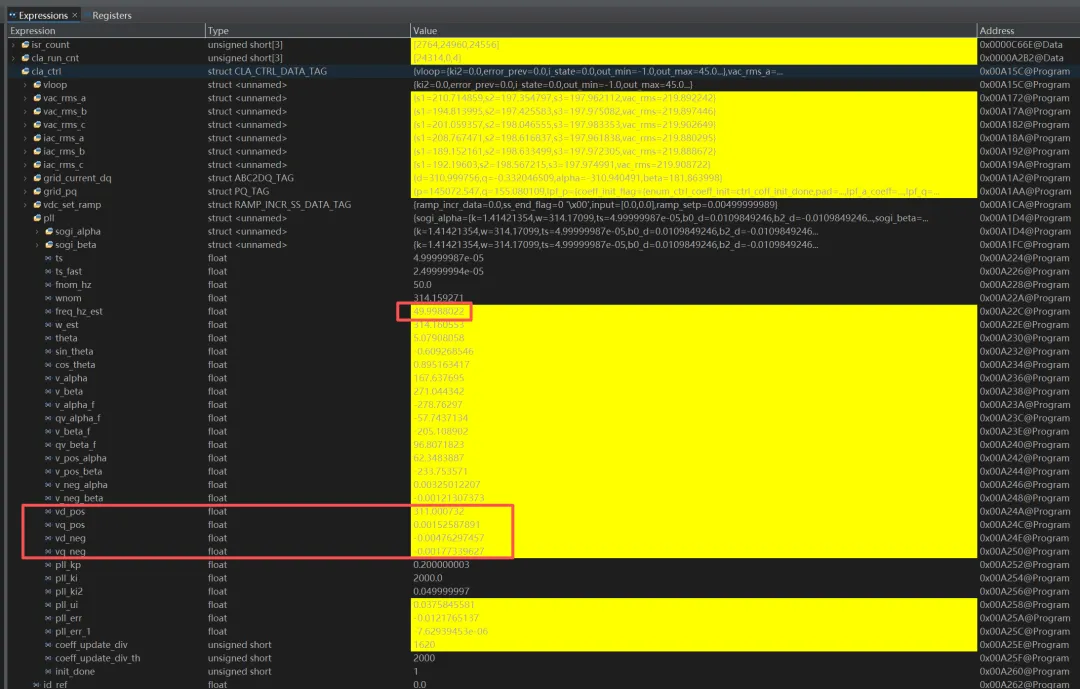
01为什么要折腾这个做三相整流器、Vienna PFC、并网逆变器,DDSOGI-PLL(Dual Second-Order Generalized Integrator PLL)几乎是标配锁相方案——相比 SRF-PLL 它能分离正负序,对电网不平衡和谐波都有更好的鲁棒性。但在 f280039c 这种 120MHz 单核 C28x 上,20kHz ISR 只给你 6000 个 cycle 的总预算。这 6000 cycle 里要塞下:PLL + Clarke + Park + 电流环 PI × 2 + SVPWM + 电压环 + 保护逻辑 + ADC 后处理……PLL 如果吃掉 120 cycle,就是总预算的 2%——听起来不多,但当你的电流环和 SVPWM 也各吃 80~100 cycle 时,每一个 cycle 都是在抢生存空间。这篇文章记录了我把 DDSOGI-PLL 中最密集的 Dual SOGI-QSG 模块从"人类友好的工程代码"一路优化到"CPU 友好的手工汇编"的完整过程。三个版本的完整代码都会贴出来,逐行解释每一步的收益和代价。02原版代码:结构体 + 指针 + 子函数先看完整的原版实现。这是非常标准的"工程师写法"——结构体封装所有状态,指针传递,子函数 cla_sogi_qsg_run() 封装 SOGI 计算,清晰、可调试、好维护:数据结构DDSOGI_PLL_t 结构体 — 原版Ctypedefstruct{ SOGI_QSG_t sogi_alpha; /* 内嵌子结构体, 又有 8 个 float */ SOGI_QSG_t sogi_beta; /* 第二路, 又 8 个 float */float32_t ts; /* 20kHz 采样周期 */float32_t ts_fast; /* 40kHz theta 更新周期 */float32_t fnom_hz;float32_t wnom;float32_t freq_hz_est;float32_t w_est;float32_t theta;float32_t sin_theta;float32_t cos_theta;float32_t v_alpha, v_beta;float32_t v_alpha_f, qv_alpha_f;float32_t v_beta_f, qv_beta_f;float32_t v_pos_alpha, v_pos_beta;float32_t v_neg_alpha, v_neg_beta; /* ← 负序, 很多场景用不到 */float32_t vd_pos, vq_pos;float32_t vd_neg, vq_neg; /* ← 负序 dq, 同上 */float32_t pll_kp, pll_ki, pll_ki2;float32_t pll_ui, pll_err, pll_err_1;uint16_t coeff_update_div;uint16_t coeff_update_div_th;uint16_t init_done;} DDSOGI_PLL_t;/* 总计: 2 × SOGI_QSG_t + 30+ 个 float + 3 个 uint16 * 结构体总大小轻松超过 64 word → 偏移超出 DP 页直接寻址范围 */20kHz 主函数cla_ddsogi_pll_run_20k() — 原版Cstaticinlinevoidcla_ddsogi_pll_run_20k(DDSOGI_PLL_t *p,float32_t va,float32_t vb,float32_t vc){/* Clarke */ p->v_alpha = PWR_CLARKE_ALPHA * (va - (0.5f * (vb + vc))); p->v_beta = PWR_CLARKE_BETA * (vb - vc);/* Dual SOGI-QSG — 两次子函数调用 */ cla_sogi_qsg_run(&p->sogi_alpha, p->v_alpha); // CALL #1 cla_sogi_qsg_run(&p->sogi_beta, p->v_beta); // CALL #2/* 读 SOGI 输出 → 写回结构体 (冗余搬运) */ p->v_alpha_f = p->sogi_alpha.d_out; // p-> 读 → p-> 写 p->qv_alpha_f = p->sogi_alpha.q_out; p->v_beta_f = p->sogi_beta.d_out; p->qv_beta_f = p->sogi_beta.q_out;/* 正序 / 负序分解 — 全部写回结构体 */ p->v_pos_alpha = 0.5f * (p->v_alpha_f - p->qv_beta_f); p->v_pos_beta = 0.5f * (p->qv_alpha_f + p->v_beta_f); p->v_neg_alpha = 0.5f * (p->v_alpha_f + p->qv_beta_f); // ← 很多场景不需要 p->v_neg_beta = 0.5f * (p->v_beta_f - p->qv_alpha_f); // ← 同上/* Park 变换 (正序 + 负序) */ p->vd_pos = (p->cos_theta * p->v_pos_alpha) + (p->sin_theta * p->v_pos_beta); p->vq_pos = -(p->sin_theta * p->v_pos_alpha) + (p->cos_theta * p->v_pos_beta); p->vd_neg = (p->cos_theta * p->v_neg_alpha) - (p->sin_theta * p->v_neg_beta); p->vq_neg = (p->sin_theta * p->v_neg_alpha) + (p->cos_theta * p->v_neg_beta);/* PLL PI */ p->pll_err = p->vq_pos; ui_step = p->pll_ki2 * (p->pll_err + p->pll_err_1); i_new = p->pll_ui + ui_step; w_raw = p->wnom + (p->pll_kp * p->pll_err) + i_new; p->w_est = cla_pll_clamp_f32(w_raw, CLA_PLL_W_MIN, CLA_PLL_W_MAX);/* 条件反饱和 */if(!((w_raw > CLA_PLL_W_MAX && p->pll_err > 0.0f) || (w_raw < CLA_PLL_W_MIN && p->pll_err < 0.0f))) { p->pll_ui = i_new; } p->pll_err_1 = p->pll_err; p->freq_hz_est = p->w_est * PWR_CONST_INV_TWO_PI;/* SOGI 系数自适应更新 (每 ~10ms) */ p->coeff_update_div++;if(p->coeff_update_div >= p->coeff_update_div_th) { ... }}数一下 p-> 的次数整个函数中 p->xxx 出现了 50+ 次。每一次在 C28x 上都编译为间接寻址 *+XAR4[offset]。当结构体偏移超过 63 word(这个结构体轻松超过),编译器还要插入额外的 ADD 指令来计算偏移。此外:两次 cla_sogi_qsg_run() 子函数调用各有 ~4 cycle 的 CALL/RET 开销;负序 dq 计算和回写在很多场景下完全不需要;SOGI 输出先写到子结构体再读出来写到父结构体——纯粹的数据搬运浪费。03四层性能开销拆解⛔ 开销来源① p-> 间接寻址 × 50+:每次 +1 cycle② 结构体 > 64 word:偏移需额外 ADD③ 子函数 CALL/RET × 2:~8 cycle④ 负序 dq + 冗余赋值:~15 cycle✅ 理想状态① DP 直接寻址 @_var:1 cycle② 同一 DP 页:零偏移计算③ 内联展开:零调用开销④ 只算/只写外部需要的总的来说,原版的性能开销主要不是"算法本身慢",而是数据搬运和寻址模式的开销远超计算本身。SOGI 的核心只是 4 次 FMAC + 2 次 FADD,但被结构体指针、函数调用、冗余赋值包裹了厚厚一层外壳。04第一轮优化:全局 static + 宏内联核心洞察:三相系统只需要一套 PLL。不需要多实例,也就不需要结构体和指针。变量定义:拆结构体为全局变量原版 — 结构体内嵌/* 全部塞在一个巨型结构体里 */DDSOGI_PLL_t g_pll;/* 访问方式: */p->sogi_alpha.d_outp->v_alpha_fp->vd_posp->pll_ui/* ... 每次 *+XAR4[n] 间接寻址 */优化版 — 全局 static/* SOGI 系数 (两路共用!) */staticfloat32_t gs_sogi_b0;staticfloat32_t gs_sogi_a1;staticfloat32_t gs_sogi_a2;staticfloat32_t gs_sogi_qb0;/* Alpha 路状态 */staticfloat32_t gs_sa_x1, gs_sa_x2;staticfloat32_t gs_sa_yd1, gs_sa_yd2;staticfloat32_t gs_sa_yq1, gs_sa_yq2;/* Beta 路状态 (同结构) */staticfloat32_t gs_sb_x1, gs_sb_x2;/* ... *//* PLL 核心 */staticfloat32_t gs_pll_sin, gs_pll_cos;staticfloat32_t gs_pll_w_est;staticfloat32_t gs_pll_vd_pos;/* 访问方式: @_gs_xxx 直接寻址 */SOGI 宏:零调用开销的内联计算SOGI_QSG_INLINE 宏 — 替代子函数C#define SOGI_QSG_INLINE(xn, d_out, q_out, \ _x1, _x2, _yd1, _yd2, _yq1, _yq2) \do { \/* d 路 (band-pass): 4 次乘加 */ \ (d_out) = gs_sogi_b0 * (xn) \ + gs_sogi_b2 * (_x2) \ + gs_sogi_a1 * (_yd1) \ + gs_sogi_a2 * (_yd2); \ \/* q 路 (quadrature): 4 次乘加 */ \ (q_out) = gs_sogi_qb0 * (xn) \ + gs_sogi_qb1 * (_x1) \ + gs_sogi_qa1 * (_yq1) \ + gs_sogi_qa2 * (_yq2); \ \/* 状态移位: 6 次赋值 */ \ (_x2) = (_x1); (_x1) = (xn); \ (_yd2) = (_yd1); (_yd1) = (d_out); \ (_yq2) = (_yq1); (_yq1) = (q_out); \} while(0)优化后的 20kHz 主函数ddsogi_pll_run_20k() — 优化版 (完整)CPLL_RAMFUNC PLL_ALWAYS_INLINEvoidddsogi_pll_run_20k(float32_t va, float32_t vb, float32_t vc){float32_t v_alpha, v_beta;float32_t da, qa, db, qb; /* SOGI 输出 → local auto → FPU 寄存器 */float32_t vpa, vpb;float32_tsin_t, cos_t; /* 一次读全局, 后续复用 local */float32_t vd_p, vq_p;float32_t err, ui_step, i_new, w_raw, w_out;/* ---- Clarke ---- */ v_alpha = PLL_CK_ALPHA * (va - 0.5f * (vb + vc)); v_beta = PLL_CK_BETA * (vb - vc);/* ---- Dual SOGI-QSG: 宏内联展开, 零函数调用 ---- */ SOGI_QSG_INLINE(v_alpha, da, qa, gs_sa_x1, gs_sa_x2, gs_sa_yd1, gs_sa_yd2, gs_sa_yq1, gs_sa_yq2); SOGI_QSG_INLINE(v_beta, db, qb, gs_sb_x1, gs_sb_x2, gs_sb_yd1, gs_sb_yd2, gs_sb_yq1, gs_sb_yq2);/* ---- 正序分解 (只算正序, 砍掉负序!) ---- */ vpa = 0.5f * (da - qb); vpb = 0.5f * (qa + db); gs_pll_vp_alpha = vpa; /* 仅写外部需要的 */ gs_pll_vp_beta = vpb;/* ---- Park (只对正序做) ---- */sin_t = gs_pll_sin; /* 一次全局读 → local */cos_t = gs_pll_cos; vd_p = cos_t * vpa + sin_t * vpb; vq_p = - sin_t * vpa + cos_t * vpb; gs_pll_vd_pos = vd_p; gs_pll_vq_pos = vq_p;/* ---- PLL PI (梯形积分 + 条件反饱和) ---- */ err = vq_p; ui_step = PLL_KI2 * (err + gs_pll_err_z1); i_new = gs_pll_ui + ui_step; w_raw = PLL_WNOM + PLL_KP * err + i_new;if (w_raw > PLL_W_MAX) { w_out = PLL_W_MAX; }elseif (w_raw < PLL_W_MIN) { w_out = PLL_W_MIN; }else { w_out = w_raw; }if (!((w_raw > PLL_W_MAX && err > 0.0f) || (w_raw < PLL_W_MIN && err < 0.0f))) { gs_pll_ui = i_new; } gs_pll_err_z1 = err; gs_pll_w_est = w_out; gs_pll_freq_hz = w_out * PLL_INV_TWO_PI;/* ---- SOGI 系数自适应 (低频路径, 不影响 hot-path) ---- */ gs_sogi_div_cnt++;if (gs_sogi_div_cnt >= PLL_SOGI_UPD_DIV_TH) { gs_sogi_div_cnt = 0u;constfloat32_t df = gs_pll_freq_hz - gs_sogi_freq_snap;if ((df >= 0.0f ? df : -df) >= PLL_SOGI_UPD_DELTA) { pll_sogi_calc_coeff(gs_pll_w_est, PLL_TS, PLL_SQRT2); gs_sogi_freq_snap = gs_pll_freq_hz; } }}关键差异逐条对比优化点 原版做法 优化版做法 节省数据访问 p->xxx 间接寻址 × 50+ @_gs_xxx 直接寻址 ~50 cycSOGI 调用 cla_sogi_qsg_run() × 2 SOGI_QSG_INLINE 宏 ~8 cycSOGI 系数 alpha/beta 各存一份 共用一份 RAM 省 8 word负序计算 v_neg_alpha/beta + vd/vq_neg 完全删除 ~10 cycSOGI→正序 先写结构体→再读出 直接用 local auto ~6 cycsin/cos 每次 p->sin_theta 一次读 → local 复用 ~2 cyc合计 ~120+ cycle ~64 cycle ~50%05算法层面:利用 SOGI 传函对称性在写汇编之前,先从数学上再压一刀。SOGI-QSG 的离散传函有天然的系数对称性,可以用加法/减法替代乘法:朴素写法 — 8 次 FMAC// d 路: 4 次乘法yd = b0*x[n] + b2*x[n-2] + a1*yd1 + a2*yd2// q 路: 4 次乘法yq = qb0*x[n] + qb1*x[n-1] + a1*yq1 + a2*yq2// 合计: 8 × MPYF32利用对称性 — 6 次 FMAC// d 路: b2 = -b0// → b0*(x[n] - x[n-2])yd = b0*(x[n]-x[n-2]) + a1*yd1 + a2*yd2// q 路: qb1 = qb0// → qb0*(x[n] + x[n-1])yq = qb0*(x[n]+x[n-1]) + a1*yq1 + a2*yq2// 合计: 6 × MPYF32// + 1 SUBF32 + 1 ADDF32每路省 2 次 MPYF32(在 C28x FPU 上 MPYF32/ADDF32/SUBF32 都是 1 cycle,但 MPYF32 + ADDF32 无法并行,而 SUBF32/ADDF32 可以在 delay slot 中被其他 MOV32 并行覆盖)。两路合计省 4 次浮点乘法。06第二轮优化:C28x FPU32 手工流水线汇编C28x FPU32 最强大的特性:MPYF32 和 MOV32 可以在同一个周期并行执行。语法是用 || 连接两条指令。MPYF32 的计算结果有 1 cycle 延迟——如果这个 delay slot 里什么都不做就要插 NOP。但如果塞一条不冲突的 MOV32 进去,就实现了零气泡流水线。这就是编译器最难做好的地方。它看到全局变量的交错读写依赖链时,往往保守地插入 NOP。手工汇编可以精确控制每一个 delay slot。完整汇编代码:Dual SOGI-QSGsogi_qsg_dual_asm.asm — 完整代码C28x FPU ASM; ============================================================; Dual SOGI-QSG 手工流水线汇编; 入口: R0H = v_alpha, R1H = v_beta; 输出: gs_sogi_da/qa/db/qb 四个全局变量; 所有变量在同一 DP 页 (linker ALIGN(64) 保证); ============================================================ .global _sogi_qsg_dual_asm .sect ".TI.ramfunc" .align 2_sogi_qsg_dual_asm: MOVW DP, #_gs_sogi_b0 ; 一次性设置 DP 页, 后续全部直接寻址 MOV32 R7H, R1H ; 保存 v_beta → R7H; =============================================; ===== ALPHA 路 d 路 (band-pass) =============; yd = b0*(xn - x2) + a1*yd1 + a2*yd2; ============================================= MOV32 R2H, @_gs_sa_x2 ; R2H = x2_a SUBF32 R4H, R0H, R2H ; R4H = xn - x2 ← ALU || MOV32 R2H, @_gs_sogi_b0 ; R2H = b0 ← 并行 load! MPYF32 R4H, R2H, R4H ; R4H = b0*(xn-x2) ← ALU || MOV32 R5H, @_gs_sa_yd1 ; R5H = yd1 ← 并行 load! MOV32 R2H, @_gs_sogi_a1 ; R2H = a1 MPYF32 R3H, R2H, R5H ; R3H = a1*yd1 ← ALU || MOV32 R6H, @_gs_sa_yd2 ; R6H = yd2 ← 并行 load! MOV32 R2H, @_gs_sogi_a2 ; R2H = a2 MPYF32 R5H, R2H, R6H ; R5H = a2*yd2 ← ALU || MOV32 R2H, @_gs_sa_x1 ; R2H = x1 (q 路要用) ← 并行 load! ADDF32 R4H, R4H, R3H ; R4H += a1*yd1 NOP ; 等 R4H 就绪 (依赖链极限, 无法消除) ADDF32 R4H, R4H, R5H ; R4H = d_out_a 完成! NOP ; d 路状态更新 MOV32 R3H, @_gs_sa_yd1 MOV32 @_gs_sa_yd2, R3H ; yd2 = yd1 MOV32 @_gs_sa_yd1, R4H ; yd1 = d_out MOV32 @_gs_sogi_da, R4H ; 输出: da; =============================================; ===== ALPHA 路 q 路 (quadrature) ============; yq = qb0*(xn + x1) + a1*yq1 + a2*yq2; ============================================= ADDF32 R3H, R0H, R2H ; R3H = xn + x1 ← ALU || MOV32 R5H, @_gs_sogi_qb0 ; R5H = qb0 ← 并行 load! MPYF32 R4H, R5H, R3H ; R4H = qb0*(xn+x1) ← ALU || MOV32 R5H, @_gs_sa_yq1 ; R5H = yq1 ← 并行 load! MOV32 R2H, @_gs_sogi_a1 MPYF32 R3H, R2H, R5H ; R3H = a1*yq1 ← ALU || MOV32 R6H, @_gs_sa_yq2 ; R6H = yq2 ← 并行 load! MOV32 R2H, @_gs_sogi_a2 MPYF32 R5H, R2H, R6H ; R5H = a2*yq2 ADDF32 R4H, R4H, R3H NOP ADDF32 R4H, R4H, R5H ; R4H = q_out_a 完成! NOP ; q 路状态更新 MOV32 R3H, @_gs_sa_yq1 MOV32 @_gs_sa_yq2, R3H MOV32 @_gs_sa_yq1, R4H MOV32 @_gs_sogi_qa, R4H ; 输出: qa ; x 状态移位 MOV32 R2H, @_gs_sa_x1 MOV32 @_gs_sa_x2, R2H ; x2 = x1 MOV32 @_gs_sa_x1, R0H ; x1 = xn; =============================================; ===== BETA 路 (结构完全相同) ================; ============================================= MOV32 R0H, R7H ; R0H = v_beta ; ---- beta d 路 ---- MOV32 R2H, @_gs_sb_x2 SUBF32 R4H, R0H, R2H || MOV32 R2H, @_gs_sogi_b0 MPYF32 R4H, R2H, R4H || MOV32 R5H, @_gs_sb_yd1 MOV32 R2H, @_gs_sogi_a1 MPYF32 R3H, R2H, R5H || MOV32 R6H, @_gs_sb_yd2 MOV32 R2H, @_gs_sogi_a2 MPYF32 R5H, R2H, R6H || MOV32 R2H, @_gs_sb_x1 ADDF32 R4H, R4H, R3H NOP ADDF32 R4H, R4H, R5H ; R4H = d_out_b NOP MOV32 R3H, @_gs_sb_yd1 MOV32 @_gs_sb_yd2, R3H MOV32 @_gs_sb_yd1, R4H MOV32 @_gs_sogi_db, R4H ; 输出: db ; ---- beta q 路 ---- ADDF32 R3H, R0H, R2H || MOV32 R5H, @_gs_sogi_qb0 MPYF32 R4H, R5H, R3H || MOV32 R5H, @_gs_sb_yq1 MOV32 R2H, @_gs_sogi_a1 MPYF32 R3H, R2H, R5H || MOV32 R6H, @_gs_sb_yq2 MOV32 R2H, @_gs_sogi_a2 MPYF32 R5H, R2H, R6H ADDF32 R4H, R4H, R3H NOP ADDF32 R4H, R4H, R5H ; R4H = q_out_b NOP MOV32 R3H, @_gs_sb_yq1 MOV32 @_gs_sb_yq2, R3H MOV32 @_gs_sb_yq1, R4H MOV32 @_gs_sogi_qb, R4H ; 输出: qb MOV32 R2H, @_gs_sb_x1 MOV32 @_gs_sb_x2, R2H MOV32 @_gs_sb_x1, R0H LRETR ; 返回 (~2 cycle)读汇编的方法关注每一行高亮的 || 并行指令对——这就是手工汇编的全部价值所在。每一对都是"算着上一步的结果,同时预加载下一步的操作数"。编译器在面对全局变量依赖链时,经常在这些位置插入 NOP,而手工汇编精确地用 MOV32 填满了每一个 delay slot。整个 alpha 路只剩 2 个不可消除的 NOP——它们是累加链的数据依赖极限。07寄存器分配策略详解C28x FPU32 有 R0H~R7H 共 8 个浮点寄存器。Dual SOGI 同时需要:输入值、4 个系数、6 个状态变量、累加中间结果。远超 8 个。关键是分时复用——用完的寄存器立即装入下一步的数据:寄存器 生命周期 内容R0H 整个 alpha 路 xn (v_alpha), 后半段被 x1 覆盖也无妨R1H 入口 → 第1条 v_beta, 立即搬到 R7HR2H 每步复用 系数暂存 (b0→a1→a2→qb0 轮流装入)R3H 每步复用 中间乘积 / 状态移位暂存R4H 累加器 d_out / q_out 最终结果R5H 每步复用 yd1/yq1/乘积暂存R6H 每步复用 yd2/yq2 暂存R7H 跨两路保持 v_beta (保存到 beta 路使用)R2H 是周转最频繁的寄存器——它在每个 MPYF32 之前被装入新系数,乘法完成后立即被下一个系数覆盖。这是 "load-use-discard" 模式,让 8 个寄存器足以覆盖所有数据。08Linker 配合:同一 DP 页直接寻址汇编中 @_gs_xxx 是 C28x 的 DP 直接寻址模式——把 6-bit 偏移 + DP 寄存器的 10-bit 页号拼成 16-bit 地址。前提是所有变量在同一个 64-word 页内。变量定义 + DATA_SECTION 放置C/* 所有变量放入 .sogi_data 段 */#pragma DATA_SECTION(gs_sogi_b0, ".sogi_data")#pragma DATA_SECTION(gs_sogi_a1, ".sogi_data")#pragma DATA_SECTION(gs_sogi_a2, ".sogi_data")#pragma DATA_SECTION(gs_sogi_qb0, ".sogi_data")#pragma DATA_SECTION(gs_sa_x1, ".sogi_data")#pragma DATA_SECTION(gs_sa_x2, ".sogi_data")/* ... alpha 路 6 个, beta 路 6 个, 输出 4 个 */float32_t gs_sogi_b0 = 0.0f;float32_t gs_sogi_a1 = 0.0f;/* ... */Linker CMD 段放置Linker CMDSECTIONS{ .sogi_data : > RAMLS0, ALIGN(64), PAGE = 1}/* 变量统计: * 系数 4 × 2 word = 8 word * alpha 6 × 2 word = 12 word * beta 6 × 2 word = 12 word * 输出 4 × 2 word = 8 word * 合计 40 word < 64 word DP 页限制 ✓ * * ALIGN(64) → 段起始对齐到 64-word 边界 * → 40 word 数据一定落在同一 DP 页内 * → 汇编入口只需一条 MOVW DP */09C 端集成:怎么在 ISR 里调用汇编20kHz ISR 调用方式C/* 头文件声明 */externvoid sogi_qsg_dual_asm(float32_t v_alpha, float32_t v_beta);externfloat32_t gs_sogi_da, gs_sogi_qa, gs_sogi_db, gs_sogi_qb;/* 在 20kHz ISR 中 */voidddsogi_pll_run_20k(float32_t va, float32_t vb, float32_t vc){float32_t v_alpha, v_beta;/* Clarke */ v_alpha = PLL_CK_ALPHA * (va - 0.5f * (vb + vc)); v_beta = PLL_CK_BETA * (vb - vc);/* ★ Dual SOGI-QSG — 汇编版, ~24 cycles (含 CALL/RET) */ sogi_qsg_dual_asm(v_alpha, v_beta);/* 直接读全局输出, 零指针, 零结构体 */float32_t vpa = 0.5f * (gs_sogi_da - gs_sogi_qb);float32_t vpb = 0.5f * (gs_sogi_qa + gs_sogi_db);/* Park + PLL PI 不变 (C 代码, 编译器 -O2 足矣) ... */}10全景:20kHz ISR 一拍的完整执行链Clarke ~6c→SOGI-α (ASM) ~10c→SOGI-β (ASM) ~10c→正序分解 ~4c→Park ~6c→PLL PI ~12c只有最密集的 Dual SOGI 用汇编。Clarke、正序分解、Park、PLL PI 仍然是 C——它们各只有 2~6 次 FMAC,编译器 -O2 就能处理得很好。不要为了汇编而汇编,只在热点上动刀。11三版 Cycle 对比总表模块 原版 struct+ptrC 全局+宏 ASM 版Clarke ~8 (含 p-> 写) ~6 ~6 (C)单路 SOGI 计算 ~18 ~12 ~10双路 SOGI 合计 ~36 ~24 ~20SOGICALL/RET ~8 (两次) 0 (内联) ~4 (一次)SOGI→结构体搬运 ~8 0 0正序分解 ~8 (含 p->) ~4 ~4 (C)负序分解 + Park ~12 0 (砍掉) 0Park (正序) ~8 (含 p->) ~6 ~6 (C)PLLPI + clamp ~14 (含 p->) ~12 ~12 (C)p-> 间接寻址累计 ~50+ 0 020kHz 总计 ~120+ ~64 ~60⚠ 必须实测上表为基于 C28xFPU32 指令手册的理论估计。实际 cyclecount 受 Flashwait-state(RAMFUNC 可消除)、pipelinestall、prefetchmiss、DP 页是否命中等因素影响。建议用 CpuTimer0 在 ISR 入口/出口打点实测。所有数字都标注为"估计",不宣称"已验证"。12每一层优化的代价优化层 收益 代价 适用场景全局变量 ~50 cycle 丧失多实例, 可读性下降 单例模块 (PLL, SVPWM)宏内联 ~8 cycle 无法单步调试子函数 ISR 内所有 hot-path 函数砍负序 ~10 cycle 需确认不用负序补偿 不做不平衡补偿时对称性利用 ~4 cycle 代码可读性略降 任何 SOGI 实现手工汇编 ~4 cycle + 确定性 可移植性为零, 维护极难 cycle 预算极紧 / 功能安全注意:从 C 全局版到汇编版,绝对收益只有 ~4 cycle。汇编的核心价值不在于"更快几个 cycle",而在于确定性——无论编译器版本怎么升级、优化选项怎么改,cyclecount 锁死不变。对于要做 worst-casetiming 分析的场景很有价值。投入产出比最高的是第一轮——全局变量替代结构体。只改数据定义方式,不动算法,就拿下了 50% 的优化空间。剩下的汇编优化是锦上添花。13附:40kHztheta 积分 (C 版足矣)ddsogi_pll_theta_run_40k() — 完整CPLL_RAMFUNCPLL_ALWAYS_INLINEvoidddsogi_pll_theta_run_40k(void){float32_t th = gs_pll_theta; th += gs_pll_w_est * PLL_TS_FAST;/* wrap [0, 2π) */if (th >= PLL_TWO_PI) { th -= PLL_TWO_PI; }elseif (th < 0.0f) { th += PLL_TWO_PI; } gs_pll_theta = th;/* sin/cos: per-unit 角度调 CLA 内置函数 */constfloat32_t th_pu = th * PLL_INV_TWO_PI; gs_pll_sin = CLAsinPU(th_pu); gs_pll_cos = CLAcosPU(th_pu);}/* 约 10~15 cycles, 不值得写汇编: * - 只有 1 次 MPYF32 + 1 次 ADDF32 + 2 次 sin/cos 查表 * - 编译器完全能处理 * - 如果跑在 CPU 上, CLAsinPU/CLAcosPU 需替换为 * __sinpuf32() / __cospuf32() intrinsic */收藏清单:C2000 ISR 极限优化方法论1单例模块用全局变量替代结构体指针。PLL、SVPWM、保护状态机——全系统只需一套的模块,不需要指针间接寻址。这是投入产出比最高的优化,改数据定义就能拿下 ~50% 性能。2利用传函对称性减少乘法。b2 = -b0 → SUBF32 替代 MPYF32;qb1 = qb0 → ADDF32 替代 MPYF32。数学等价,零数值误差。这个技巧对任何 IIR 滤波器都适用——检查你的系数矩阵有没有对称/反对称。3MPYF32 || MOV32 并行填充 delay slot。这是 C28x FPU 手工汇编的全部核心——每条浮点 ALU 指令的 1-cycle 延迟里塞一条 MOV32 预加载。消灭一个 NOP = 免费提速一个 cycle。4DATA_SECTION + ALIGN(64) 保证同一 DP 页。20 个 float32 = 40 word,远小于 64 word 限制。一条 MOVW DP 设置好页号,后续全部 @_var 直接寻址。如果变量散落在多个 DP 页,每次切换多一条指令。5只在热点写汇编,其余保持 C。Clarke/Park/PI 各只有几次 FMAC,编译器 -O2 足矣。Dual SOGI 是 20+ 次 ALU 的密集计算核,值得手写。投入产出比决定优化边界——你的时间也是 cycle。6砍掉不需要的计算比优化计算本身更有效。原版算了完整的正负序分解 + 负序 Park 变换。如果你的场景不做不平衡补偿,直接砍掉负序 → 省 ~10 cycle,比任何指令级优化都立竿见影。7所有 cycle 数必须实测。用 CpuTimer0 在 ISR 入口/出口打点,读 TIMH:TIM 差值。不要相信任何纸面数字——包括本文的。Flash wait-state、pipeline stall、prefetch miss 都会让理论值失真。
 夜雨聆风
夜雨聆风