 夜雨聆风
夜雨聆风今天练习的是阿里AI研发岗最新机考笔试题3题。
各大厂真题都整理了近两年的机考题,题库里面有详细思路和答案~
肥猫学长也提供机考辅导助攻和面试辅导欢迎咨询。
微信号:jackwwang8
目前已经整理的题库有如下:如果有需要可以加我微信获取哦

阿里AI研发岗实习春招题目4.11
阿里机考题目一:模乘循环数
题目描述
初始时 a = 1。给定两个整数 k, m,系统会不断重复执行如下更新:将 a 更新为 (a * k) % m。
由于取模运算,a 的取值最终会进入循环。
请你计算在无限次执行更新的过程中,a 一共可能取到多少个不同的值。
测试用例
样例1 输入
2 7样例1 输出
3样例2 输入
2 8样例2 输出
4样例3 输入
0 5样例3 输出
2解题思路
初始时 a=1,每次按 a = (a * k) % m 规则更新。要求在无限次执行更新的过程中,a 一共会取到多少个不同的值。
由于每次更新后,a 的取值一定在区间 [0, m-1] 内,因此总状态数最多只有 m 个。最坏情况下走 m 步就一定会出现某个值重复。
一旦某个值重复,之后的变化过程也会完全重复,因此后面不会再产生新的状态。我们可以用一个布尔数组记录某个值是否出现过。
只要当前 a 没出现过,我们就标记它已出现,答案加一,接着按规则更新。
当发现 a 已经出现过时,说明进入了循环,结束过程即可。时间复杂度和空间复杂度均为 O(m)。
# 第一题:模乘循环数
def calculate_distinct_states(multiplier, modulo_val):
# 使用布尔数组记录出现过的状态
state_visited = [False] * modulo_val
# 初始状态
current_val = 1
distinct_count = 0
# 只要当前状态没有出现过,就继续迭代计算
while not state_visited[current_val]:
# 标记当前状态已经出现
state_visited[current_val] = True
# 不同的状态数增加
distinct_count += 1
# 按照题目规则更新状态
current_val = (current_val * multiplier) % modulo_val
return distinct_count
def main_process():
# 读取输入的两个参数
multiplier, modulo_val = map(int, input().split())
# 输出不同状态的个数
print(calculate_distinct_states(multiplier, modulo_val))
if __name__ == "__main__":
main_process()
阿里机考题目二:逆向序列构造
题目描述
对于一个正整数序列 A,根据带阈值 d 的保留规则,从左到右生成序列 B。
规则如下:先保留 A 中的第一个元素。当处理到 A 里的某个元素时,将其与序列 B 中刚刚保留的前一个元素 x 进行比较。
若 x + d <= 当前处理元素 条件成立,则将其保留下来接入序列 B;否则直接跳过该元素。
现给出阈值 d 与最终得到的序列 B,你的任务是构造任意一个原序列 A,满足上述规则生成的序列正好是 B。
并且要求:原序列 A 长度要尽可能短,在满足最短长度的基础上字典序尽可能小。题目保证一定存在符合要求的序列。
测试用例
样例1 输入
23 23 5 64 02 1 1 3样例1 输出
43 5 1 652 1 1 3解题思路
观察相邻两个保留元素 b1 和 b2 之间的构造过程。要让 b2 被保留,它前面的那个数必须满足:被保留的数 + d <= b2。
如果它不想被保留,它和前一个保留元素的关系必须是:前一个保留元素 + d > 刚插入用于阻断的数。
所以我们分两种情况讨论。情况一,满足前一个数 + d <= 当前数,此时顺着往后接当前数即可,无需额外插入数字进行干扰。
情况二,如果直接拼在后面当前数会被跳过。此时我们必须在它们中间至少插入一个数字进行阻断,从而改变比较状态。
为了让长度最短,只插入一个数字。为了让字典序最小,这唯一插入的数字直接取最小正整数 1 即可。由于系统保证有解,所以插入 1 一定能阻断,并且能顺接给下一个数字创造条件。
只需要线性遍历一次,按情况判断是否要插入 1 即可,时间复杂度属于线性级别。
# 第二题:逆向序列构造
import sys
def reconstruct_original_sequence(seq_len, threshold, target_b):
# 初始化构造结果,先把第一个保留元素放入
result_seq = [target_b[0]]
# 依次处理目标序列的剩余元素
for i in range(1, seq_len):
# 检查是否直接满足保留条件
if target_b[i - 1] + threshold <= target_b[i]:
result_seq.append(target_b[i])
else:
# 不满足条件时,需要插入元素来进行阻断
# 追求最短长度所以只插入一个,追求最小字典序所以插入 1
result_seq.append(1)
result_seq.append(target_b[i])
return result_seq
def main_process():
# 批量读取所有输入数据
raw_data = list(map(int, sys.stdin.buffer.read().split()))
if not raw_data:
return
test_cases = raw_data[0]
data_idx = 1
output_res = []
# 循环处理每一组测试数据
for _ in range(test_cases):
seq_len = raw_data[data_idx]
threshold = raw_data[data_idx + 1]
data_idx += 2
target_b = raw_data[data_idx : data_idx + seq_len]
data_idx += seq_len
# 构建原始序列
reconstructed = reconstruct_original_sequence(seq_len, threshold, target_b)
output_res.append(str(len(reconstructed)))
output_res.append(" ".join(map(str, reconstructed)))
sys.stdout.write("\n".join(output_res) + "\n")
if __name__ == "__main__":
main_process()
阿里机考题目三:果酱平衡计算
题目描述
有一个大小为 n乘m 的储物柜,格子里放着蓝莓酱(记作 B)和草莓酱(记作 S)。我们希望储物柜中这两种果酱的数量最终能够一样相等。
对于储物柜每一行,你可以独立地选择移除其最左侧连续的若干瓶果酱,比如移除 k 瓶。
请计算出,最少需要总共拿走多少瓶果酱,才能使剩下柜子中两种果酱总数恰巧相等。
测试用例
样例1 输入
31 5BSSSB2 4BSSBSBBB2 3BBBSSS样例1 输出
340解题思路
题意是给定一个只包含 B 和 S 的字符矩阵。每一行可以删除一个前缀区域,求出在剩下 B 和 S 数量相等的条件下最小的删除次数。
我们首先可以算出初始整个矩阵中 B 和 S 的数量绝对差,即系统初始的总差值。
最后要让两者相同,说明所有拿走的这些被切除前缀区域里面,包含的 B 和 S 的数量差,必须恰好等于初始的总差值,能起到完全双向抵消的效果。
因此转化为每一行独立选取不同长度的前缀删掉,会对应一种差值贡献。题目成了从每一行挑选一种前缀删除方案,让方案合计提供特定差值且使得删除项数也就是代价最小。
可以运用分组背包思想进行动态规划去打表。由于每一行的删除都有很多结果可能,我们提炼每行里对于某个确定差值下达成目标用代价最小的那个保留下来存入映射图表里。
全局设置一个一维的状态空间表示各项累积差量下的最小削去数量,一行一行的往前迭代更新。最终直接输出能恰好平衡初始差量对应的解答即为答案。
# 第三题:果酱平衡计算
import sys
def calculate_min_removal(rows, cols, grid_data):
# 计算整个网格初始的差异总量,B用1表示,S用-1表示
overall_diff = 0
for row_str in grid_data:
for char in row_str:
if char == 'B':
overall_diff += 1
else:
overall_diff -= 1
# 差值的绝对值极限不会超过字符总数
max_possible_diff = rows * cols
diff_offset = max_possible_diff
inf_val = 10**18
# 记录目前状态下,达到各个差值的最小移除字数
dp_states = [inf_val] * (2 * max_possible_diff + 1)
dp_states[diff_offset] = 0
# 针对每一行作为分组进行背包DP转移
for row_str in grid_data:
# 该行在各个差值下花费的最小删除长度
row_min_cost = {}
current_diff = 0
row_min_cost[0] = 0
# 遍历前缀的保留情况
for idx, char in enumerate(row_str):
if char == 'B':
current_diff += 1
else:
current_diff -= 1
prefix_len = idx + 1
# 若同一个差值下有更短的删除长度,覆盖保留
if current_diff not in row_min_cost or prefix_len < row_min_cost[current_diff]:
row_min_cost[current_diff] = prefix_len
# 初始化下一阶状态
next_dp_states = [inf_val] * (2 * max_possible_diff + 1)
# 将上一行状态向后递推
for old_idx in range(2 * max_possible_diff + 1):
if dp_states[old_idx] == inf_val:
continue
# 使用本行可选方案进行组合
for delta, cost in row_min_cost.items():
new_idx = old_idx + delta
if 0 <= new_idx <= 2 * max_possible_diff:
next_dp_states[new_idx] = min(next_dp_states[new_idx], dp_states[old_idx] + cost)
dp_states = next_dp_states
return dp_states[diff_offset + overall_diff]
def main_process():
# 数据批取读取优化
input_func = sys.stdin.readline
test_case_count_str = input_func().strip()
if not test_case_count_str:
return
test_cases = int(test_case_count_str)
result_output = []
for _ in range(test_cases):
rows, cols = map(int, input_func().split())
grid_data = [input_func().strip() for _ in range(rows)]
# 将本组测试数据的计算结果暂存起
result_output.append(str(calculate_min_removal(rows, cols, grid_data)))
print('\n'.join(result_output))
if __name__ == "__main__":
main_process()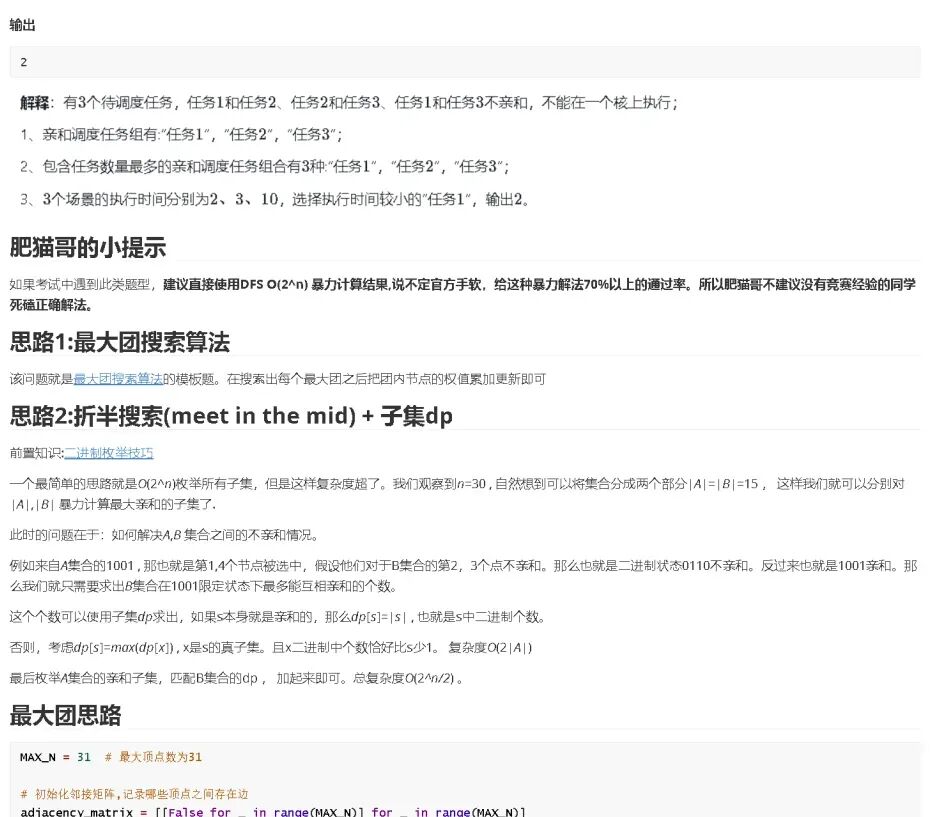


扫描它,然后带走我:

微信号| jackwwang8
bilibili| 养只猫一米哒
小红书| 2878931801
