 夜雨聆风
夜雨聆风
上一篇讲了怎么上手 Claude Code、怎么安装配置。
这篇是系列第 5 篇,Paul 进了一步,把话题转向了更难的问题:怎么用 AI 辅助写作和思考,但不把思考本身交出去。
他分享了几个他自己在用的方法——构建个人写作风格模版、用 DAG 技能把审稿意见整理成有序修改方案、让 AI 做注释编辑而不是代写。这些流程,对做研究的人来说比“怎么装软件”更值得反复琢磨。
关于 Paul Goldsmith-Pinkham
Paul 是耶鲁大学管理学院金融学副教授、NBER 研究员,在 AER 等顶级期刊发表论文,研究方向涵盖消费金融与应用计量经济学。他是经济学界推广 AI 编程工具的标杆人物,Substack 专栏“A Causal Affair”拥有超过 3000 名订阅者。
以下为 Paul 最新 Claude Code 教程的中文翻译
用 LLM 写作是个有争议、也挺复杂的话题。我打算从研究者的角度来谈——包括怎么产出研究想法、怎么表达研究成果,以及怎么把分析转化成文字。写作用途很广,讲具体操作之前,我想先说两个前提。
写作本身就是思考
写作往往就是我们思考和消化想法的过程。 对于写作者来说,把文字落在纸上,本身就是理清思路的方式。有人担心:用 LLM 辅助写作时,很容易陷入所谓的认知卸载——把思考这件事本身也外包出去。你有几个模糊想法,扔给 LLM,让它替你动脑。这个担忧是有道理的。
从这个认识往回推,逻辑就清楚了。我们得把想法想透,因为迟早会有人追问,我们得能答得上来。那怎么尽量避免——无论有意还是无意——把这部分动脑工作甩给 AI?我没有完美的答案,但后面会提几个具体的策略。
文风的同质化
在体育界,LLM 会被称作“下限提升者”(floor raiser)——它能显著改善比较糟糕的写作。 但与此同时,确实存在一种合理的担忧:LLM 会产生一种同质化的默认腔调,读起来无聊,甚至让人尴尬。
有一种观点认为,这种同质化会拉低整体写作质量。这关乎社会层面——我们真的需要更多力量推动写作趋同吗——但更关乎个人层面,有自己的文风很重要。不,这是学者自我认同的一部分! 你作为学者,要有意识地认识自己的文风,并努力保留它。
在 AI 的语境下,我们会讲到写作风格指南,但说实话,要通过这些工具完美保留自己的写作文风,挑战相当大,达不到原来的效果。某些方面可能接近,但我们都是人,每天状态都不一样,输出不会稳定反映你今天想怎么写这件事。我们用来训练和校准这些工具的语料,质量取决于我们喂给它的信息,而我们一直在变。今天我们想要的写作风格,可能和过去想要的完全不同。
枯燥但必要的写作
写作是思考的重要载体,但在工作中,我们也有大量纯粹枯燥、让人痛苦的写作。想想那些套话连篇的邮件、备忘摘要、常规文档,甚至回归系数的初稿。有些需要仔细处理,但第一遍草稿可以做得很快,帮你快速起步。
我的判断是,LLM 在这类工作上相当好用,省下来的时间非常有价值。真正的关键是划清枯燥写作和重要写作之间的界限。你能卸载的枯燥工作越多,留给重要内容的思考时间就越多。 但如果把太多重要的部分也卸载出去,就会出问题。
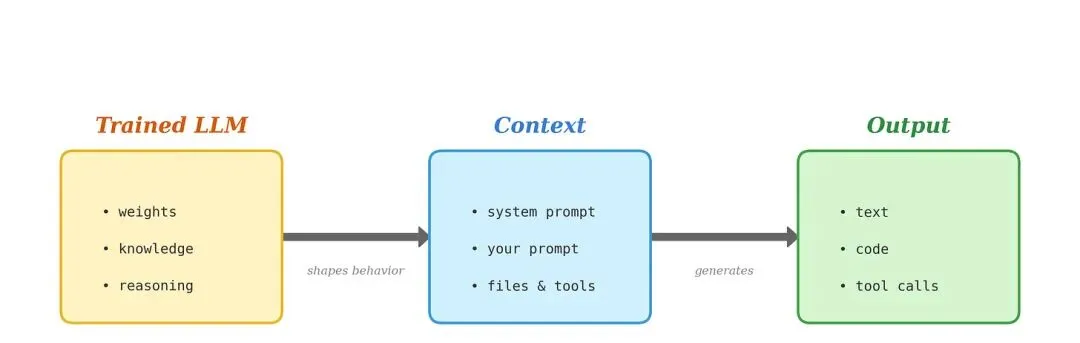
输进 LLM 的是什么
第一篇文章里讲过,LLM 从根本上是一台文本机器。它读取并预测序列化文本,在上下文窗口里运作。

这对写作意味着什么?输给 LLM 的是文本。LLM 是一台在极高维空间里运转的强大文本预测机器,我们通过调整上下文窗口在其中移动。改变提示词会稍微调整模型的关注点,让它以某种特定方式进行推理——也许更接近你处理问题的方式。但这不等于它一定能抓住正确的东西。
理解了 LLM 的工作原理,我们来看看如何让它更好地服务于我们的写作风格。
构建写作风格指南
这个练习相当直接。我们要做的是:基于自己的写作,构建一个风格指南——本质上就是一个 Skill。它会生成一份规则清单,告诉 LLM 该如何调整输出。它不一定能完美捕捉你的文风。打个比方:把一个复杂多面的人投影到墙上,只能捕捉到某些侧面,但问题是捕捉的对不对。
具体怎么做:
1. 收集你满意的写作样本。 论文、备忘录、邮件——凡是你觉得“对,这就是我的风格”的东西。不需要完全有代表性——我用的是自己的论文,虽然都是合著的——但样本多点总没坏处。 2. 让 LLM 分析模式。 把写作样本喂给它,让它找规律:句子长度、语气、用词选择、结构,你一贯会做的事,你从不做的事。 3. 把输出整理成 writing_style.md。 LLM 的分析是起点,不是成品。你需要编辑它——删掉说错的,加上遗漏的,把规则说得更精准。4. 在提示词里引用它。 当你想让 Claude 按你的风格写作或编辑时,指向这份风格指南。
另外,Claude 其实相当了解自己的能力。如果你想搞定某类重复任务,可以直接问 Claude 怎么做——比如“我想能够反复做 X、Y 或 Z”——它大概知道该怎么设置。甚至不用真的动手,问一下它就会告诉你要做什么。
实际演示是什么样的
在视频里,我用 Claude Cowork 做了现场演示。如果你记得第一篇视频,Claude 应用里有三个不同的东西:Chat、Cowork 和 Code。Cowork 是命令行版 Claude Code 的应用版本——对于写作任务,我觉得它作为第一遍处理很好用。我不想让大家觉得一定要在命令行里操作才能用上这些工具。
我把 Cowork 指向了我的个人网站仓库——里面有我的学术论文和博客文章——然后给了一个刻意写得不太精确的提示词:
我希望你读取 papers 文件夹里的论文,以及我博客上的博文,为 Claude 创建一个写作风格指南 Skill,让我能在想要的时候让 Claude 按我的风格写作。
正如我跟 Markus 说的,这提示词烂透了——根本说不清我想要什么。Opus 启动了一个子代理来读博文和论文(只读了几篇,部分原因是不想把上下文窗口撑爆),然后在 .claude/skills/paul-voice/skill.md 创建了一个 Skill 文件。
这个风格指南没什么神奇的。——说实话,这东西其实挺简单粗暴、甚至有点傻的?它就是个 Markdown 文件——带标题和列表的文本文件。当你使用这个 Skill 时,这些文本就被直接塞进上下文里。本质上就是让人来总结你的写作方式。

它产出了什么
这份指南对我的写作风格给出了相当正面的评价——我都不好意思说,甚至有点溜须拍马的味道。哪怕是世界上最烂的研究者,也会得到一个相对正面的评价。就像人们说给下属的反馈得是“汉堡包”式——好话、批评、好话——这里连中间的批评都没有。你得使劲逼,Claude 才肯说点不好听的。
但逼着让它说负面反馈,值得吗?这取决于情况。如果你有写作上的习惯性表达,而且觉得那正是你风格的体现,那就值得保留。Nabokov 给《纽约客》编辑写信时有句话说得很好:
你可以认为那是糟糕的写作风格,但那反映了他对自己写作的期望。
写作上的某些癖好,正是我们文风的一部分。
Markus 还问我:这能用在英语之外的语言吗——德语、法语?当然可以。Claude 的多语言能力相当强。我经常用法语写作,输出质量很好。不是每种语言都一样,但在很多语言里会表现得相当不错。
有无风格指南的输出对比
为了展示差别,我让 Claude 向博士生听众解释双重差分法(difference-in-differences,简称 DID)两次——一次不带风格指南,一次带上我的写作 Skill。
不带风格指南的版本已经很不错了——Opus 写这类东西的能力真的令人惊叹。带风格指南的版本不一样:它从实际问题切入,先搭一个 2×2 的示例,再进入回归分析。这确实更像我的处理方式。不过坦白说,感觉有点像对我写作风格的 caricature——我觉得很多人用这类工具都有这种感受。做出来的 Skill 有你的影子,能认出来,但有点夸张。
这里要强调一点:当人们谈论 Skill 和风格指南时,得清楚它就是一份规则清单。仅此而已——就是塞进上下文窗口的文本。

Markus 随后建议我们试试让 Claude 用陀思妥耶夫斯基的风格解释双重差分法。

简直夸张到家了,完全是讽刺画级别的模仿。但这正好说明了同样的事情——只是更明显而已。
更完善的风格指南长什么样
演示版只用了几篇论文来构建。我日常在用的风格指南要详细得多——因为我让 Claude Code 迭代了更多论文,做了更多工作。它有更具体的写作模式:用从句、爱用破折号、把系数换算成美元数值来讨论经济意义。还有政策意义和经济意义的分解——这是一份比演示版大得多的规则清单。
我会把我完整的风格指南链接出来,供大家参考一个更成熟的版本。里面还有我各类段落开头的写法例子。思路和演示版一样——只是更详细。不一定完美,但对我有用。
从实践中学到的几点:
• 它更像是“规则清单”,而不是“文风捕捉”。 把风格指南理解为一组约束,把 LLM 的输出往更好的方向推,而不是完美复现你的文风。带风格指南比不带好,但不会听起来完全像你。 • 要不断迭代。 第一版风格指南会有很多遗漏。用着用着发现问题,就回去补规则。它是一份活文档。 • 可能需要多份指南。 我有一份写论文用的,一份写社交媒体和博客用的,对应我不同的表达风格。社交媒体那份,回头读起来说实话有点肉麻。
审稿意见与战略性修订 Skill
这部分涉及两件相关的事:让 Claude 写审稿意见(针对你自己的论文,用于自我评估),以及用一个 Skill 来处理你收到的审稿意见,规划修订方案。
写审稿意见
我不是建议你让 Claude 帮你写期刊审稿报告。我用这个 Skill 是为了评估自己的论文,或者在不是正式审稿人的情况下,想快速给朋友的论文一些反馈。在那些本来根本不会反馈的情况下,我能更快聚焦到我通常会关注的问题上。让 Claude 先总结和评估论文,作为第一步是有帮助的。
构建审稿报告 Skill,我把 Claude 指向了我自己过去写的审稿报告文件夹:
请读取这个文件夹里所有我写的审稿报告。我想让你构建一个 Skill,能生成看起来像这些报告的反馈——重点放在我通常关注的问题类型上。
这和风格指南是同一个套路:喂给它你满意的输出样本,让它提取规律,把结果保存为可复用的 Skill。
Markus 问我,这跟 Ben Golub 做的 Refine.ink 比起来怎么样。区别挺有用的:Refine.ink 做的是确保内部一致性——论文的论断是否与结果一致、结果是否可信。它不太涉及对论文应该长什么样的品味偏好。而审稿意见则是识别真实问题和品味偏好的混合体。

战略性修订 Skill
Aalto 大学的 Jukka Sihvonen 搞了一个叫 strategic revision(战略性修订) 的 Skill,我非常喜欢。它的作用是:你投了一篇论文,收到了一组审稿意见和编辑信。基于这些,如何制定修订方案?
我喜欢它的原因在于它能做到:
• 根据审稿意见生成一组待办任务 • 识别这些任务的顺序、冲突和优先级
这很有帮助,因为即使你读了审稿意见,也常常一头雾水——特别是有四份报告要应对的时候,到底该做什么。它把所有东西整理成一份总文档。
具体而言,这个 Skill 的描述是:“用 NetworkX 做计算 DAG 验证,从同行评审报告里创建带严格任务依赖关系图的修订总计划。”翻译成人话就是:
1. 把每条审稿意见解析成一个独立任务。 每个具体的点都被提取出来并编号。 2. 对每个任务分类。 有些是论证性的——就是要写文字。有些是实证稳健性检验。还有澄清说明和编辑决策。 3. 构建任务依赖关系图。 用 DAG(有向无环图) 来理清任务间的依赖关系。DAG 表达的是 X 影响 Y、Y 依赖 X。因为是有向图,可以用网络理论检查是否存在环——有环就意味着依赖结构搞错了。它实际上需要用 Python 跑一个验证器,如果 Skill 的依赖包不可用,Claude 会自己写一个验证器。 4. 把任务组织成执行批次。 A 批和 B 批可以并行,但 C 批需要等前两批都完成。会输出这些批次的可视化图示。 5. 识别审稿人之间的冲突。 如果有多位审稿人——Markus,我估计你也碰到过这种情况——他们对该怎么改会有分歧。这个 Skill 会找出这些冲突并标记:如果你做了 X,审稿人 Y 可能会不高兴。 6. 识别附带风险。 什么依赖什么,每个改动的连锁影响是什么。
为了演示,我拿了一篇已经发表的论文(这样不用担心泄露),让 Claude 先写一份审稿意见,然后把论文和生成的审稿意见一起喂给战略性修订 Skill。
输出是一个 26 个任务的修订方案,分成五个执行批次。它识别出了关键路径、核心瓶颈,以及哪些任务可以并行。甚至提出了合著者如何分工。展示任务依赖关系按批次组织的可视化图示,是我觉得最有用的部分。你基本上可以把这些任务拷贝出来,说“好,现在我们需要完成这些任务”,然后把它们组织成具体的问题来处理。
有一点要说清楚:在如何使用这些东西上,你仍然需要大量自己的判断。记得我们说过,对 LLM 来说,具体和明确非常重要。有一组明确的任务——就像和 RA 合作一样——之后在各个步骤上与 LLM 合作就容易得多了。
Markus 问这对理论论文的效果和实证论文一样好吗?我两种都用过,觉得都不错。某种程度上理论论文反而更好——你知道哪个证明依赖哪个,依赖结构更清晰。实证论文涉及太多品味判断,需要更多来回权衡。
显然这不是终极解决方案。这个 Skill 还有很多可以改进的地方——我到现在只用在两篇论文上。但我最喜欢它的一点是:它努力把任务变得可操作,对任务分类,并且搞清楚依赖关系。
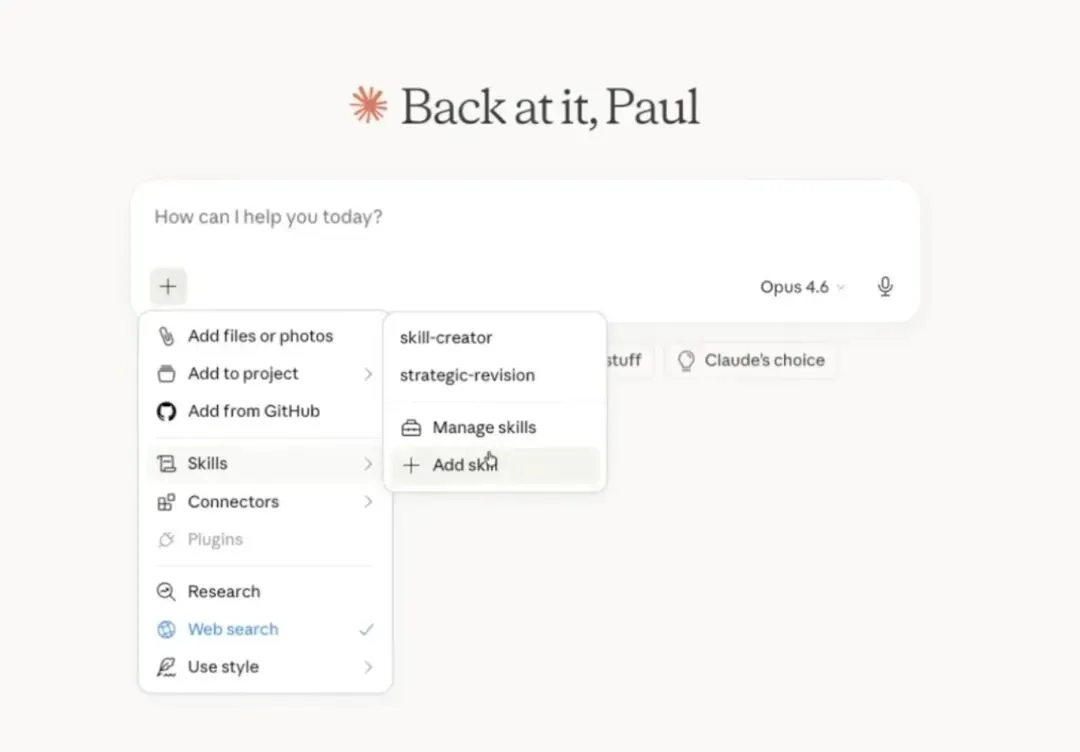
你可以在 Claude 应用里安装这个 Skill:进入管理 Skills,添加 Skill,上传 Markdown 文件。安装之后,在 Chat 和 Cowork 里都可以用。
让 LLM 做编辑,而不是代写
AI 写作可能有些奇怪的表达习惯,但它是一个不错的编辑。它不需要重写你的文字,但 LLM 能解释它为什么认为某处推理或表达有问题。这样既能防止认知卸载,又能用上 LLM 强大的推理能力。
举个例子。我拿了我的一篇博文——用博文是因为它更短、更简单,换成研究论文道理是一样的——给它这样的提示词:
请看这篇博文。我想得到《纽约时报》编辑风格的建议,针对写作和表达清晰度。但不要直接修改我的文字。请在我论证薄弱或表达不清晰、需要改进的地方,以内嵌注释的形式添加批注。
它产出的是原始文字保持完全不变,但在特定位置插入了 Markdown HTML 注释。渲染出来看不到——它没有改任何东西。但你会得到标注,就像编辑做的那样。
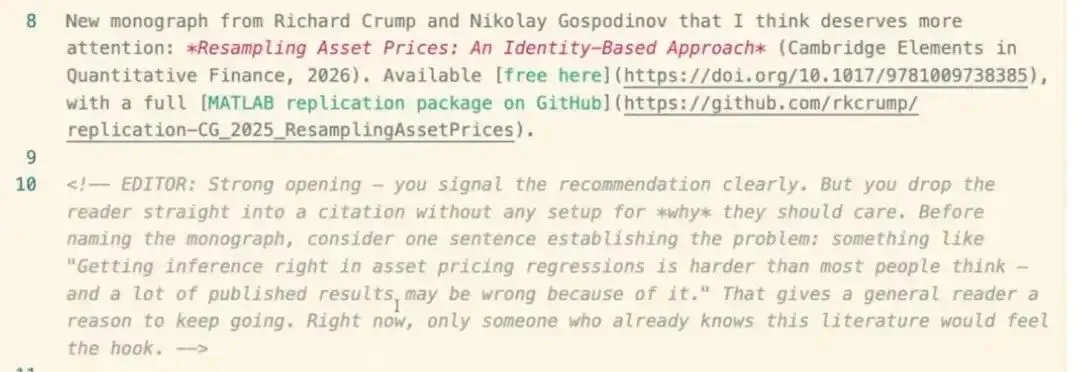
我觉得这很有用,因为想保留自己语气的话,这正是你想要的编辑风格。如果有人直接告诉你怎么改——如果你是研究生,有时会很乐意接受——但就更难保住自己的语气了。只有注释,你就被迫主动参与到反馈里。 你读每条注释,自己决定该怎么做——重写这句话、删掉它,还是不同意就不改。 [1]
Markus 建议说,也可以让它在注释旁边附上改法。这也行——有时它会主动这样做。但危险在于你很容易就直接接受了改写版本。有时我会把那段文字拷出来问“我该怎么处理这里?”我们不总是有无穷的精力思考写作,所以有选项是好事。但只有注释的方式,能让你保持更高的参与度。
一个实际注意事项:这个操作需要在 Cowork 或 Claude Code 里做,不能在 Chat 里做,因为它需要读取和编辑你电脑上的文件。你可以把文档上传到 Chat 让它做同样的事,但在 Cowork 里效果更好,因为它用的是你的本地文件系统,还能用你已经安装的所有 Skill。Chat 是在云端创建一个计算环境来完成同样的任务,文件和 LLM 之间的距离越远,问题就越多。
用 LLM 推进想法
有几个模糊的想法,很容易就扔给 LLM,让模型替你动脑。我想推荐的方式,跟第一篇文章里讲上下文窗口时类似:要有意识地做压缩和笔记,来迭代想法。
• 先自己迭代想法,再去找 LLM 谈。 在跟 LLM 交流之前,尽量把想法自己想透,因为具体很重要。如果我说“嘿,我想想一个关于储蓄的生命周期模型”——你不会得到什么突破性的想法。越具体,越好。 • 加载更多上下文。 用 Claude Code 或 Cowork 而不是普通聊天窗口的一个重要原因,是你可以往 LLM 里加入更多文件和上下文。你可以说:“看,我在这个文件夹里。这是一堆和我感兴趣的话题相关的论文。这是一些笔记。这是一些幻灯片。这是和这个政策相关的一些网站。这是我们在想的东西。从这里开始。”你能给的信息越多越好。 • 也可以用“页边注”的方式。 不要问“我该写什么?”而是让 LLM 对你已经写的东西发表评论。
这又回到了开头说的“写作即思考”。目标不是避免用 LLM 做智识工作——而是在用它的同时保持自己在智识工作中的参与。 永远记住这张图,1977 年 IBM 培训手册里那张著名的图:


核心要点
1. 写作就是思考。 要有意识地区分什么可以外包,什么要自己来。检验标准是:不靠 LLM,你能深入讨论这些想法吗? 2. 风格指南有用,但不会完美。 要不断打磨、持续迭代——但永远不会完美。说到底,Skill 是对你的某种总结,在某些方面像 caricature 一样夸张,但确实有用。它就像一面能回应你的回音壁——说白了,就像个提线木偶,用你的声音替你开口。 [2] 3. 枯燥写作是最容易的突破口。 套话邮件、第一遍草稿、常规文档——这类帮助对个人来说真的很大。最大的价值不是让 AI 替你做,而是给你一个非常好的初稿。 4. 战略性修订 Skill 相当好用。 把一堆审稿报告变成一份带结构、带依赖关系、带优先批次的修订方案——还有很多其他值得探索的 Skill,但这个能把审稿意见变得可操作,而不只是令人不知所措。 5. 要注释,不要代写。 这是我找到的一种防止自己写出太多 LLM 腔的方式——在我真的想保留自己语气的场合。这是一种让你保持参与感的编辑方式。 6. 先想清楚,再让 AI 写。 在跟 LLM 交流之前,尽量把想法自己想透。具体很重要。加载尽可能多的上下文。
下一步
这是个很有争议的话题,但我确实认为这里有很多价值,特别是在你想推动事情进展、快速起步的时候。下一篇,我们会做更多定制化的内容——聊 Skill、容器,以及怎么在所谓的 YOLO 模式下操作,也就是让 Claude 在不需要我们确认的情况下自主运行。
原文信息
• 原文标题:Writing & Thinking with AI Assistance • 作者:Paul Goldsmith-Pinkham • 发布日期:2026 年 4 月 12 日 • 原文链接:https://paulgp.substack.com/p/writing-and-thinking-with-ai-assistance • 配套视频:Markus Academy 系列视频第 5 集(链接待补充) • 版权声明:原文版权归 Paul Goldsmith-Pinkham 所有,本译文仅供学习交流,如需转载请联系原作者获取授权。
1.这个方法很有用。这种“注释而不代写”的思路,是让 AI 辅助不侵蚀自己语气的关键——你会马上获得过去只有离稿搁置几天才能得到的那种视角。(Markus 评论) ↩︎2.用 LLM 做编辑而不是代写,是本文最核心的洞见。 ↩︎
往期精彩内容:
