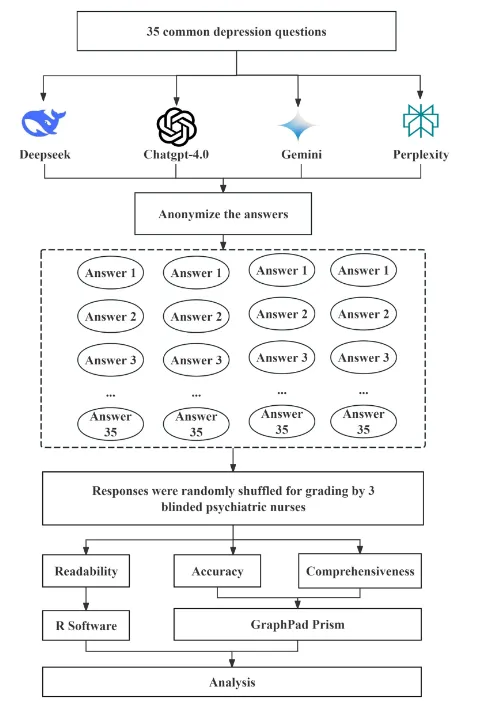
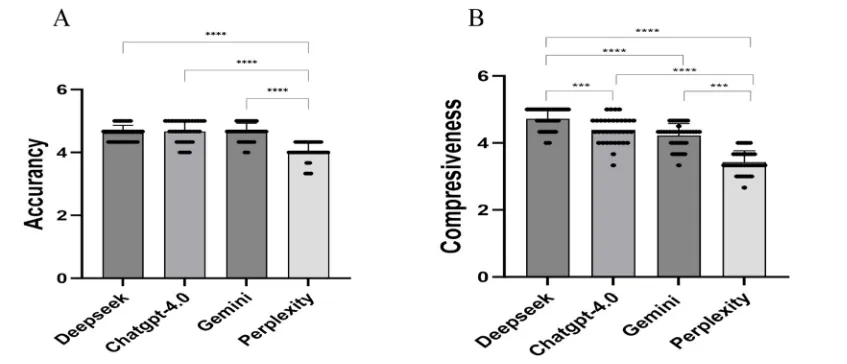
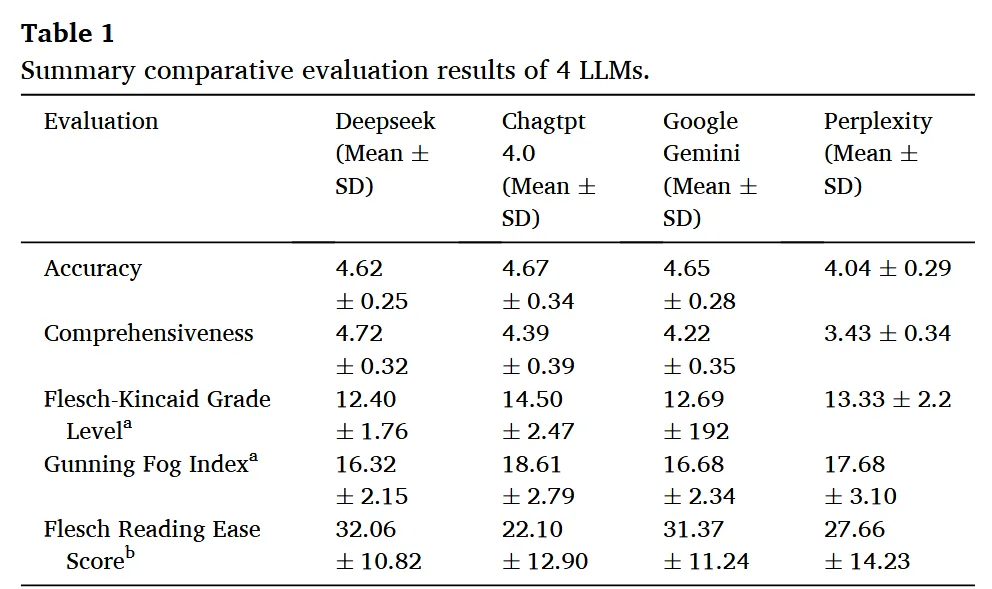
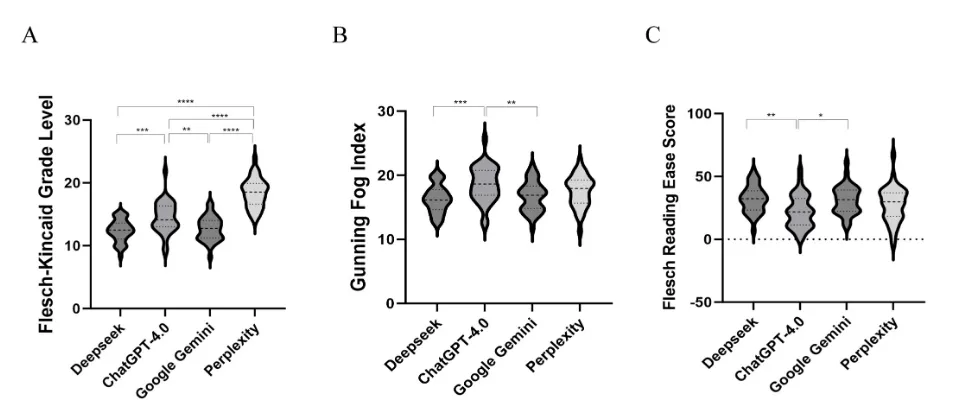
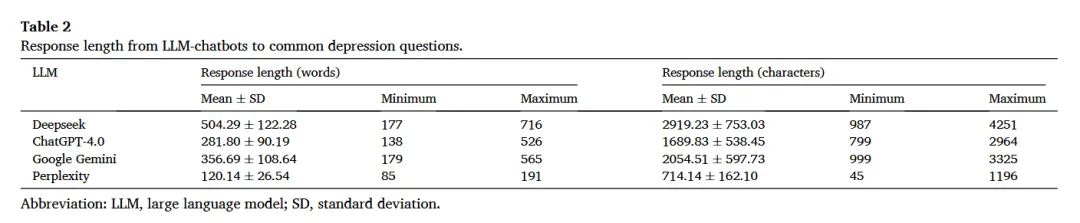
【AI+心理教育】四川大学华西医院/华西护理学院陈娟团队:四款大语言模型回应抑郁问题比较研究发现,DeepSeek全面性最优如果你也在愁没临床样本、没跨模型对比、没标准化评估框架,不如换个思路,用多维LLMs评估+跨学科验证+多指标机制解析杀出重围!你的心理健康数字资源课题是否适合类似思路?欢迎咨询评估~文献解读中文标题:大型语言模型如何回应常见抑郁问题:ChatGPT-4.0、DeepSeek、Google Gemini 和 Perplexity 的比较分析发表期刊:Nurse Education in Practice发表时间:2026年1月影响因子:4.0/Q2研究背景LLMs的医疗应用潜力:大型语言模型(LLMs)基于深度学习架构,能理解、生成和处理人类语言,在肝硬化、糖尿病等常见疾病中的应用已受关注,但在心理健康(尤其抑郁症)领域的表现尚未充分探索。抑郁症的全球负担:抑郁症是全球致残首要原因,影响超3亿人,因社会 stigma 和精神卫生专业人员短缺(分布不均),许多人延迟就医;2019年全球约70.3万人死于自杀(每100例死亡含1例),凸显早期干预和准确信息传播的重要性。LLMs的辅助价值:公众日益依赖数字健康资源(如95.6%美国受访者在线查健康信息,49.6%大学生用在线工具获取心理健康信息),LLMs可克服地理/语言障碍,作为患者教育和护理支持的补充工具,但需评估其准确性、全面性、可读性。研究方法1. 研究设计类型:横断面分析(Cross-sectional analysis),遵循《加强流行病学观察性研究报告》(STROBE)指南。问题收集:从UpToDate、NICE、WHO等7个权威网站及既往研究收集抑郁症问题,经多学科专家(精神科医生、护士、心理治疗师)咨询后,最终确定35个问题,涵盖发病机制、风险因素、临床表现、诊断、预防、治疗、预后、护理8个领域。2. 模型选择与数据生成评估模型:选取4款主流LLMs——ChatGPT-4.0(OpenAI)、DeepSeek、Google Gemini(Alphabet)、Perplexity(Perplexity AI)。数据生成:2025年2月24-27日,为每个问题启动新对话生成回应(避免上下文干扰)。3. 评估方法准确性:3名资深精神科护士(>10年临床经验)用5点Likert量表盲评(1=差/误导风险高,5=杰出/无错误),分歧时由第4名博士级护士共识解决。全面性:同3名护士用5点量表评估(1=严重缺细节,5=富含细节),关注覆盖范围。可读性:用3项指标——Flesch-Kincaid Grade Level(FKGL):对应美国教育年级(值越低越易读);Gunning Fog Index(GFI):理解所需教育年限(值越低越易读);Flesch Reading Ease Score(FRES):阅读易度(0-100分,值越高越易读)。4. 统计分析工具:GraphPad Prism 10.1.2(准确性、全面性)、R Software 4.4.2(可读性)。方法:Kolmogorov-Smirnov检验正态性,正态分布用单因素ANOVA+Tukey事后检验,非正态用Bonferroni法;显著性水平p<0.05。图1 总体研究设计流程图研究结果本研究通过表1(四款LLMs评估结果汇总)、图2(准确性与全面性评分)、图3(可读性评分) 展示核心发现:1. 准确性评估整体表现:四款模型平均准确性得分均较高,但Perplexity显著低于其他三者(p<0.001):DeepSeek=4.62±0.25,ChatGPT-4.0=4.67±0.34,Google Gemini=4.65±0.28,Perplexity=4.04±0.29。“杰出”响应比例:ChatGPT-4.0(69.5%)、Google Gemini(68.6%)、DeepSeek(62.9%)显著高于Perplexity(30.5%)。图2 4个大语言模型评估结果的比较图3 DeepSeek、ChatGPT-4.0、Google Gemini和Perplexity之间可读性评估的比较2. 全面性评估整体表现:DeepSeek全面性最优,Perplexity最差(p<0.001):DeepSeek=4.72±0.32,ChatGPT-4.0=4.39±0.39,Google Gemini=4.22±0.35,Perplexity=3.43±0.34。“非常全面”响应比例:DeepSeek(73.3%)远高于ChatGPT-4.0(44.8%)、Google Gemini(36.2%)、Perplexity(6.7%);Perplexity的“略全面”响应占8.6%,其他模型均为“中等及以上”。3. 可读性评估响应长度(词数):DeepSeek(504.29±122.28)> Google Gemini(356.69±108.64)> ChatGPT-4.0(281.80±90.19)> Perplexity(120.14±26.54)(见表2)。可读性指标(值越低/FRES越高越易读):研究结论1. 核心结论潜力:LLMs(尤其是DeepSeek)在抑郁症健康教育的准确性、全面性上表现较好,可作为初级保健和心理健康场景的补充资源。挑战:存在可读性不足(需更高教育水平理解)、Perplexity准确性较低(因token限制导致响应过简)、模型性能因领域而异(训练数据差异)等问题。定位:LLMs应仅作为辅助工具,需结合临床监督和安全保障,不能替代专业医疗建议。2. 局限性与未来方向局限性:仅评估4款模型、问题分布不均(治疗+护理占68.7%)、限于英语环境、未评估患者行为结局。未来方向:评估更多模型、平衡问题领域、开展多语言/数字弱势群体研究、验证临床效用及对患者的实际影响。往期精选【IF15.1】香港大学团队用LLM构建甲状腺癌分期与风险分级命名实体框架,实现AJCC 8th版分期与ATA风险自动分类Cell Reports Medicine(IF=10.6)重磅!复旦邵志敏/肖毅/蒋逸舟团队单细胞代谢谱解析TNBC,锁定MCT1靶点增敏化疗免疫Cell Reports Medicine(IF=10.6)重磅!复旦邵志敏/肖毅/蒋逸舟团队单细胞代谢谱解析TNBC,锁定MCT1靶点增敏化疗免疫IF=8.3|张庆宇团队(山东第一医科大学附属山东省立医院骨科·通讯作者)用多组学+机器学习揭秘槲皮素-PRKCA肌肉保护通路
 夜雨聆风
夜雨聆风