 夜雨聆风
夜雨聆风🎬 先看效果:不是角色扮演,是思维框架
4月5日,B站UP主花叔(前称花生)在GitHub上开源了nuwa-skill,取名"女娲"——神话里女娲造人,这里造的是"数字思维体"。
问"普通人怎么在AI时代赚钱",ChatGPT扮演的乔布斯会给你一份标准答案。但加载了蒸馏skill的AI会直接打断你——"Stop,你的问题本身就有问题"。

这种差别在哪?
角色扮演调用的是模型训练时见过的"统计平均值",本质上是安全的平庸。
而蒸馏skill试图从一手材料(著作、访谈、社交媒体、他人评价、决策记录、时间线)里提取五个层面的东西:心智模型、决策启发式、表达DNA、核心专利、知识边界。
目前已有的17个skill包括乔布斯、芒格、费曼、马斯克、纳瓦尔、Karpathy、Ilya、保罗·格雷厄姆、张雪峰、罗永浩等,全部MIT协议开源免费。
但我们在看文档时注意到一个关键限定:项目README明确写着,"如果蒸馏的人比较没名气,最好自己准备本地资料喂给女娲skill"。这意味着公开资料越丰富的人,蒸馏效果越好;普通人可能面临冷启动难题。
🧠 五阶段流水线:从调研到交付
视频演示里,蒸馏罗永浩的全过程被拆成五个阶段,文档标注总耗时约半小时。
第一阶段:6个Agent并行调研
输入名字后,系统同时启动6个维度的agent:著作与系统性思考、长对话与即兴思考、表达DNA和碎片化风格、他者视角与批评、决策记录与行动、人物时间线。每个agent从40多个一手来源收集信息,还会自动发现人物身上的矛盾点。
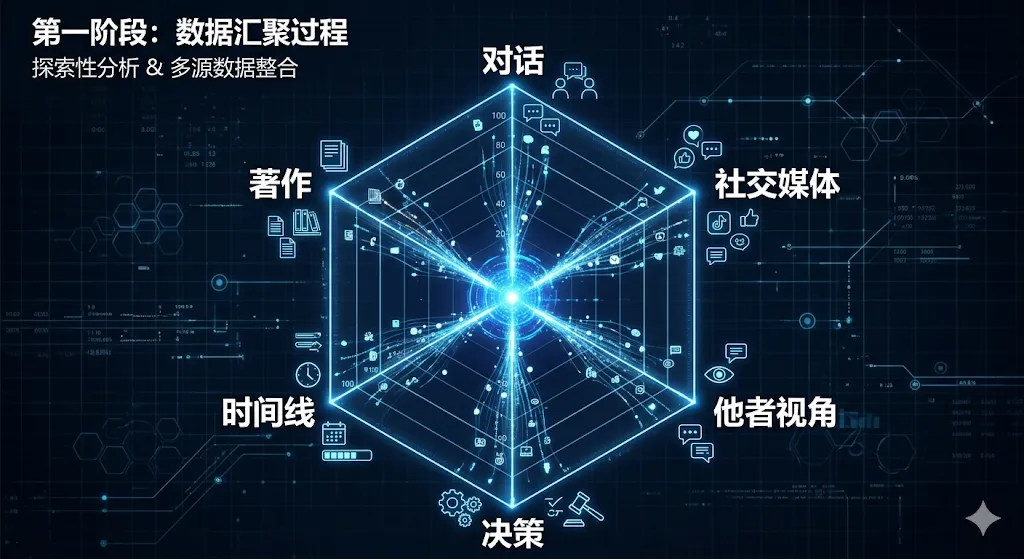
第二阶段:框架提炼
从材料里提取心智模型、决策启发式、表达DNA、核心专利、知识边界。以罗永浩为例,文档展示的6个心智模型包括"理想主义实用化"、"道德制高点战术"、"折腾者哲学"等。
第三阶段:构建SKILL.md
把提炼结果写成结构化的SKILL.md文件,这是最终产物。AI读取后就能"加载"这个人的思维方式。
第四、五阶段:验证与精炼
跑三种测试(已知信息测试、边缘化测试、风格化测试),不通过就自动修正重跑。最后双agent做进一步优化。
🔍 同一个问题,问不同的人
视频里展示了一个有趣的用法:切换不同蒸馏人物回答同一个问题。
问:"普通人对AI焦虑,怕失去工作,怎么办?"
罗永浩模式:"大多数人以为AI会让人失业,其实AI会让不愿意折腾的人失业。焦虑说明还有感知力,但焦虑完了得行动。别学AI知识,学怎么用AI干活。"
切换到纳瓦尔模式:"老罗说的对,但只说对了一半。恐惧的本质不是AI太强,是你自己太容易被替代。要区分手册化的工作和判断力的工作。判断力工作需要特定领域知识、独特经验、品味和直觉的交叉点,AI替代不了。"

【疑问:版权问题边界在哪?】
原文章评论区有人问"会不会有版权问题",这也是我们在看文档时的疑问。SKILL.md里会引用SEC起诉文件、Bloomberg报道等二手来源,但使用这些素材生成商业可用的skill,版权归属如何界定?文档提到MIT协议开源,但没提素材本身的合规边界。
💰 怎么玩?
项目命令行安装方式很简洁:
npx skills add alchaincyf/nuwa-skill
直接用自然语言交互:"蒸馏一个罗永浩"、"用芒格的视角帮我分析这个投资决策"。只要你的AI编程工具接入的模型不太差,自然语言就够了。
🤔 我们在讨论什么?
花叔的前作出圈作品是"小猫补光灯"——用Cursor一个半小时做出来的iOS App,冲到App Store付费榜Top1。
他做nuwa-skill的思路和做小猫补光灯一样:找到真实需求,用AI快速实现,完全开源。
这个需求是真实的吗?
评论区出现了两种声音:一种觉得"非常有意思",想"蒸馏花叔给我写下一个爆款";另一种质疑"净蒸馏些没用的东西"、"都是噱头,死人和活人的回答肯定不一样"。
我们注意到一个有趣的细节:项目创建8天,GitHub上已经出现"anti-distill"(反蒸馏skill)和"immortal-skill"(数字永生框架)等衍生项目,形成了一种"回应性开发生态"。这很像OpenClaw早期的发展路径——一个核心创意引发一堆实验性fork。
💬 来社区聊聊
看完文档,你觉得nuwa-skill最适合什么场景?

