 夜雨聆风
夜雨聆风副标题:CI/CD 进车的四道工程墙、传统 OEM 的组织陷阱、以及 SDV 永远结不了的账
系列导读:上一篇《谁重写了汽车的神经系统?》从全景视角讲了 E/E 架构的演进史——从分布式到域集中到区域式,以及 SDV、AIDV 各自在这条线上的位置。接下来这个"软件定义汽车"系列(上/中/下三篇),把 SDV 的工程内幕拆开来看。本文是"软件定义汽车"系列(下)。前两篇拆解了 SDV 的五笔工程账单——从中央计算平台到算力留白。本篇进入执行层:开发模式怎么变、谁在真正落地、以及这件事为什么没有终点。
前情提要
前两篇我们拆了 SDV 的五笔工程账单:中央计算平台替代 150 个黑盒 ECU,硬件抽象层让软件不再焊死在芯片上,SOA 把通信从计划经济变成市场经济,OTA 背后是五层楼的工程链,算力留白是为还没写出来的软件预付定金。架构图纸画好了——但图纸能不能变成量产车,取决于谁在执行、怎么执行、以及执行到一半会撞上什么墙。
第三幕:CI/CD 进车——把互联网开发模式搬进汽车
前面五笔工程账单讲的是"架构"——建好了这套架构,才有能力做 SDV。但有了架构,还需要能匹配这套架构的开发模式。
这是大多数文章不会讲到的部分。
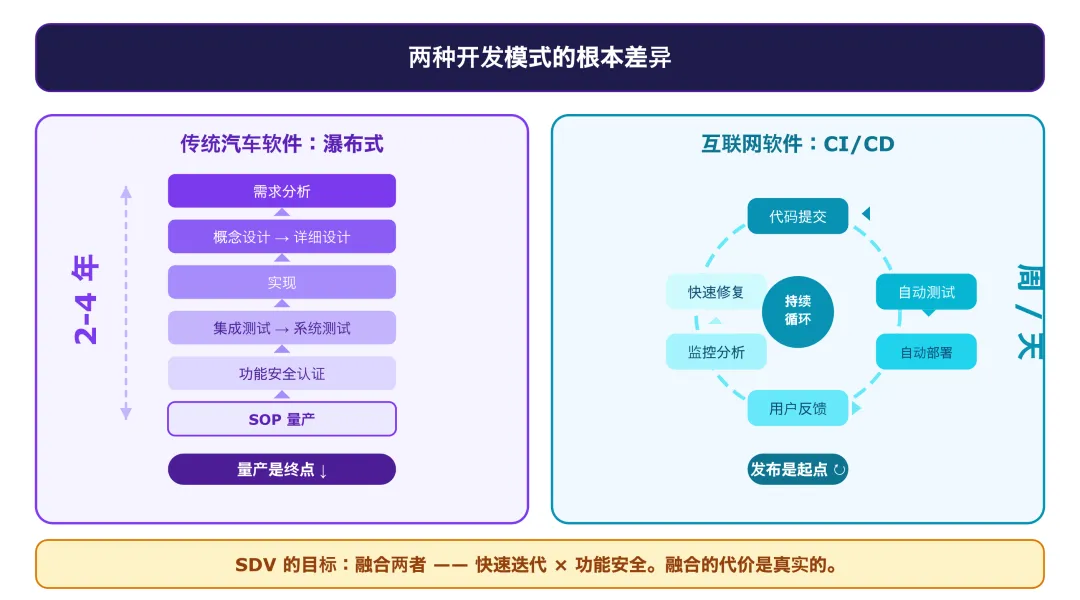
两种开发模式的根本差异
传统汽车软件的开发模式是"瀑布式":需求分析 → 概念设计 → 详细设计 → 实现 → 集成测试 → 系统测试 → 功能安全认证 → 量产(SOP)。每个阶段严格顺序,一个功能从立项到量产,2-4 年是常态。量产是终点——之后除了 bug fix,功能就固定了。
互联网软件是 DevOps/CI/CD:每次代码提交自动触发编译和测试,测试通过后自动部署。发布频率可以做到每天数次。
SDV 的目标是融合两者——让汽车软件既能快速迭代,又能满足功能安全要求。
融合的代价是真实的,不是 PPT 里讲的那么美好。
挑战一:虚拟化测试的信任鸿沟
传统汽车测试必须在真实 ECU 上进行,原因是软件和硬件的强耦合。CI/CD 要求每次代码提交都能自动化测试,但不可能为每次提交准备一套真实 ECU 台架——成本高,周期长,根本跟不上提交频率。
解法是 Virtual ECU / SIL(Software-in-the-Loop):用软件模拟 ECU 的执行环境,让汽车软件模块在普通 Linux 服务器上运行。AUTOSAR Adaptive 的 ara::com 等接口层在 POSIX 系统上有完整实现,大多数应用层模块可以在 PC 上做功能测试。
但这里有一道很少被公开讨论的信任鸿沟:交叉编译器的行为差异。
SIL 环境通常在 x86 Linux 上用 GCC 或 Clang 编译运行。量产代码跑在 ARM Cortex-R/M 或 Infineon TriCore 上,用的是 Green Hills、Tasking 或 Wind River 的专用编译器。这两套编译器的优化策略不同,结构体内存对齐规则不同(同一个 struct 在 GCC 和 Green Hills 下可能产生不同的 padding),浮点运算精度处理不同(x86 的 80-bit 扩展精度 vs ARM 的 IEEE 754 strict 模式),甚至 volatile 关键字的语义在不同编译器下都有微妙差异。
一个在 SIL 上通过所有测试的控制算法,部署到真实 ECU 后,可能因为浮点累积误差的不同,在某个边界条件下输出一个偏离预期的控制量。对于 ADAS 的路径规划来说,0.001 弧度的转向角偏差在 120km/h 时意味着什么,不用多算。
SIL 测试通过,只能证明算法的逻辑在 x86 上是对的——不能证明它在目标芯片上的行为也是对的。功能正确和行为一致,是两件不同的事。
更深一层:SIL 模拟的通常是指令级行为(instruction-accurate),不是时序级行为(cycle-accurate)。真实 ECU 上的中断延迟、DMA 传输时序、缓存失效(cache miss)、总线仲裁竞争——这些在 SIL 里不存在。一个实时控制循环在 SIL 上稳定跑 1ms 周期,在真实芯片上可能因为一次缓存未命中多了 50μs,导致控制信号晚到,执行器来不及响应。
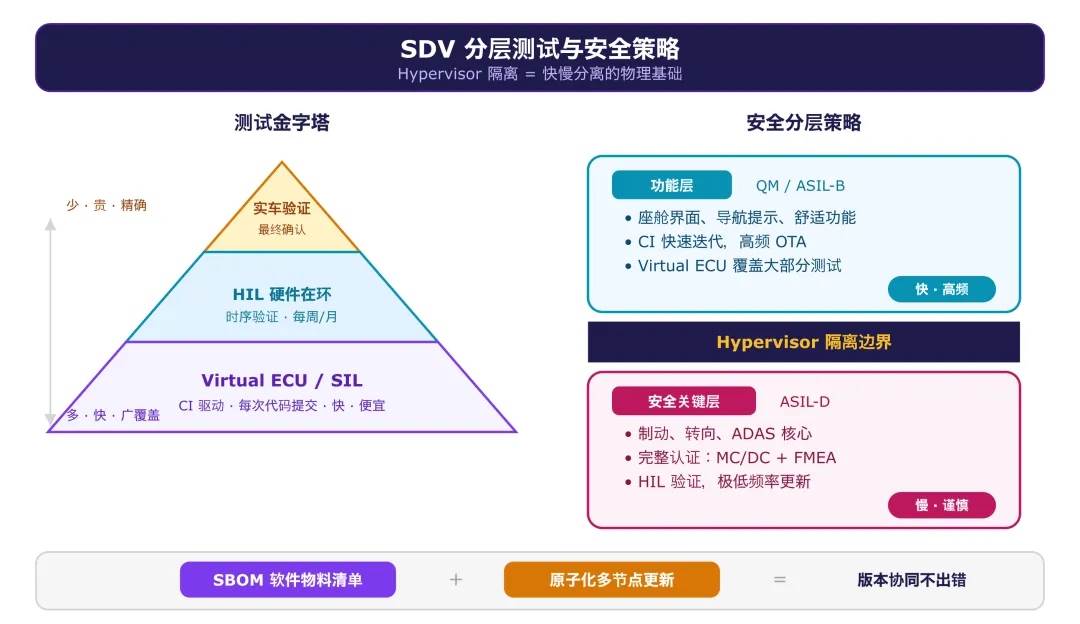
所以实践中是分层测试金字塔:大量的功能逻辑测试走 SIL(快,便宜,能嵌入 CI pipeline),时序敏感的测试走 HIL(Hardware-in-the-Loop,用真实硬件验证),最终的系统级测试走实车。底层越宽,顶层就越能聚焦在真正只有实车才能发现的问题上——但底层的可信度直接决定了顶层要补多少课。如果 SIL 和真实硬件的行为差异不被控制住,你的测试金字塔就是建在沙子上的。
挑战二:变体爆炸——CI 的组合噩梦
互联网公司的 CI pipeline 跑一次构建、一套测试。汽车公司的 CI 跑的是一个矩阵。
一辆车的软件配置不是"一个版本",而是多个维度的笛卡尔积:
硬件平台变体:同一款车可能搭载不同代的中央计算平台(高配 / 低配 / 不同市场版本),区域控制器可能来自不同供应商 市场法规变体:中国、欧洲、北美的排放标准、安全法规、网络安全要求各不相同,同一个功能在不同市场的行为参数不一样 选装配置变体:有没有自动泊车、有没有抬头显示、有没有后排娱乐——每个选装包对应一组不同的软件模块激活组合 ECU 供应商版本:同一个功能位置,A 批次用的是供应商甲的芯片,B 批次用的是供应商乙的——接口一样,但底层驱动不同
一个大型 OEM 集团管理的不是"一套软件",是几千个配置组合。有欧洲汽车集团在峰值时期同时维护超过 70 个软件平台。
这意味着什么?每次代码提交,CI pipeline 理论上需要对所有受影响的配置组合分别构建、分别测试。如果你改了一个底层通信模块,影响面是全部变体——构建农场(Build Farm)需要同时编译几百个目标,每个目标的完整构建时间在 1-4 小时不等(AUTOSAR BSW 生成 + 应用层编译 + 链接 + 镜像打包),测试集运行时间另算。
互联网公司的 CI 是一条流水线;汽车公司的 CI 是一张网。网的每个节点都可能是一个失败点,每个失败点都需要有人去排查是真 bug 还是环境问题。
工程上的应对策略是"影响面分析"(Impact Analysis):不是每次都跑全量矩阵,而是根据代码变更的范围,自动计算哪些配置组合受影响,只跑受影响的子集。这要求有一张精确的依赖关系图——从源代码文件到编译目标到配置变体到测试集的完整映射。维护这张图本身,就是一个不小的工程——而且一旦映射出错,你跳过的那个变体恰好就是出 bug 的那个。
挑战三:功能安全认证的节拍器
ISO 26262 对 ASIL-D 软件的测试要求不是"跑了多少测试用例",而是"能否证明所有可能影响安全的输入组合都被覆盖"。
在实际工程里,这意味着:MC/DC(修正条件/判定覆盖)——要求每个布尔子条件都被独立证明能影响最终判定结果。一个包含 5 个条件的 if 语句,分支覆盖只需要 2 个测试用例(判定为真和为假各一个),MC/DC 至少需要 6 个。条件越多,差距越大。加上形式化分析、FMEA(失效模式分析)、经过 ISO 26262 认证的工具链(工具本身要通过认证,你不能用未认证的 GCC 编译安全关键代码然后声称符合 ASIL-D),一套流程走下来,一个模块的认证周期以月计。
CI 能做到高代码覆盖率(行覆盖、分支覆盖),但这离 ISO 26262 要求的覆盖率差了一个维度。一个拥有 100% 行覆盖率的测试套件,在功能安全审计里可能仍然被认为"覆盖不足"——因为审计看的不是"你跑过这一行没有",而是"你能不能证明这个条件的每一种独立取值变化都被测过"。
行覆盖率是一把尺子;MC/DC 是一台显微镜。CI 擅长用尺子快速量;功能安全认证要求你用显微镜慢慢看。两者的节奏天然冲突。
行业正在收敛的解法:严格分层。安全关键层(ASIL-D)走完整的认证流程,更新频率以季度甚至年为单位;功能层(QM/ASIL-B)走 CI 快速迭代,频率可以做到周。中央计算平台上的 Hypervisor 提供了隔离的物理基础——安全层和功能层在不同的 VM 里,有了边界,才有可能分别对待。
但分层不是免费的。安全层和功能层之间的每一个接口,都是一个"安全边界"——功能层不能以任何方式影响安全层的行为,这个保证需要严格验证。你以为你在画一条线把两个世界隔开,实际上你在建一堵墙——而墙的每一块砖都要经过认证。
挑战四:整车 OTA 的物理约束
前面三个挑战是"开发侧"的。到了"部署侧"——OTA 推送到车上——还有一组约束,由物理定律决定,工程师只能适应,不能突破。
Flash 寿命的硬算术
车载存储用的是车规级 NAND Flash(eMMC 或 UFS),典型的 P/E(Program/Erase)寿命是 3000-10000 次擦写循环。每次 OTA 写入新固件,就消耗擦写次数。
算一笔账:假设一辆车设计寿命 15 年,Flash P/E 寿命 3000 次。扣掉 wear leveling 的效率损耗(通常 70%-80% 有效利用率),实际可用约 2000-2400 次。一次 OTA 涉及 A/B 分区切换 + 配置写入 + 日志记录,实际消耗的 P/E 次数约 3-5 次。再算上日常运行的诊断日志、配置缓存、用户数据写入,Flash 的寿命预算比直觉要紧得多。
OTA 的频率上限,不是被你的开发速度决定的,也不是被网速决定的——是被 Flash 的物理寿命决定的。 这是 SDV "持续迭代"叙事里最少被提及的硬约束。
百万辆车同时更新的带宽工程
一个 OTA 差分包假设 500MB(差分压缩后的典型大小),推送给 100 万辆车,总传输量 = 500TB。服务器端的带宽(平均约 6-7 Gbps)对 CDN 来说不算挑战——真正的瓶颈在蜂窝网络的最后一公里。
车不是服务器,不能 7×24 在线。多数 OEM 限制 OTA 只在车辆停放 + 充电/熄火状态下触发下载(行驶中更新安全关键模块是不可接受的)。下载窗口集中在晚间充电的 6-8 小时内。一个蜂窝基站的共享带宽通常在 500Mbps-1Gbps,如果该基站覆盖范围内有上千辆车同时请求 500MB 的下载,每辆车分到的实际速率可能只有几百 KB/s——一个本该 10 分钟完成的下载,变成了几个小时。乘以全国几千个基站的并发压力,这就是一道蜂窝网络的容量规划题。
这就是"周一早晨问题":周五晚上推送 OTA,周末车主陆续下载,周一早晨上车——有人更新成功了,有人下载到一半中断了,有人因为信号差下到一个损坏的包触发了回滚。客服电话开始响。
解法是分批灰度发布:先推 1% 的车队(内部测试车或 early adopter),监控 48-72 小时无异常,再扩大到 10%,再到 50%,最后全量。特斯拉的 Early Access Program 就是这个逻辑——每次 FSD 大版本更新,先推几千辆测试车队,数据回传正常后逐步扩展。这意味着一次 OTA 从"代码冻结"到"全量部署完成",可能需要 4-6 周。
多节点原子更新
一个 SDV 功能通常跨越多个节点:中央计算平台负责决策,区域控制器负责执行。这些节点的固件版本必须互相兼容。
给中央计算平台推了新版本,接口协议有一处变化;但区域控制器还在跑旧版本,不认识新消息格式——系统在版本不一致的状态下可能出现功能失效甚至故障。
解法需要两件东西:SBOM(Software Bill of Materials) 精确记录整车每个节点的当前软件版本,加上原子化更新机制——多节点更新要么全部成功,要么全部回滚。这和分布式系统里的事务(Transaction)概念相同——但在车载环境里,CAN 总线上的 ECU 刷写速度可能只有几 KB/s,一个区域控制器的更新要几十分钟,期间如果用户启动车辆中断了更新,事务的回滚逻辑必须能处理这种"半完成"状态。保证原子性比在数据库里难一个数量级。
这四个挑战放在一起,构成了 SDV 开发模式转型的真实门槛。能做到 CI/CD 进车的公司,不是因为他们解决了这些问题——是因为他们有足够的工程资源,在每个问题上都建了一套专门的基础设施来应对它。 这些基础设施本身,就是 SDV 的隐性成本。
房间里的大象:ASPICE 还适用吗?
讲完 CI/CD 进车的四道墙,有一个更尖锐的问题不得不抛出来:整个汽车行业赖以运转的过程管理框架,是否还适用于 SDV?
ASPICE(Automotive SPICE)是汽车软件开发的过程能力评估标准,几乎所有 OEM 都用它来考核 Tier1 供应商的开发成熟度。它的骨架是 V 模型——左边需求逐层分解(系统需求 → 软件需求 → 软件架构 → 单元设计),右边测试逐层验证(单元测试 → 集成测试 → 软件测试 → 系统测试),每一层都要求严格的可追溯性文档:每条需求对应哪个设计、每个设计对应哪段代码、每段代码对应哪个测试用例。
这套体系在 HDV 时代完美运转——因为功能在 SOP 之前就定义完毕,瀑布式开发的节奏和 V 模型天然匹配。
但 SDV 的核心承诺是"出厂后继续进化"。OTA 每推送一次新功能,按 ASPICE 的逻辑,整个 V 的左半边(需求分析 → 架构设计 → 详细设计)和右半边(对应层级的测试 + 可追溯性文档更新)都要重新走一遍。如果你每两周推一次 OTA,每两周就要产出一套完整的 ASPICE 过程证据——这个文档量,可能比代码本身还重。
这不是在问"ASPICE 好不好",而是在问:一个为一次性交付设计的过程框架,能不能适配持续交付的工程节奏?
行业里有两种声音。一种认为 ASPICE 需要演进——保留可追溯性和过程纪律的内核,但把文档形式从"人工编写的 Word 文档"改成"从 CI pipeline 自动生成的过程证据",让合规性变成开发流程的副产品而不是额外负担。另一种声音更激进:ASPICE 的 V 模型假设了线性的开发流程,而 SDV 的开发本质是非线性的——你不可能在迭代开发里硬塞一个线性框架,需要的是一套全新的过程评估体系。
这个问题还没有答案。但它可能是 SDV 开发模式转型里最被低估的阻力——不是技术阻力,是制度阻力。
第四幕:谁在真正做,谁在被这件事做
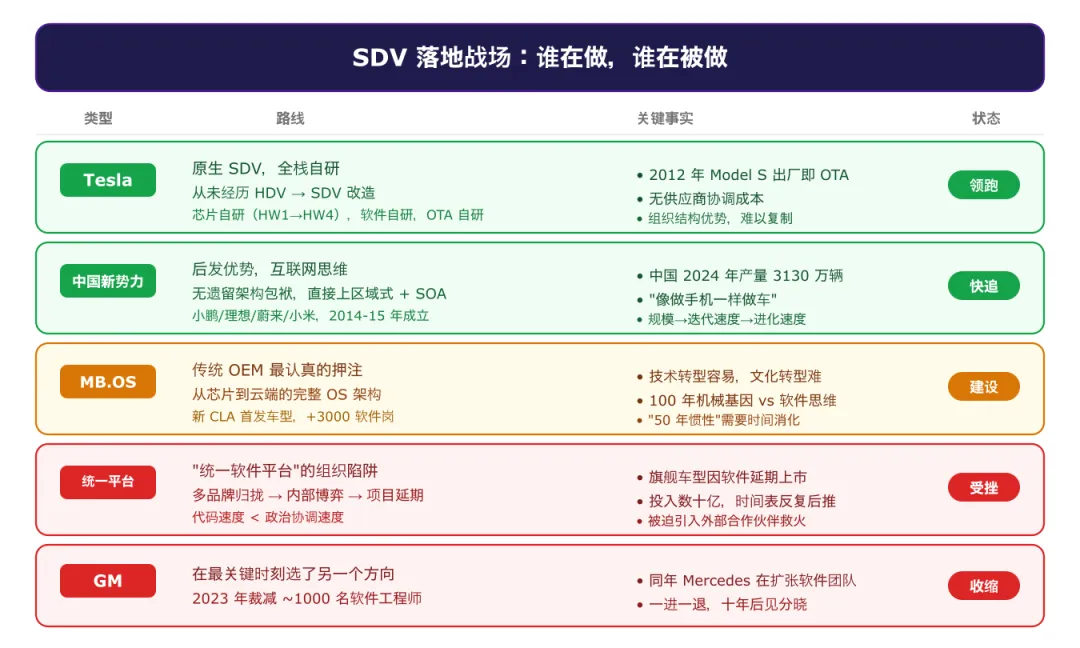
特斯拉:没有历史包袱的原生 SDV
2012 年,特斯拉 Model S 上市,出厂就有 OTA 能力(最初覆盖车机和信息娱乐系统,后逐步扩展到动力总成和自动驾驶模块)。那一年,传统车企的工程师们在想的问题还是"怎么通过蓝牙传地图数据"。
特斯拉不是从 HDV 改造成 SDV,而是从一开始就按 SDV 的逻辑设计。就像在白纸上画楼和在一栋建好的楼里改造装修——难度不在同一个数量级。
全栈自研是特斯拉 SDV 能力的来源:从自动驾驶硬件平台(HW1/Mobileye → HW2/NVIDIA → HW3 起自研 FSD 芯片 → HW4 第二代自研)、到操作系统、到自动驾驶软件栈、到云端训练基础设施,全部自己控制。
这里有一个细节很能说明问题:传统车企买了一颗 Tier1 的 ECU,里面的软件是黑盒,想改就要找供应商。特斯拉买的是芯片,软件是自己写的,想改什么直接改,OTA 推出去就是。没有供应商协调成本,没有接口谈判,没有认证周期里等供应商反馈的时间。
这不是技术优势,这是组织结构优势——而组织结构优势是所有优势里最难复制的那种。
行业里有一个广泛流传但难以验证的说法:同样实现 L2+ 辅助驾驶 + 整车 OTA + 座舱智能化,特斯拉的整车软件总量可能只有传统高端车型的几分之一——有人说是五分之一,有人说是十分之一,具体数字无从考证,因为没有任何一家车企会公开自己的代码行数。但这个方向性的判断是可信的:传统高端车有 150 个 ECU,每个 ECU 带一套独立的驱动层、中间件、AUTOSAR BSW 配置,大量代码是重复的基础设施;再加上几十年积累的历史兼容层(给上一代 CAN 协议做桥接、给已停产的传感器保留接口)。特斯拉的中央计算架构把功能集中在少数计算节点上,共享一套 OS 和中间件,没有历史包袱要兼容。代码行数的差距,不是功能差距的反映——而是架构代际差的投影。
中国新势力:后发优势的最好示范
小鹏、理想、蔚来,2014-2015 年先后成立。他们出现的时候,SDV 的概念已经成型,特斯拉已经证明了方向可行,但传统车企还没有反应过来。
后发优势的精髓:没有"50 年分布式 ECU 遗留架构"需要兼容,直接按区域式架构 + 中央计算平台 + SOA 的路线设计。
小米的工程师有一句话说得很直白:我们就像做手机一样做车。这不只是比喻,是字面意思——做手机的软件工程思维(快速迭代、CI/CD、用户反馈驱动功能演化),直接被带进了汽车开发流程。
中国 2024 年汽车总产量 3130 万辆,德国 410 万辆。这个体量意味着:中国新势力的 OTA 推送影响的用户基数更大,迭代反馈的数据量更大。规模决定迭代速度,迭代速度决定进化速度。 这不是口号——这是数学。
Mercedes-Benz MB.OS:传统 OEM 里最认真的押注
在传统 OEM 里,Mercedes-Benz 的 MB.OS 是迄今为止最认真的 SDV 架构投入。
MB.OS 的目标是建立从芯片到云端的完整 OS 架构——统一的软件平台,覆盖底层驱动到应用层全栈。新 CLA 是 MB.OS 的首发车型。Mercedes-Benz 为此新增了约 3000 个软件开发岗位(SemiEngineering 2025 年数据)。
但这里有一个传统 OEM 都面临的根本性挑战:从"买 Tier1 成品"到"自己写软件",技术转型相对容易,文化和组织转型才是真正的硬骨头。一家做了 100 年汽车的公司,工程师的核心竞争力在于机械和系统集成。SDV 要求他们"自己写软件"——这不只是换了一个技能,而是换了一种组织运作模式:代码评审文化、CI/CD 工具链、软件版本管理、测试自动化……这些在互联网公司是基础设施,在传统车企是需要从零建设的项目。
"统一软件平台"的组织陷阱
过去五年,不止一家传统汽车集团尝试过同一件事:成立一个独立的软件子公司,把集团旗下所有品牌的软件能力归拢到一个组织里,目标——打造统一的 SDV 软件架构。
逻辑听起来无懈可击:集中资源、消除重复开发、建立统一技术栈。
结果几乎如出一辙:项目延期,旗舰车型因为软件没准备好而推迟上市。有的集团不得不紧急引入外部合作伙伴——和新势力共享电子架构,和初创公司联合开发下一代平台。投入数十亿美元,时间表一再后推。
为什么这个模式反复失败?
因为"统一"面对的不是技术问题,而是组织博弈。
集团旗下每个品牌有自己的供应商体系、自己的遗留架构、自己的产品节奏、自己的利润中心考核。豪华品牌要的是差异化体验,走量品牌要的是成本控制,运动品牌要的是性能极限——这些需求在"统一平台"的框架下互相矛盾。
把几千名来自不同品牌的软件工程师聚在一起,不等于能做出统一的软件。每个品牌的 Tier1 供应商合同还有五年没到期,接口规范已经锁死,数据格式互不兼容。工程师在技术上想统一,但供应链合同和品牌 KPI 不允许统一。
写代码的速度,永远跑不过政治协调的速度。
一位资深行业分析师的评价很残酷但准确:拥有几十年历史的汽车集团,无法从零开始构建软件能力——不是因为工程师不行,而是因为组织惯性太大。SDV 要求的不只是技术能力,而是整个组织和决策结构的重建。这是很多有技术实力的公司做不到的事。
这不是某一家公司的故事,这是一个结构性困境:用组织合并来解决架构分裂,结果往往是制造了更复杂的组织分裂。
GM:在最关键的时刻选择了另一个方向
2023 年,通用汽车裁减了约 1000 名软件工程师。
这些人,本来应该是通用 SDV 转型的核心力量。
同一年,Mercedes-Benz 在扩张软件团队。
一进一退,方向不同。结果会在十年后的市场份额里体现出来。
第五幕:SDV 永远跑不完的账
SDV 的工程账单,没有结账那一天。
这是它和 HDV 最根本的不同——也是最容易被低估的不同。
HDV 的成本模型是明确的:设计阶段一次性投入,量产后摊销,整个生命周期的总成本在 SOP 那天基本可以算清楚。
SDV 的成本模型是另一种生物。
先看规模:一辆现代 SDV 的软件总量在 1-3 亿行代码。作为参考,Linux 内核约 2800 万行,一架 F-35 战斗机约 2400 万行。一辆高端 SDV 的软件复杂度,已经超过了人类造过的大多数单体工程系统。
这个规模带来一个铁律:维护成本随代码量超线性增长。不是代码多了一倍维护贵一倍,而是贵两到三倍——因为模块间的依赖关系是组合爆炸的。改一行代码,影响面分析要扫描的路径呈指数增长。每一次 OTA 都在加深这个复杂度——历史版本的兼容性维护成本在累积,每一次更改都要多花时间理解"这段代码背后的历史决策是什么"。
而且 SDV 有一个互联网软件没有的额外约束:你不能强制用户更新。路上同时跑着 v1.0 到 v3.7 的车,每个版本都要继续支持后端服务,每个新版本的接口都要向后兼容旧版本的区域控制器固件。这个兼容性矩阵——N 个软件版本 × M 个硬件平台代次 × K 个市场变体——是 SDV 技术债里最昂贵的一项,而且它只会随时间膨胀,永远不会收缩。
每一次硬件平台升级更是一场供应链的压力测试:整个软件栈要重新适配(驱动、中间件、AUTOSAR 配置),所有 Tier1 的模块要重新编译验证,所有基于旧平台做过的功能安全认证要在新平台上重跑。这不是一次性的迁移成本,而是每次平台代际更替都要付的账。
SDV 把传统汽车"出厂即定型"的一次性投入,变成了一种持续运营的基础设施。 你不是在卖一辆车,你是在启动一项长达十年的服务——而且这项服务的成本会随着软件规模增长而上升,随着用户期望提高而上升,随着竞争对手更新而上升。
Synopsys 的 Robert Serughetti 说过一句话,我认为是对 SDV 困难程度最准确的定性:"SDV 不是技术转型,而是组织和方法论转型。"
技术问题有答案。但组织转型是开放式的——它要求公司改变利益分配方式、改变决策流程、改变人才评价体系,甚至改变与供应商的合作模式。这些改变没有"做完了"的那一天,因为竞争对手在不断移动靶心。
如果有人告诉你 SDV 是一道解完就可以收工的题,他们要么没做过,要么在卖 PPT。
尾声:下一个问题,比 SDV 更难
SDV 解决了一件事:把汽车从"硬件定义、出厂封顶"变成了"软件定义、持续进化"。
但这里有一个还没有回答的问题:**"软件"是谁写的?**
在 SDV 的世界里,答案是人类工程师。他们写规则:如果左边有障碍物,往右偏;如果前方有行人,停车;如果车速超过 80 公里/小时,这个辅助变道功能自动启用。这些规则被编译成代码,推送到车上。
但在 2024 年,特斯拉发布了 FSD v12,然后发生了一件让工程师们自己都感到不安的事:
车做了一个正确的决定。在一个复杂的多车交汇路口,车顺畅地通过了。工程师复盘,找不到哪条手写的规则涵盖了这个场景。
因为 FSD v12 之后,"规则"不再是人类写的了。是神经网络从数百万个驾驶片段里训练出来的。中间过程是一个你无法打开、也无法用自然语言读懂的黑箱。
这是 SDV 进化到下一阶段的节点。当定义汽车行为的不再是人类写的软件,而是 AI 训练出来的模型,"软件定义汽车"这个概念本身,也开始被重新定义。
下一篇文章将讲 AI Defined Vehicle(AIDV):哪些已经发生,哪些是我们希望发生的,以及这件事为什么比 SDV 更难。
AIDV 的难,难在一个 SDV 从未遇到过的问题:
你无法证明你不懂的东西是安全的。
本文是"软件定义汽车"系列(下)。上篇:《从 HDV 到 SDV》;中篇:《SOA、OTA 和算力留白》。系列下一站:《AI 定义汽车》。
