 夜雨聆风
夜雨聆风Cosmos-Transfer1是英伟达提出的基于扩散模型的条件化世界生成模型,核心能力是接收分割、深度、边缘等多种空间模态控制信号,生成高度可控的世界模拟视频,主要服务于机器人Sim2Real、自动驾驶数据增强等物理AI场景,同时实现了实时推理生成。
研究背景与问题
- 多模态可控世界生成需求
物理AI领域(机器人、自动驾驶)需要大量逼真、可控的仿真数据,但传统CG仿真器生成的内容与真实世界存在明显的仿真到真实(Sim2Real)域间差距,直接用仿真数据训练的模型难以落地到真实场景。 - 现有技术局限
传统扩散模型的空间控制能力有限,单一模态控制只能约束视频的某一特征,无法实现空间-时间维度的精细化自适应控制,也不能灵活融合多种模态信号,生成结果的可控性与多样性难以平衡。
基于此,Cosmos-Transfer1的核心目标:构建自适应多模态控制的世界生成模型,在保留场景结构、语义、几何信息的同时,缩小仿真与真实的差距,实现高质量、可控、多样化的世界视频生成。
基础技术铺垫
讲解方法前,先明确两个核心基础组件,这是理解模型的关键:
- DiT扩散模型
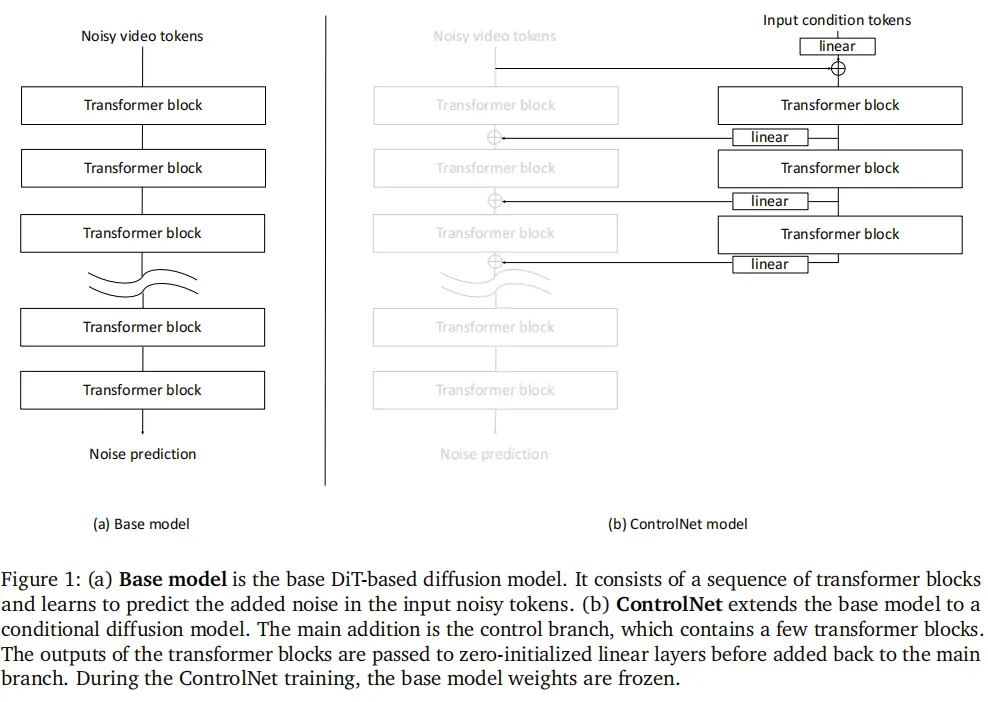
以Transformer为降噪器的扩散模型,核心是输入带噪声的视频token,预测噪声并逐步去除,最终生成清晰视频。结构上由一系列Transformer块组成,负责学习噪声预测规律。 - DiT版ControlNet
把传统面向UNet的ControlNet迁移到DiT架构,在基础DiT模型上增加控制分支:控制分支接收条件信号(如边缘、深度),训练时基础模型权重冻结,只优化控制分支;控制分支的输出经过零初始化线性层后,回加到主模型的对应Transformer块,实现条件控制。
模型方法核心原理
Cosmos-Transfer1是在英伟达已有模型Cosmos-Predict1基础上,通过多模态控制分支+时空自适应权重映射改造而来,整体分为三大核心设计:
(一)多模态独立控制分支设计
- 分支搭建逻辑
模型为每一种控制模态(模糊视觉、边缘、深度、分割;自动驾驶场景还有高清地图、激光雷达)单独搭建一个ControlNet控制分支,N种模态就对应N个独立分支。
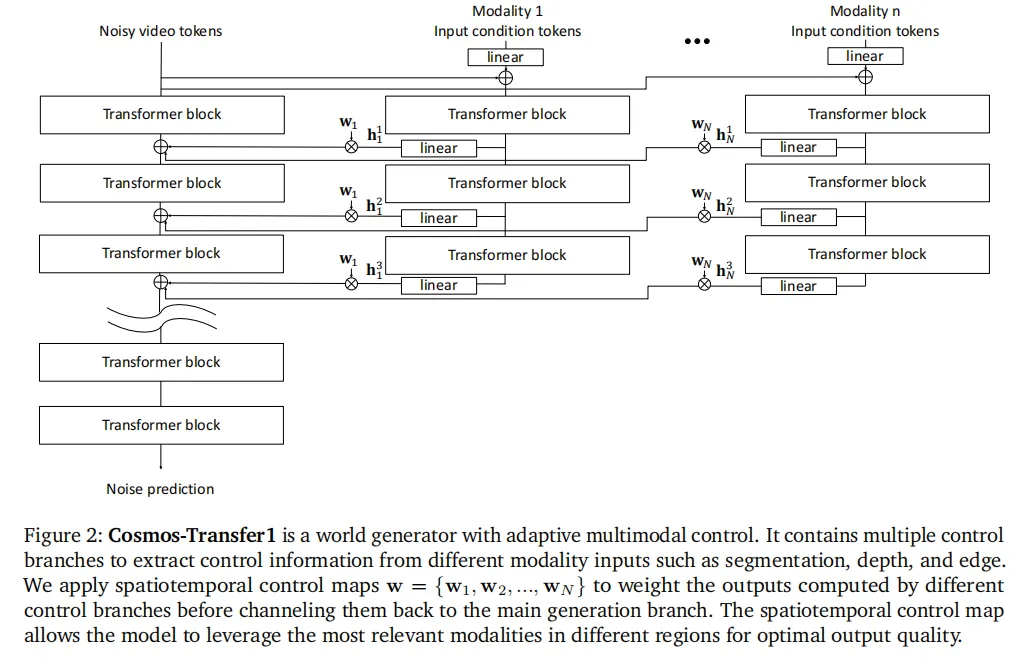
- 训练与融合策略
训练阶段:每个分支单独训练,不用同时加载所有分支,大幅降低内存占用,不同模态还能使用不同数据集训练,适配数据获取难度不同的场景。 推理阶段:把所有训练好的分支动态融合,可随时添加或移除模态,灵活性极高。
- 分支结构细节
每个控制分支包含3个Transformer块,权重从基础DiT模型对应块继承,输出经过零初始化线性层后,准备接入主生成分支(对应图1(b)的ControlNet结构)。
(二)时空自适应控制映射(核心创新)
这是模型实现精细化控制的关键,解决“不同位置、不同时间,让不同模态发挥不同影响力”的问题。
- 什么是时空控制映射
定义一个四维映射  ,其中N是模态数量,X、Y是视频宽高,T是帧数。这个映射的作用是:给每一个模态、每一个像素位置、每一帧,分配一个控制权重。
,其中N是模态数量,X、Y是视频宽高,T是帧数。这个映射的作用是:给每一个模态、每一个像素位置、每一帧,分配一个控制权重。 - 权重作用规则
权重越高,该模态在这个位置、这一帧对生成结果的影响越大;权重和超过1时自动归一化,保证控制稳定。 - 具体实现方式
把每个控制分支每个Transformer块的输出特征  ,和对应模态的时空权重
,和对应模态的时空权重 做逐元素相乘,再把加权后的特征回加到主生成分支(对应图2的自适应多模态ControlNet结构)。
做逐元素相乘,再把加权后的特征回加到主生成分支(对应图2的自适应多模态ControlNet结构)。 - 权重获取方式
手动设计:直接指定前景、背景的模态权重。 启发式规则:根据场景特点自动分配。 神经网络预测:用额外模块学习生成权重。
(三)模态定义与适配设计
模型针对通用场景和自动驾驶场景,定义了不同的控制模态,适配不同任务需求:
- 通用场景模态
模糊视觉(Vis):对输入视频做双边模糊,保留整体颜色与轮廓,适合调整纹理细节。 边缘(Edge):提取Canny边缘,保留场景结构,给模型更多生成自由度。 深度(Depth):用DepthAnything2计算深度图,严格保留场景3D几何结构。 分割(Seg):用GroundingDINO+SAM2提取分割掩码,保留场景语义布局。

- 自动驾驶专属模态
高清地图(HDMap):包含车道、路标、交通灯等精确道路标注,保留道路布局。 激光雷达(LiDAR):对激光雷达数据做插值、投影处理,保留场景3D语义细节。

- 超分分支
额外训练4KUpscaler控制分支,把720p生成视频放大到4K,采用分块生成+重叠区域平均,保证视频无缝衔接(对应图5)。

(四)提示词上采样器
为了让简短的用户提示匹配模型训练时的详细提示分布,训练了Pixtral-12B模型作为提示词上采样器:输入简短提示+条件视频,输出细节丰富、符合训练分布的长提示,保证生成效果与用户意图一致。
实验验证与效果
(一)评估数据集与指标
- TransferBench评估集
:包含机器人操作、自动驾驶、日常场景三类共600个样本,覆盖物理AI核心场景。 - 核心评估维度
控制一致性:模糊SSIM、边缘F1、深度si-RMSE、分割mIoU,衡量生成结果与控制信号的匹配度。 多样性:Diversity-LPIPS,衡量相同控制信号下不同提示的生成差异度。 整体质量:DOVER分数,衡量视频视觉美观度。
(二)关键实验结论
- 单模态vs多模态
单一模态控制在对应指标上表现最优(如Vis模态模糊SSIM最高),但整体质量低;多模态均匀权重融合能平衡各模态优势,整体质量得分最高。 - 时空自适应控制效果
前景用Vis、Edge模态(高约束,保留细节),背景用Depth、Seg模态(低约束,提升多样性),能实现“前景精准保留、背景自由生成”的效果(对应图6、图7)。
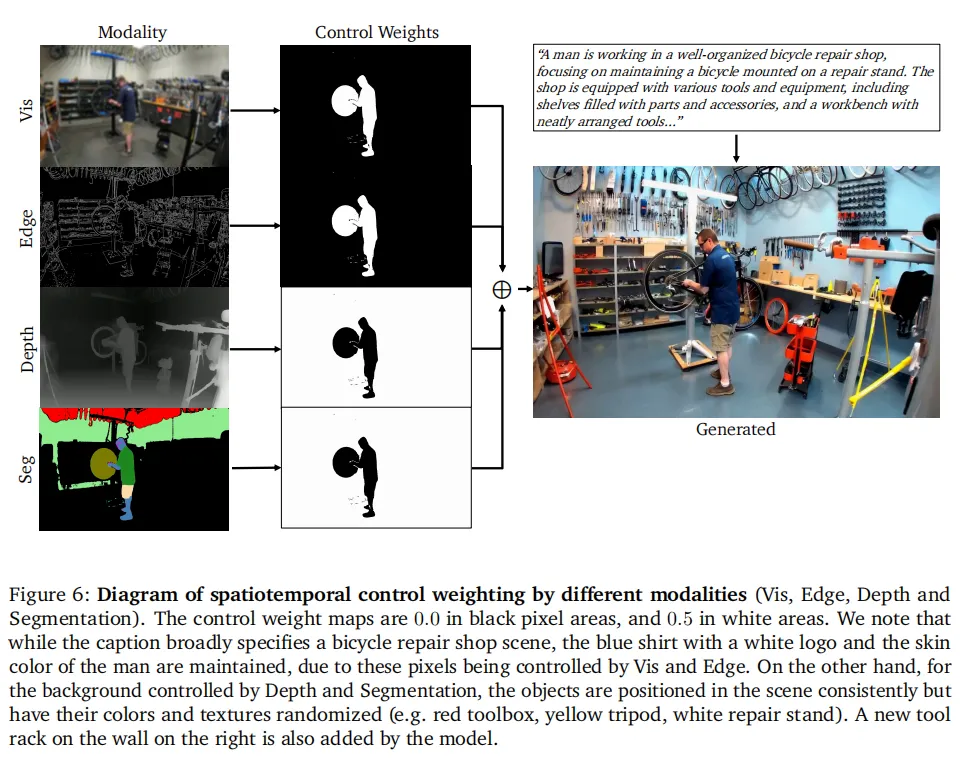
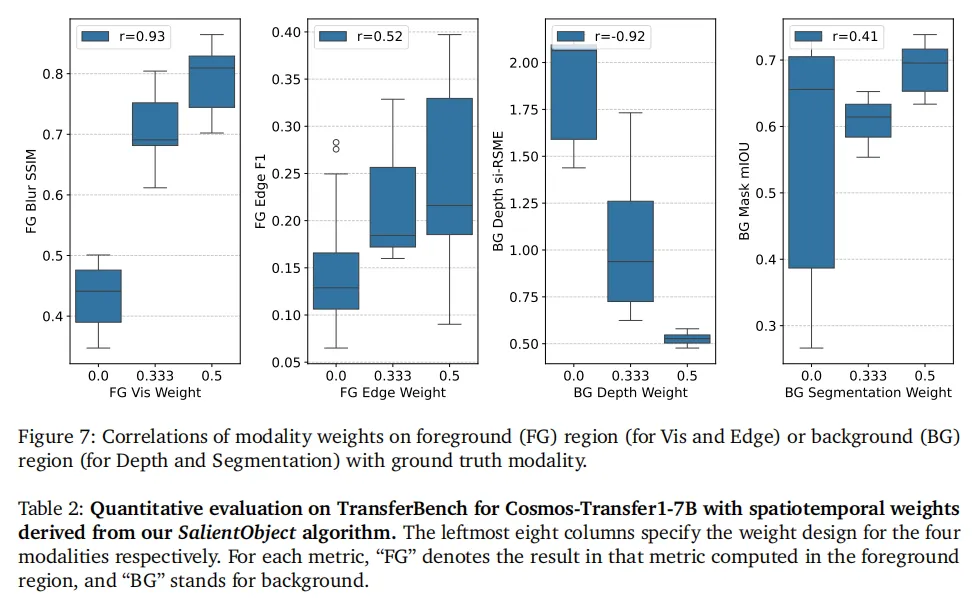
- 场景应用效果
机器人Sim2Real:保留机器人机械结构与动作,把仿真背景转为真实场景,缩小域间差距(对应图8)。

自动驾驶数据增强:融合HDMap与LiDAR模态,精准保留车道与3D物体,生成雾、雪、火灾等极端场景数据(对应图10、图11、表4)。


六、实时推理实现
模型在英伟达GB200 NVL72机架上实现实时生成,核心策略:
非注意力层用纯数据并行,注意力层用头并行。 把56K视频token序列分片到多个GPU,正负提示的降噪过程独立分配GPU组。 64块B200 GPU可在4.2秒内生成5秒720p视频,达到实时生成速度。
七、相关工作与总结
(一)相关工作
视觉域迁移:从分割、草图到图像/视频的生成,聚焦静态内容转换。 扩散模型空间控制:ControlNet系列方法,多为单一模态、无时空自适应设计。 仿真增强生成:GAN、扩散模型用于Sim2Real,未实现多模态自适应融合。
(二)论文总结
提出自适应多模态ControlNet,为世界生成提供空间-时间维度的精细化控制。 独立训练分支+推理融合,兼顾内存效率与模态灵活性。 适配机器人、自动驾驶等物理AI场景,有效缩小Sim2Real域差。 实现实时推理,代码与模型开源,推动物理AI研究落地。
Cosmos-Transfer2.5 整体定位
Cosmos-Transfer2.5 是基于 Cosmos-Predict2.5 主干的 ControlNet 风格条件世界生成框架,面向物理AI场景,用于完成仿真到真实(Sim2Real)、真实到真实(Real2Real)的世界翻译/转换任务。相比前代 Cosmos-Transfer1,它体积缩小 3.5 倍,同时保真度更高、长视频生成更稳定、支持闭环仿真,是物理AI世界可控生成的核心工具。
Cosmos-Transfer2.5 核心架构设计
1. 基础架构
以 Cosmos-Predict2.5-2B 作为基座模型 整体沿用 Cosmos-Transfer1 的控制型生成思路,但做关键结构改进 属于条件扩散式视频生成模型,接受边缘、模糊、分割、深度、世界场景地图等空间控制信号
2. 与 Transfer1 的架构差异(核心改进)
- Transfer1
:4 个控制模块全部集中插入在主干网络最前端 - Transfer2.5
:4 个控制模块均匀分散插入主干网络,每 7 个 DiT 块插入 1 个控制模块 作用:让控制条件(边缘/深度/分割等)逐层、渐进式融入生成过程,控制更精准,幻觉更少,长视频一致性更强

3. 支持的控制模态
支持 4 种空间控制信号,可单独或联合使用:
- 边缘图(Edge)
:突出物体边界,提升感知与轮廓一致性 - 模糊图(Blur)
:以低质模糊画面为条件,恢复清晰真实画面 - 深度图(Depth)
:提供三维几何结构,强化空间理解 - 语义分割图(Segmentation)
:提供物体/区域级语义线索,适合机器人、自动驾驶交互场景
Cosmos-Transfer2.5 训练方案
1. 训练数据构建
从 2 亿精选预训练视频中,抽取物理AI领域优先的视频(机器人、自动驾驶、智能空间、物理现象) 为不同控制模态构建专属数据集:
深度条件:1000 万视频(使用 Video Depth Anything 生成) 分割条件:300 万视频(使用 SAMv2 生成) 边缘+模糊条件:1400 万视频
所有数据均为真实物理世界视频,剔除动画、游戏、非物理合理内容
2. 训练方式
- 分模态独立训练
边缘、模糊、深度、分割四个控制分支分别独立训练 10 万次迭代,让模型先专精单种控制信号 - 有效 batch size = 64
其余超参完全与 Cosmos-Predict2.5-2B 保持一致,保证模型兼容性 最后融合为统一多模态控制模型(四种模态权重均等,各 0.25)
Cosmos-Transfer2.5 长视频生成能力(重点创新)
1. 长视频生成问题
DiT 类模型上下文长度有限,长视频必须自回归分块生成,会导致误差累积、画质衰减、幻觉增多。
2. 评估指标:RNDS(相对归一化 Dover 分数)
公式语言解释:
对每一段生成的视频块计算 DOVER 画质分 用每一块分数 ÷ 第一块分数,做归一化 曲线越平稳 = 误差累积越少、画质越稳定
3. 实验结论
在边缘、模糊、深度、分割四种控制条件下 Cosmos-Transfer2.5-2B 的 RNDS 曲线远更平稳 代表:长视频幻觉更少、误差累积更低、时序一致性更强
Cosmos-Transfer2.5 三大核心应用
应用 1:机器人策略学习的视觉增强(最核心落地)
目标:用 Transfer2.5 做语义级数据增强,提升机器人策略在未知视觉场景下的泛化能力。
方案:
机器人:双臂 Kinova Gen3,头部自感知相机 任务:双手抓取苹果放入碗中 原始数据:100 条真实演示视频 增强方式:
用 Transfer2.5 对每一条原视频生成 5 种语义变体 改变:物体颜色、桌面纹理、光照、背景、阴影 保留:机器人动作、任务流程不变
控制策略:
全局边缘控制 仅对机器人区域做模糊控制 用 Grounding DINO + SAMv2 分割机器人区域
结果
基础策略:0/30 成功 传统图像增强:5/30 成功 - Transfer2.5 增强策略:24/30 成功
能泛化到:山竹替换苹果、橙色碗、桌布、射灯、干扰物、黑色橱柜等九种未知场景
应用 2:自动驾驶多视角仿真生成
模型:Cosmos-Transfer2.5-2B/auto/multiview
功能:输入世界场景地图(World Scenario Map),输出 7 相机同步高清驾驶视频。世界场景地图包含:
高清地图元素:车道线、路沿、杆子、交通灯、道路结构 动态目标:3D 包围框(车辆、行人),带颜色分类、朝向阴影
架构实现:
把多视角画面沿时间维度拼接,把视角当帧处理 每个视角独立编码解码 加入视角嵌入(view embedding) 区分不同相机 使用 3D RoPE 位置编码,保证多视角时空一致性
性能:
FVD/FID 指标比 Transfer1 提升 最高 2.3 倍 3D 目标检测、车道线检测指标提升约 60% 几乎无幻觉车辆、方向错误、车道错乱等问题
应用 3:相机可控多视角生成(机器人 3 目同步)
模型:
Cosmos-Transfer2.5-2B/robot/multiview Cosmos-Transfer2.5-2B/robot/multiview-agibot
功能:输入单目视频 + 相机轨迹参数,输出多目同步视频。典型用途:
机器人头部视角 → 双手夹爪视角同步生成 补全遮挡区域,让机器人感知视线外物体
实现方式:
源视频与目标视频 token 在时间维度拼接 相机内参/外参每 4 帧采样一次,与 latent 对齐 目标相机表示为 Plücker raymap(6D 光线表示) 加入相机投影层,将相机信息融入 self-attention 训练时只更新self-attention + 相机投影层,主干冻结
评估结果:
相机旋转误差、平移误差与单视角模型持平 - 跨视角一致性(Sampson 误差)显著降低
:26.61 → 19.73 多视角画面同步更精准,无错位、跳变、物体不一致
六、Cosmos-Transfer2.5 实验结果(完整量化)
1. 控制生成指标(PAIBench-Transfer)
对比模型:Cosmos-Transfer1-7B vs Cosmos-Transfer2.5-2B
模糊对齐(SSIM):0.82 → 0.87 边缘对齐(F1):0.26 → 0.41 深度对齐(si-RMSE):0.70 → 0.67 分割对齐(mIoU):0.74 → 0.76 整体质量:9.24 → 9.31结论:2B 小模型全面超越 7B 前代模型
2. 人类主观评估
指令遵循更准确 控制条件 adherence 更高 幻觉明显减少 长视频稳定性大幅提升
七、Cosmos-Transfer2.5 模型规格(开源清单)
模型名称 | 能力 | 输入条件 |
Cosmos-Transfer2.5-2B/general | 通用控制生成 | 边缘、模糊、分割、深度 |
Cosmos-Transfer2.5-2B/auto/multiview | 自动驾驶多视角 | 世界场景地图 |
Cosmos-Transfer2.5-2B/robot/multiview | 机器人多视角 | 文本 + 第三人称视频 |
Cosmos-Transfer2.5-2B/robot/multiview-agibot | 机器人三目同步 | 文本 + 头部视角视频 |
八、Cosmos-Transfer2.5 核心优势总结
- 更小更强
:2B 参数 > 前代 7B,体积缩小 3.5 倍 - 控制更精准
:分散式控制模块插入,条件遵循度更高 - 长视频更稳
:误差累积少,RNDS 曲线更平稳 - 物理AI适配
:专为机器人、自动驾驶、工业空间训练 - 多视角同步
:支持 3/7 相机一致生成 - 语义级增强
:可直接用于机器人策略泛化提升
