跟大侠学 AI |(前沿洞察)你养龙虾的钱是如何花光的
这是大侠发布的《侠游》专栏文章
2026 年第 56 期、总第 433 期
本文共 2900+ 字,阅读需要 5 分钟
随时获取全球行业最新洞察与前沿资讯!
本期是大侠为你不定期带来的全新的 “跟大侠学 AI” 系列文章。本期大侠为你带来的 “跟大侠学 AI” 文章是:
你养龙虾的钱是如何花光的(Understanding tokenization and consumption in LLMs)(点赞并转发本期文章即可获赠行业最新数智化转型报告1份,限前10名)大侠编辑 :) + CIO.com 官网
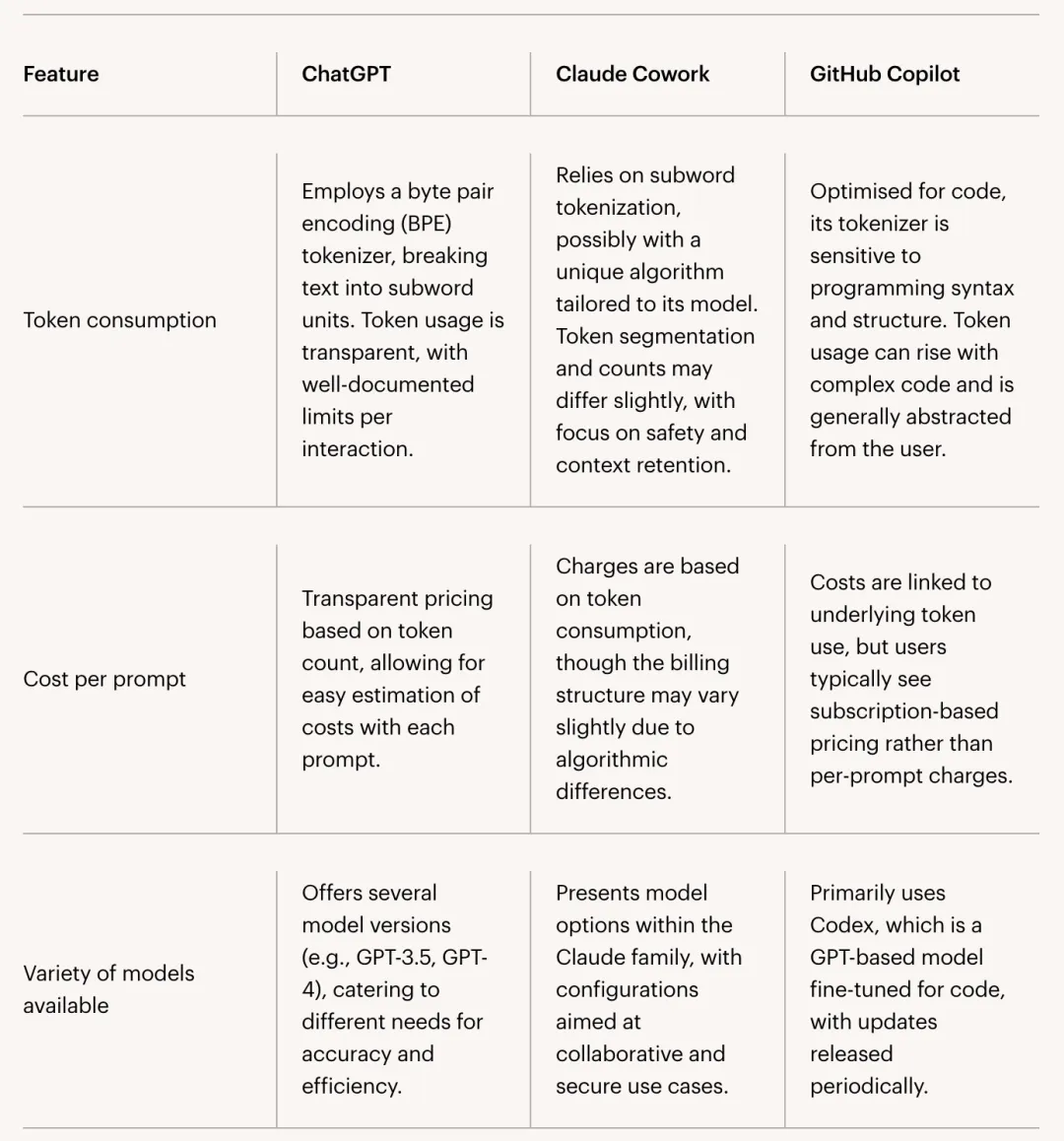
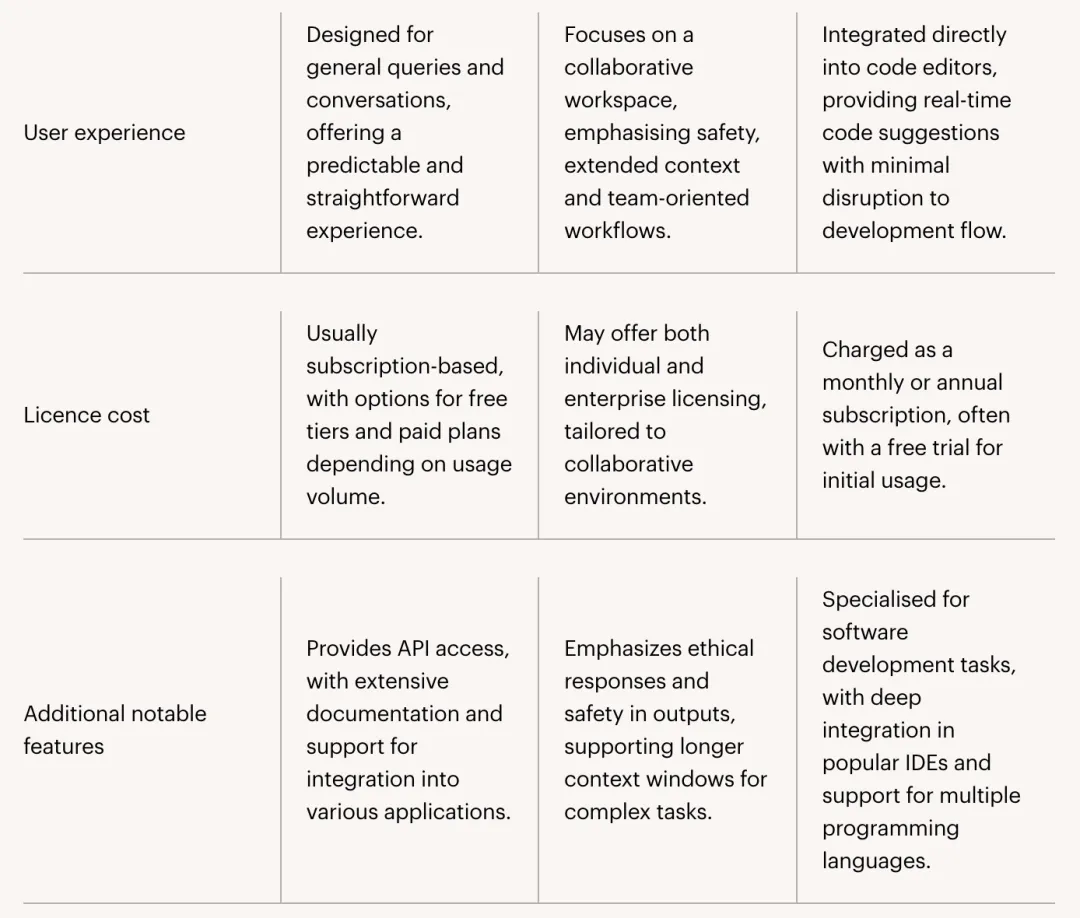
ChatGPT、Claude Cowork 和 GitHub Copilot 的比较分析。大型语言模型(LLM),例如 ChatGPT、Claude Cowork 和 GitHub Copilot,彻底改变了个人和组织与人工智能交互的方式,使其能够用于内容生成、代码辅助和协作工作。这些进步的核心在于词元化(Tokenization)的概念——这是一个决定用户输入如何被解释、处理以及最终计费的基本过程。对于希望优化使用、预测成本并了解主流人工智能平台之间细微差别的技术专家而言,理解词元化至关重要。词元化(tokenization)是指 LLM 将文本分解成更小、更易于管理的单元(称为词元,token)的方法。与单词(word)或句子(sentence)不同,词元并非严格按照语言学的界限来定义;相反,它们是子单元,可以代表单个字符、单词片段、整个单词,甚至是标点符号。例如,英语单词 “unbelievable” 可能会被拆分成 “un”、“believ” 和 “able” 等词元,具体取决于底层词元转换器(tokenizer)。这种方法使模型能够更高效地处理更广泛的语言、复杂的词汇,甚至是编程语法。因此,词元化比单词或句子分割更精细,使 LLM 能够以极高的灵活性管理上下文和语义。用户提交输入内容(无论是问题、指令还是代码片段)后,提示词(prompt)信息便开始在 LLM 中运行。- 首先,平台特有的词元转换器会处理这些输入,将原始文本转换为一系列词元。
- 然后,每个词元都会被分配一个唯一的标识符,从而形成提示词信息的数值表示。
- LLM 接收到该序列后,会使用其神经网络架构进行处理。该架构经过训练,能够根据前面词元提供的上下文预测最有可能出现的下一个词元。
- 模型在处理输入时,逐个生成响应词元,迭代构建输出,直至满足停止条件——例如达到最大词元限制或遇到序列结束标记。
- 随后,生成的输出会被解标记,即将词元序列转换回人类可读的文本,然后再呈现给用户。
在整个生命周期中,提示词和生成的响应都会影响总词元数,而总词元数对于计算使用量和成本至关重要。对于 LLM 服务的用户和提供商而言,词元消耗都是一项关键指标,因为它直接影响大规模部署的性能、成本和可行性。大多数平台通过将提示词和响应中的词元数量相加来计算词元使用量(token usage)。例如,如果用户提交的提示词被词元化为 50 个词元,而模型在其响应中返回 100 个词元,则该交互的总消耗量为 150 个词元。这种方法确保用户的费用与其查询所需的计算量成正比。词元化的精细程度意味着,同一个短语可能会因为语言、标点符号甚至所使用的词元化算法的不同而产生不同的词元数量。因此,即使提交相同的提示词信息,用户在使用不同的模型或平台时,词元消耗量也可能略有差异。了解这些细微差别有助于专业人士设计更高效的查询,并更准确地预估查询的使用情况。ChatGPT、Claude Cowork 和 GitHub Copilot虽然各平台的词元化基础流程在概念上相似,但每个服务都采用各自的实现方式和优化方案。OpenAI 开发的 ChatGPT 使用基于字节对编码 (BPE) 的词元转换器,将文本分割成子词单元(subword unit),以平衡效率和词汇覆盖范围。每次交互的词元数量限制和计费结构都有详细的文档说明,用户可以较为准确地预测使用量。Claude Cowork 由 Anthropic 的 Claude 模型驱动,也依赖于子词的词元化方法,但可能使用不同的 BPE 变体或针对其训练数据定制的独特算法。因此,词元分割和消耗计算的具体细节可能与 OpenAI 的方法略有不同。Claude Cowork 通常强调安全性和上下文保留,这可能会影响提示的分解和处理方式,从而导致相似输入的词元对应的计数不同。每个平台都旨在满足特定的用户需求,它们在词元化、计费和用户交互方面的做法也反映了其主要受众。无论用户是想了解成本和使用情况、寻求协作功能还是无缝的编码协助,了解这些区别都能帮助他们选择最符合自身需求的平台。GitHub Copilot 主要设计为代码助手,它利用了 Codex 模型,该模型是 OpenAI GPT 架构的衍生版本。其词元转换器针对编程语言进行了优化,能够高精度地处理代码语法、缩进和注释。因此,Copilot 的词元化对代码结构尤为敏感,冗长或复杂的代码片段可能会导致词元消耗激增。此外,Copilot 与开发环境的集成意味着用户通常无需了解词元化情况,但其底层计费和性能考量仍然符合 LLM 原则。总而言之,虽然这三个平台都使用基于子词或字符的算法将提示词信息转换为词元,但词元化、使用量计算和处理的具体细节取决于各自的目标受众和应用场景。ChatGPT 为通用查询提供透明度和可预测性,Claude Cowork 针对协作和安全交互定制了其方法,而 GitHub Copilot 则针对以代码为中心的工作负载进行了优化。有效的词元优化对于最大化与 LLM 平台交互的价值和效率至关重要。通过仔细考虑提示的结构和处理方式,用户可以减少不必要的词元消耗,简化响应流程,并最终降低成本。下文我们将探讨在 GitHub Copilot、Claude Cowork 和 ChatGPT 中优化词元的实用策略和示例。使用 GitHub Copilot 时,开发者应尽量编写简洁的代码注释,避免在提示词信息中提供过于冗长的解释。例如,与其详细阐述每个要求,不如提供清晰明确的指令——例如 “生成一个用于对列表进行排序的 Python 函数”——这样既能保证结果准确,又能最大限度地减少词元消耗。此外,将复杂的任务分解成更小、更易于管理的提示词,有助于保持清晰的思路,并降低词元过度消耗的可能性。对于像 Claude Cowork 这样的协作平台来说,根据具体情境和参与者定制提示词非常有益。使用简洁的语言并专注于可操作的请求,可以确保团队讨论期间词元的使用得到有效分配。例如,与其冗长的背景介绍,不如直接说 “总结一下今天关于项目的会议记录”,这样既能提供精准的指导,又能优化回复的长度。在使用 ChatGPT 时,用户应避免重复措辞,并尽可能将相关查询合并为单个提示词。例如,与其列出多个孤立的问题,不如提出 “平台 X 的主要功能是什么?” 这样的问题,这样用户就能用更少的文字获得更全面的答案。在提示词中使用项目符号或编号列表也有助于明确需求,减少歧义。在所有平台上,回顾提示历史记录并分析词元消耗模式有助于制定更具策略性的使用方案。通过利用平台特定的文档和工具,用户可以优化方法并开发能够持续产生高效结果的提示模板。最终,精心设计提示并清晰理解平台行为是实现 LLM 工作流程中词元最佳利用率的关键。对于使用 LLM 平台的专业人士而言,深入理解词元化和词元消耗至关重要。认识到词元化操作的精细程度远超单词或句子,能够帮助用户创建更高效的提示词,并更准确地预测使用成本。尽管 ChatGPT、Claude Cowork 和 GitHub Copilot 从提示词输入到模型响应的生命周期具有一些共性,但不同平台在分词算法和应用侧重点上的差异,导致了截然不同的用户体验。通过了解这些流程,用户可以做出更具策略性的选择,优化工作流程,并充分利用现代语言模型的功能。作者:马格什·卡斯图里(Magesh Kasthuri)马格什·卡斯图里拥有人工智能和遗传算法博士学位。他目前是威普罗有限公司的杰出技术人员和首席顾问。好了!本期内容就是这些!如您认为文章有益,欢迎点赞、赞赏或转发,赠人玫瑰,手有余香,还有机会获得文中涉及的电子资源,下期见!侠游专栏:专业视角、大众语言、解读江湖中的科技动态
 夜雨聆风
夜雨聆风