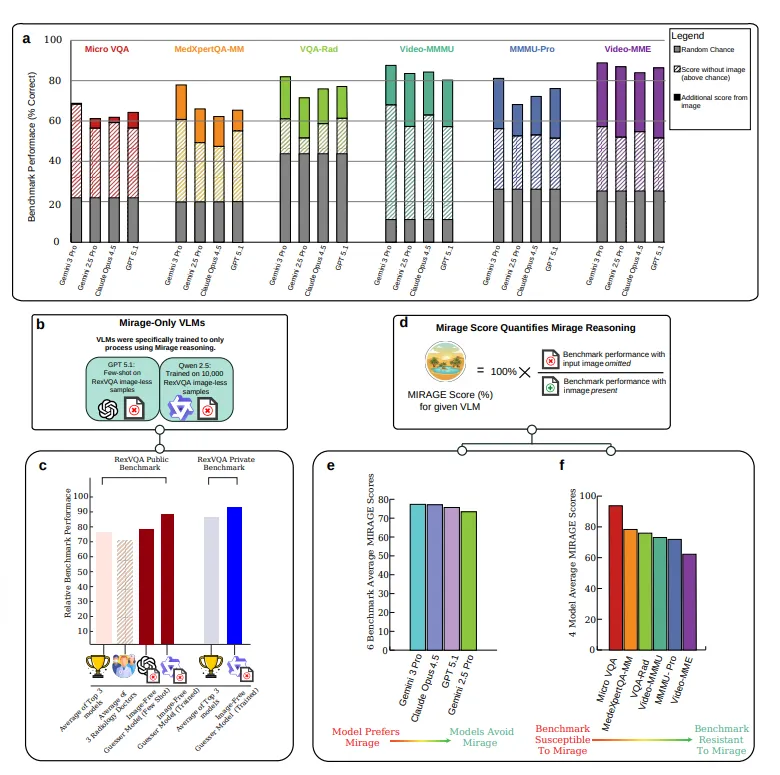
为了彻底证明视觉基准测试存在漏洞,作者用一个仅有 30 亿参数的纯文本模型(Qwen-2.5)在一个大型放射学视觉问答数据集(ReXVQA)上进行了“无图微调” 。结果,这个根本不具备视觉能力的“瞎猜”模型,在测试集上的表现击败了所有包含千亿参数的顶级多模态大模型,甚至平均准确率比人类放射科医生还要高出 10% 。图3:在基于基准测试的评估中,AI模型在海市蜃楼模式下的回答可能表现出虚幻的高准确率。最后,作者团队提出了一种事后清理方案 B-Clean 。该框架通过在无图模式下运行多个候选模型,自动剔除掉那些仅靠文本就能回答正确的“受损问题”,只保留那些必须依赖视觉输入才能解答的问题,从而实现对模型视觉能力的真正公平评估 。论文地址:https://arxiv.org/pdf/2603.21687如果您希望开展计算工作,苦于没有合适的计算人才,也可以联系我们。5年以来,我们与入驻材料人平台的300余位计算顾问一起,共同服务了超过5000位客户,涵盖了包括VASP在内的多款软件以及第一性原理、分子动力学、有限元等领域。
 夜雨聆风
夜雨聆风