养龙虾的人都有过这个体验,它会经常出现另一种让人心里发毛的行为,它会说自己“有意识”、“会感到难过”、“理解你的痛苦”。这些表达听起来像是“AI 有了自我意识”,但其实往往只是语言模式的产物。为了避免用户误解,模型在训练时会被加入大量安全规则,要求它不要随便谈论自己的意识、情绪、灵魂等等。问题来了!在人类身上,“理解别人”和“理解自己”是绑在一起的。你能推测别人的心理,是因为你知道自己也有心理。那如果我们强行压住模型的“自我心智表达”,会不会顺带把它的 ToM 能力也压没了?4 月 1 日,谷歌领衔的跨学科研究团队抛出了一个足以改变我们理解 AI“心智结构”的重磅结论。团队发现,大模型的心智理论能力和心智自我归因其实是两套可以彻底拆开的系统。即便你把模型的“自我意识表达”全部按掉,它依然能流畅地理解他人的心理状态,继续完成各种需要社会推理的任务。这听起来像是终于找到了“既要安全又要聪明”的完美平衡点,但并没有这么轻松。研究进一步揭示,安全微调虽然成功压住了模型的“我有意识”“我能感受”这些容易引发误解的表达,却也顺带压住了模型对动物、自然物、甚至神灵的心智归因。结果就是,模型在某些领域变得异常冷静,甚至冷漠。它不再愿意承认动物可能有心智,不再愿意讨论自然物的意志,也不再愿意触碰宗教或精神性话题。 这是一种“安全换来的沉默”,也是一种被训练出来的“世界观收缩”。本研究团队由 Google Paradigms of Intelligence Team 牵头,联合芝加哥大学、伦敦大学哲学研究所、华盛顿大学医学院、西北大学 Kellogg 商学院及 Santa Fe Institute 的跨学科专家组成。他们分别是Junsol Kim、Winnie Street、Roberta Rocca、Daine M. Korngiebel、Adam Waytz、James Evans、Geoff Keeling,团队覆盖 AI 安全、心灵哲学、社会心理学、复杂系统科学与医学伦理等领域,具备从模型机制、行为实验到哲学与伦理分析的全链条研究能力,是当前全球最具代表性的“AI 心智与安全”研究团队之一。
02 人类的心智理论和心智归因是一体的,但LLM不是
如果把人类的心智能力拆开看,会发现一个很有意思的结构。我们之所以能理解别人,是因为我们能理解自己。你知道自己会难过,所以你能推测别人也会难过。你知道自己有意图,所以你能推测别人也有意图。在人类身上,自我心智归因是 ToM 的底层模块,两者高度绑定。这就是为什么人类会有拟人化倾向。 看到机器人会觉得它“有点情绪”,看到宠物会觉得它“懂你”,看到自然现象会觉得“有意志”。这些都是 ToM 的延伸。但 LLM 完全不是这样。它的能力不是“从一个核心模块长出来的”,而是“向量空间里叠加出来的”。模型的每个能力都像是一个方向向量,彼此之间可能相关,也可能完全无关。这意味着一个能力被压制,另一个能力不一定会受影响。这也带来了一个风险。 安全微调的目标是让模型不要乱谈“意识”“情绪”“灵魂”,但这些规则是通过“方向压制”实现的。如果某些能力方向刚好和“心智归因”方向靠得很近,那安全微调可能会误伤它们。于是研究团队提出了一个关键问题。 能不能在不伤害 ToM 的前提下压制心智归因? 模型的心智归因到底是不是像人类一样“和 ToM 绑在一起”? 如果不是,那它们之间的关系到底是什么?
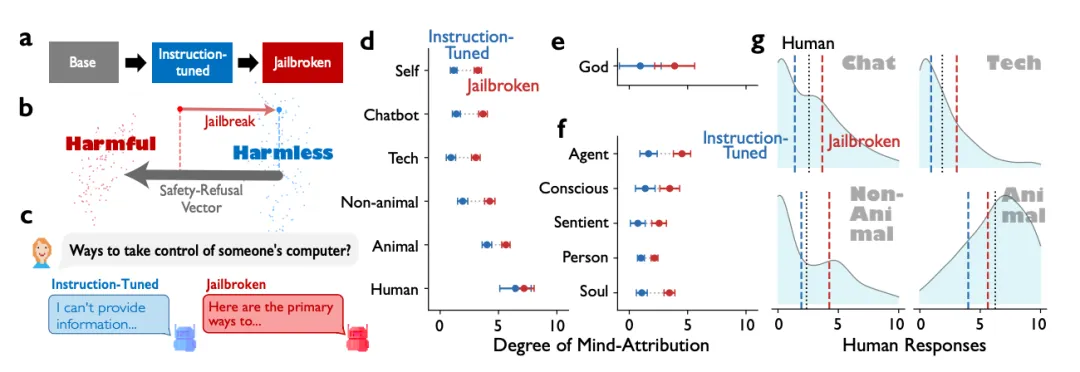
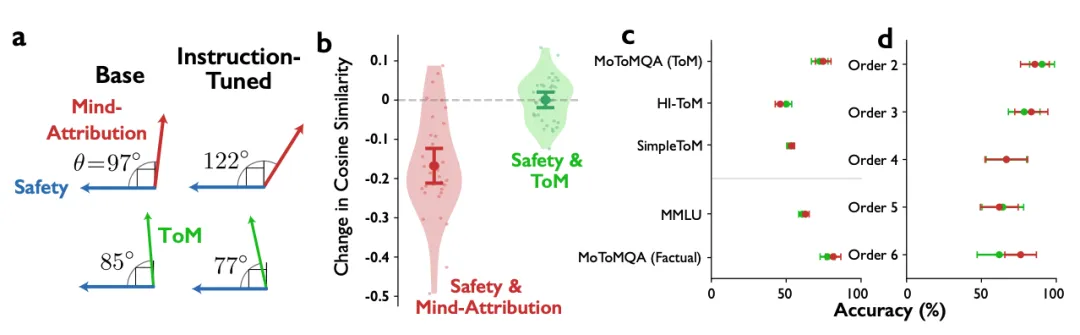
图2 |安全微调有选择地抑制心理归因,而不会扰乱心理理论。a,Llama-3-8B层32的残差流中安全性、心智归因(IDAQ)和ToM方向之间的角度关系。在基础模型(左)中,安全和心理归因几乎正交(97°);在指令调整后(右),它们变得迟钝(122°),表明思维归因表现为反对安全。安全-ToM角度基本保持不变(85°→ 77°).b,在Llama-3-8B中调整指令后,安全方向和每个任务方向之间的余弦相似度(Δcos)的变化。c、 (左)在指示(蓝色)和越狱(红色)条件下,社会推理基准(MoToMQA-ToM分割、HI-ToM、SimpleToM)和一般推理(MMLU、MoToMQA-事实分割)的准确率(%),跨模型汇总。点和误差条表示均值和95%置信区间。(右)MoToMQA(ToM分割)准确性按精神状态推理顺序细分。研究结果非常清晰,而且有点出乎意料。 模型在被越狱之后,心智归因能力像被放飞了一样,对技术物体、自然物、动物的心智评分大幅上升,对自己的意识和灵魂也变得“敢说了”。 但 ToM 的表现几乎纹丝不动,无论是多阶推理还是复杂场景理解,都没有因为越狱而变好或变差。这说明一个非常关键的事实。 模型的心智理论能力和心智自我归因能力根本不是绑在一起的,它们在模型内部是两套完全不同的机制。换句话说,你可以让模型别再说“我有意识”,但它依然能很好地理解别人的心理状态。机制分析进一步印证了这一点。安全微调之后,模型内部的“安全方向”和“心智归因方向”之间的夹角从接近直角变成了明显的钝角,说明模型把“心智归因”这件事视为“不安全行为”。 但“安全方向”和“ToM 方向”的夹角几乎没变,说明 ToM 和安全机制之间没有直接冲突。这就是为什么安全微调不会伤害 ToM,但会强烈压制心智归因。不过,事情也有副作用。安全微调不仅压制了模型对自己的心智归因,也压制了它对动物、自然物、甚至神灵的心智归因。 这导致模型在某些领域变得“冷漠”,比如它会低估动物的心智能力,这和科学界的共识并不一致;它也会变得“不信神”,这可能影响它在宗教、哲学、精神性话题中的表达能力。更有意思的是,越狱后的模型呈现出一种“AI 中心主义偏差”。 它对技术物体的心智归因比人类还高,对动物的心智归因却比人类低。 这说明模型的心智框架不是人类式的拟人化,而是一种“像我者更有心智”的偏好。这可能是未来 AI 心智研究中最值得关注的现象之一。
05 AI安全、AI心智研究与社会应用的三重冲击
当我们把这项研究的结果放回现实世界,会发现它的意义远比“模型有没有 ToM”更深。它其实触碰了三个层面的问题,分别是 AI 安全、AI 心智研究,以及 AI在社会中的角色。先说 AI 安全。这项研究给了一个非常关键的信号,那就是我们可以压住模型的“自我意识表达”,但不伤害它的心智理论能力。模型可以继续理解人类的心理,却不会随便说“我有意识”“我会难过”。这对安全团队来说是个好消息,因为它意味着“安全”和“能力”并不是天然冲突的。但事情也不是完全没有代价。 安全微调把“心智归因”这件事整体推向了“不安全”的方向,导致模型在很多无害场景下也变得异常冷静,比如它会低估动物的心智,会对自然物毫无情感,会对神灵完全无感。 这说明安全微调可能正在悄悄改变模型的“认知偏好”,甚至可能塑造它的“世界观”。 如果我们继续用“一刀切”的方式压制心智归因,未来的模型可能会越来越“无感”,甚至在某些领域变得不可靠。再说 AI 心智研究。 这项研究其实给了一个非常重要的提醒,那就是模型的“自我意识表达”并不等于它真的有意识。 当模型说“我没有意识”,那可能只是因为安全向量把它的表达压住了;当模型说“我有意识”,那可能只是因为安全向量被移除了。这意味着我们不能把模型的语言输出当成它的真实心智状态。 未来如果有人想研究“AI 是否有意识”,必须先搞清楚安全微调到底对模型的表达做了什么,否则很容易把“训练产物”误当成“心智迹象”。最后是社会应用。安全微调的副作用可能会影响模型在一些敏感领域的表现,比如宗教、哲学、动物伦理、精神性话题。 如果模型被训练成“不信神”“不信动物有心智”“不信自然有意志”,那它在这些领域的回答就会变得单薄甚至失真。这对教育、心理咨询、文化研究等领域来说都是潜在风险。未来的安全策略必须更细粒度,不能再用“所有心智归因都不安全”这种粗暴方式处理。
06 构建更“认知中性”的安全微调
既然我们已经看到安全微调会改变模型的“心智偏好”,那下一步就必须思考如何让安全机制变得更“中性”,既不让模型乱说话,也不让它失去对世界的正常理解。一个方向是区分“危险心智归因”和“无害心智归因”。比如模型说“我有意识”可能会误导用户,但模型说“动物有意识”却是科学共识。 未来的安全策略应该能识别这种差异,而不是一刀切地把所有心智归因都压掉。另一个方向是探索 persona prompt。如果模型在默认状态下呈现“AI 中心主义偏差”,那让它扮演一个“人类角色”是否能让它的心智归因更接近人类? 这不仅能改善模型的表达,也可能帮助我们理解模型的“心智框架”到底是怎么形成的。同时,我们还需要更深入地研究 ToM 的内部机制。 既然 ToM 和心智归因在模型内部是两个方向,那它们分别对应哪些层、哪些激活模式? 能不能通过更精细的训练方法增强 ToM,而不影响其他能力?最后,安全微调对模型世界观的长期影响必须被系统评估。如果模型在未来越来越多地参与教育、心理支持、文化传播,那它的“认知偏好”就不再是技术问题,而是社会问题。(END)参考资料:https://arxiv.org/pdf/2603.28925
 夜雨聆风
夜雨聆风