 夜雨聆风
夜雨聆风加入星球,您能够第一时间获取
市场动态、政策解读、机构调研
助您做出更明智的投资决策
10W+机构调研资料等您获取

一、会议背景与目的
过去一年,国产大模型在模型能力、市场份额、商业化落地等方面取得显著进展。与此同时,海外头部模型(OpenAI、Anthropic、Google)也在快速迭代。为帮助投资者更好理解国产模型与海外的真实差距、国内竞争格局的演变、算力需求的驱动因素以及商业化盈利前景,行业专家围绕以下议题展开交流:
国产模型与海外模型的能力差距评估;
国内大模型竞争格局的变化趋势;
算力需求(尤其是推理算力)的驱动因素与持续性;
大模型公司的毛利率与盈利拐点判断;
DeepSeek V4、Happy House、Veo 4等热点模型的技术解读;
AI编程、端侧模型、SaaS与外包行业的影响。
二、国产模型与海外模型的能力差距
专家指出,评估差距需从两个角度区别看待:
1. 基本功能表现角度(差距较大)
海外“御用三家”(OpenAI、Anthropic、Google)各自拥有国内模型暂未对标的能力:
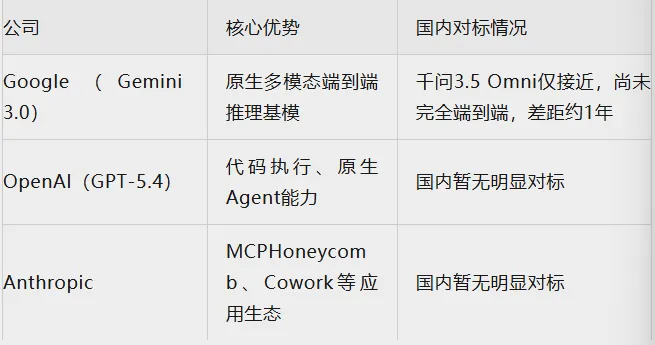
2. 模型对话表现角度(差距较小)
在理解力、遵循度、准确性等常规对话表现上,Kimi、智谱、千问等国内旗舰模型已基本达到GPT-4以上水平,部分接近GPT-5。
整体差距从去年的6~12个月缩小至约6个月。
结论:国产模型在基础对话能力上已快速追赶,但在多模态端到端、Agent生态、应用工具链等方面仍有明显差距。
三、国内竞争格局:垂类公司崛起,大厂加固护城河
1. 垂类模型公司(Kimi、智谱、MiniMax、阶跃星辰)
技术路线:快速复用DeepSeek等开源架构,站在“巨人肩膀”上迭代;
市场定位:优先触达C端和中小B端企业,2026年将是其在国内市场的“起量年”;
迭代节奏:预计Q2~Q3完成新一轮基模升级,下半年聚焦多模态、编程等能力提升。
2. 大厂(阿里、字节)
市场定位:优先服务大B端客户(手机、汽车、品牌厂商);
技术路线:自研为主,战线较广(基模、生图、生视频等),短期内成本难以下降;
关键节点:预计Q3~Q4推出类似Gemini 3的多模态基模,适配端侧场景。
3. 海外市场对比
美国市场格局相对稳定,御用三家各守优势领域;
Token出海成为国内模型对外输出的新模式,目前智谱做到完全标准化,其他公司毛利或链路尚未成熟。
四、算力需求:推理算力紧张将持续
1. 推理算力紧张的两大驱动
并发压力:国内模型服务集中在东八区4.5~5.5小时的高峰时段,瞬时并发量极大(如豆包日活过亿,并发超50万),对GPU需求呈几何级增长;
多模态需求:用户上传视频、图片等输入,Tokens量大幅增加,处理消耗显著上升。
2. 技术进步 vs 需求增长
DeepSeek等模型通过架构优化实现Tokens消耗下降,但仍无法抵消并发与多模态带来的需求增长;
推理算力紧张预计短期内不会缓解,且将扩散至北美市场(全球用户增长)。
五、毛利率与盈利拐点:中美路径不同
1. 海外模型:U型曲线
初期毛利率高(如OpenAI早期达70%);
快速迭代阶段毛利率下滑;
技术稳定后,通过应用层(Agent、缓存优化)实现毛利率回升。
2. 国内模型:斜线上升
垂类公司快速复用DeepSeek架构,迭代快但短期内毛利率难以上升,甚至可能小幅下降;
大厂(字节、阿里)自研路线战线广,成本压降需等待架构成熟与组织切换完成(预计2026年末~2027年初)。
结论:国内模型盈利拐点预计在2026年末至2027年初,届时基础大语言模型将进入“够用、稳定、低成本”阶段。
六、热点模型技术解读
1. DeepSeek V4
重新预训练:MHC论文表明模型从头训练,数据量大幅增长;
推理成本下降、速度提升,综合表现明显进步;
部署复杂度提高:可能导致官方API与三方平台表现出现差距;
V4 Pro版具备VLM能力(图像、网页理解),代码能力(尤其是动态界面、小游戏)将大幅提升;
国产卡适配:寒武纪590/690、昇腾950等原生支持DeepSeek的UE8M0精度,可实现每分钟2000 tokens以上的商用推理。
2. Happy House
优势:多人场景人像、流畅度、画面遵循度领先,在Arena榜单中表现突出;
不足:
音画同声成功率偏低;
不支持全模态参考(临摹式生成,非理解式);
不支持分镜;
绝对算力消耗不低(15秒视频单块H100约3分钟)。
定位:城市SUV vs 专业越野车(可灵、CogVideoX),功能不全的前提下油耗低,对比不对等。
3. Google Veo 4
预期功能:高清、长时长(1~2分钟以上);
关键判断:若不支持分镜,国产文生视频模型将在功能层面领先;
国内无法跟进4K模型,因算力不足。
七、AI编程:超预期但短期增长受限
1. 超预期之处
C端付费意愿和客单价超预期;
非头部互联网公司(北上广深非技术行业)采购预期提升。
2. 短期瓶颈
代码采纳率存在“水分”:规则型代码上一代IDE已有20%~25%替代率,AI coding仅补齐后端差距;
审核环节纯人工,导致一线代码生成快但审核慢,模型尚不能解决;
短期内采纳率难以本质提升,需等待审核自动化成熟。
八、端侧模型:上限明确,语音渗透率高
算力上限:端侧可部署模型约7B,极限10B(牺牲热量、电量);
能力边界:仅能解决日常基本指令,老人小孩使用困难;
车载领域:豆包语音模型市占率超80%(含特斯拉合同),推理模型多用DeepSeek;
图像处理:千问开源生图模型渗透率较高;
阶跃星辰:主动向下兼容,布局非通用大模型(行业MoE、算子下沉、硬件绑定),与其他公司差异化明显。
九、SaaS与外包行业:国内节奏慢于海外
国内特点:SaaS ToB服务较少,外包行业繁荣(软通动力、文思海辉等);
封闭数据壁垒:外包公司掌握行业脏活累活,数据高度封闭,大模型短期难以渗透;
可能的破局方式:模型公司收购外包公司,撬开封闭数据;
国内节奏慢于北美,需要更长时间。
十、海外头部公司人员扩张的逻辑
Honeycomb不是成熟产品,而是一种理念/方法论;
国内最佳实践:豆包Chatbot本身是一套Agent体系(步骤≥5步,工具丰富),模型能力排倒数但产品体验好;
OpenAI、Anthropic、DeepSeek、Kimi均在扩张Agent工程团队,逻辑是:
C端市场规模极大,延伸能力强;
B端客单价高,利润可观;
双向布局是合理选择。
十一、总结与展望
国产模型能力差距缩小:对话表现差距约6个月,但多模态、Agent生态差距仍明显。
竞争格局分化:垂类公司主攻中小B/C端,大厂主攻大B端,文生视频、生图、编程等细分领域各有机会。
推理算力紧张将持续:并发压力+多模态需求增长,技术进步难以完全对冲。
毛利率与盈利拐点:国内预计2026年末~2027年初进入稳定期,成本开始下降。
DeepSeek V4值得关注:重新预训练、VLM能力、国产卡适配,可能改变市场格局。
Happy House与Veo 4:各有优劣,国产文生视频在功能层面有机会领先。
AI编程短期有瓶颈,审核环节是卡点。
端侧模型上限明确,语音领域豆包领先,阶跃差异化布局。
国内SaaS/外包受冲击节奏慢于海外,但收购整合可能加速变化。
免责声明:本文由音频通过AI自动生成,内容仅供参考,不构成任何投资建议。市场有风险,投资需谨慎。
扫码领取100元优惠券

