 夜雨聆风
夜雨聆风点击上方蓝字关注我们



技巧介绍

本方案的核心逻辑是“机器打标为主、人工校验为辅、规则持续进化”,通过四层能力协同实现高效精准的数据分级分类:
数据扫描工具:数据安全管理平台内置扫描工具,支持全库/增量扫描,自动识别数据资产并输出分级分类标签。
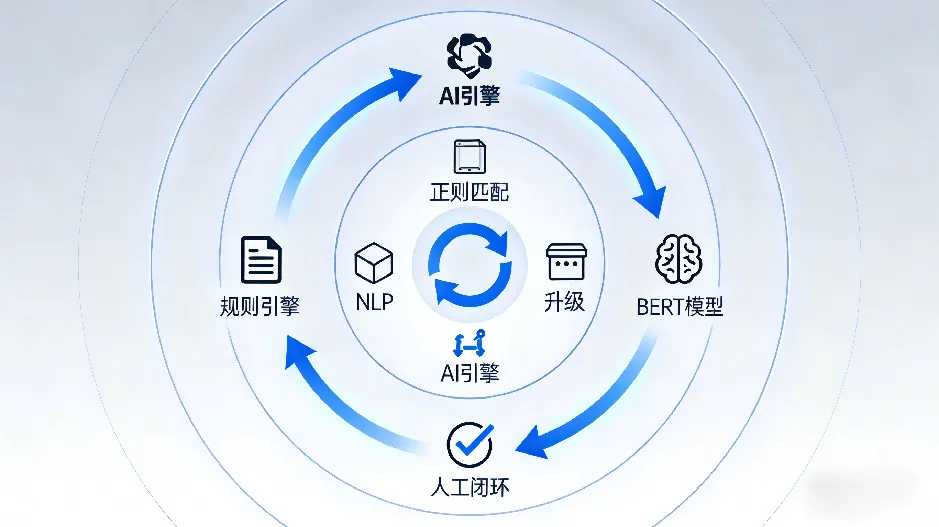

操作步骤


步骤一
规则引擎初筛——快速覆盖已知敏感类型
操作要点:
1. 登录鲸象数据安全管理平台,进入【系统配置】-【模板管理】-【规则配置】模块
2. 逐一选中分类中需要关联敏感规则
3.根据业务特点,补充自定义规则(如核心网资源、设备编码等)
4.启动全库扫描任务,等待系统自动打标
预期效果:可覆盖80%以上的常见敏感字段,快速建立数据资产基线。

步骤二
AI引擎增强——识别隐含敏感与复杂场景
操作要点:
1. 配置BERT/ERNIE模型参数(建议使用平台预训练模型)
2. 创建打标任务
3.针对以下场景重点启用AI识别:
•语义模糊字段:如“contact”可能是手机号也可能是邮箱
•跨表关联推理:通过外键关联识别间接敏感数据
•非结构化数据:日志、文本字段中的敏感信息提取
4.运行AI增强扫描,下载打标结果
预期效果:补充规则引擎盲区,识别率提升10-15%。

步骤三
人工复核闭环——按优先级精准校验
操作要点:
1. 进入【人工校验平台】,查看待复核任务列表
2. 按敏感级别排序(建议顺序:核心数据→重要数据→一般数据)
3.使用文件对比工具,逐项核对机器打标结果:
✓ 确认正确的标签,一键通过
✗ 标记错误的标签,选择正确级别并记录原因
⚠ 存疑项加入待讨论列表
4.对高频错误类型,直接在复核界面发起规则修正申请
复核技巧:
优先处理AI置信度低于0.8的字段
关注跨系统同名不同义的字段(如“user_id”在不同表含义可能不同)

步骤四
持续迭代优化——让系统越用越准
操作要点:
1. 每周导出复核报告,统计错误类型分布
2. 将高频错误转化为新规则或训练样本:
•规则类错误 → 在规则平台新增/修正规则
•AI类错误 → 提交至模型训练样本库
3.每月执行一次模型重训,更新AI引擎
4.建立“复核-反馈-优化-验证”的完整闭环

迭代节奏建议:
使用误区
注意事项

适用范围
本方案适用于运营商数据资产分级分类场景,特别是数据库表、数据仓库、大数据平台等结构化数据。

使用限制
AI引擎对非结构化文本(如图片、音频)识别能力有限
加密字段需先解密或配置解密规则后再扫描
历史遗留系统元数据缺失时,需人工补充字段注释

操作要点
首次扫描建议先在测试环境验证规则准确性
自定义规则需经过评审后再上线,避免规则冲突
核心数据(4级)必须100%人工复核
定期备份规则配置,防止误操作导致规则丢失

成效/案例

某省运营商实践案例

背景
该运营商数据资产超过2万张表,人工分级分类耗时6个月仍未完成,且效果一般。

实施方案
启用平台内置100+规则,2周完成初筛
AI引擎增强识别,补充发现3000+隐含敏感字段
人工按L4→L3→L2→L1优先级复核,集中人力在重要数据
建立月度迭代机制,持续优化规则库

实施效果
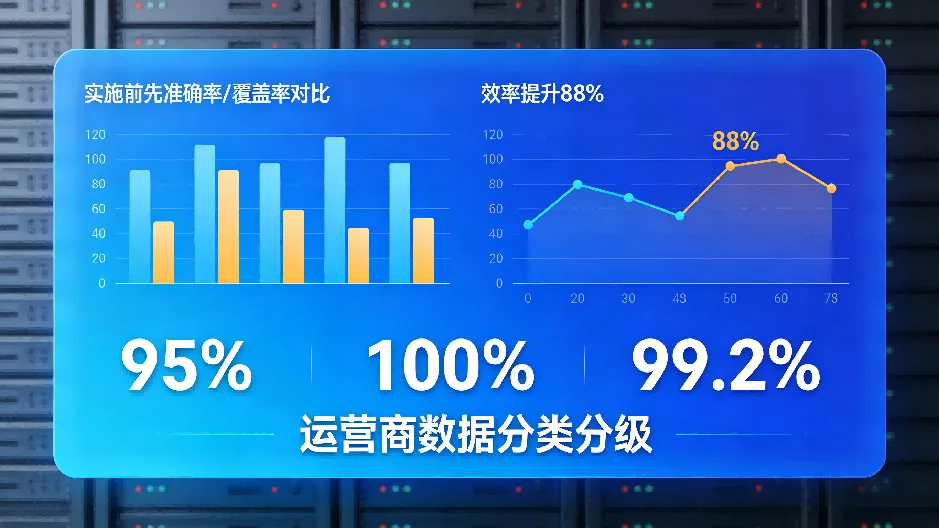

总结

运营商数据分级分类准确率提升的核心在于“四位一体”协同。

使用建议
初期:重点投入规则配置,建立基础能力
中期:引入AI增强,扩大识别覆盖面
长期:建立迭代机制,实现自动化运营
数据分级分类不是一次性项目,而是持续运营的过程。通过工具+流程+人的有机结合,才能实现准确率与效率的双重提升。
4月主题-AI赋能安全防护新路径
【鲸象知识库】利用AI,只需四步就可快速提升数据分类分级准确率,你相信吗?
【知识科普】AI赋能安全防护新路径,这些核心问题一次性说清!

END


点个在看,你最好看

