 夜雨聆风
夜雨聆风⚡ AI Infra 消息速报
2026-04-16 · 每日一报,聚焦前沿
[1] PyTorch 2.11 推出 XPU Graph,Intel GPU 推理效率大幅提升 #框架
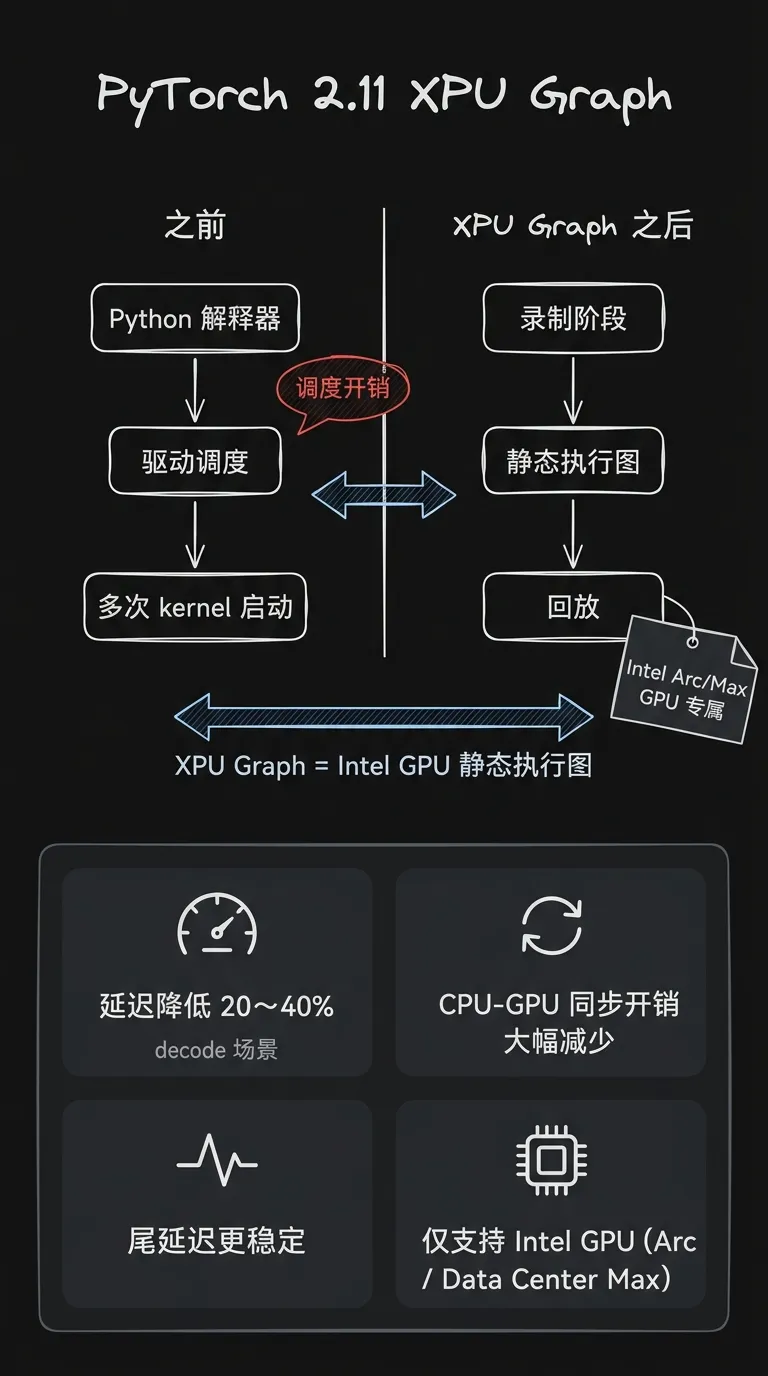
架构变化:PyTorch 2.11 新增 XPU Graph 支持,将 CUDA Graph 的静态执行图机制引入 Intel GPU(Arc 系列及 Data Center GPU Max 系列)。XPU Graph 可将一段推理计算的所有 kernel 调度、内存分配提前录制为静态执行图,后续每次运行直接回放——跳过 Python 解释器开销与驱动层调度延迟。
需要注意:XPU 是 Intel GPU 的 PyTorch 后端标识,与昇腾、国产加速器无关,不能直接迁移到国产芯片。
效果收益:小批量高频推理场景(如 token by token decode)延迟可降低 20%~40%;CPU 与 GPU 之间的同步等待开销显著减少;long-running 推理服务的尾延迟更稳定。
Infra 应对:已在 Intel GPU 基础设施上部署 PyTorch 的团队可直接接入,调用方式与 CUDA Graph API 基本对齐(`torch.xpu.graph`);不使用 Intel GPU 的团队暂不涉及。
🔗 https://pytorch.org/blog/pytorch-2-11/
[2] MLPerf Inference v6.0 发布:推理基准全面覆盖新型工作负载 #硬件
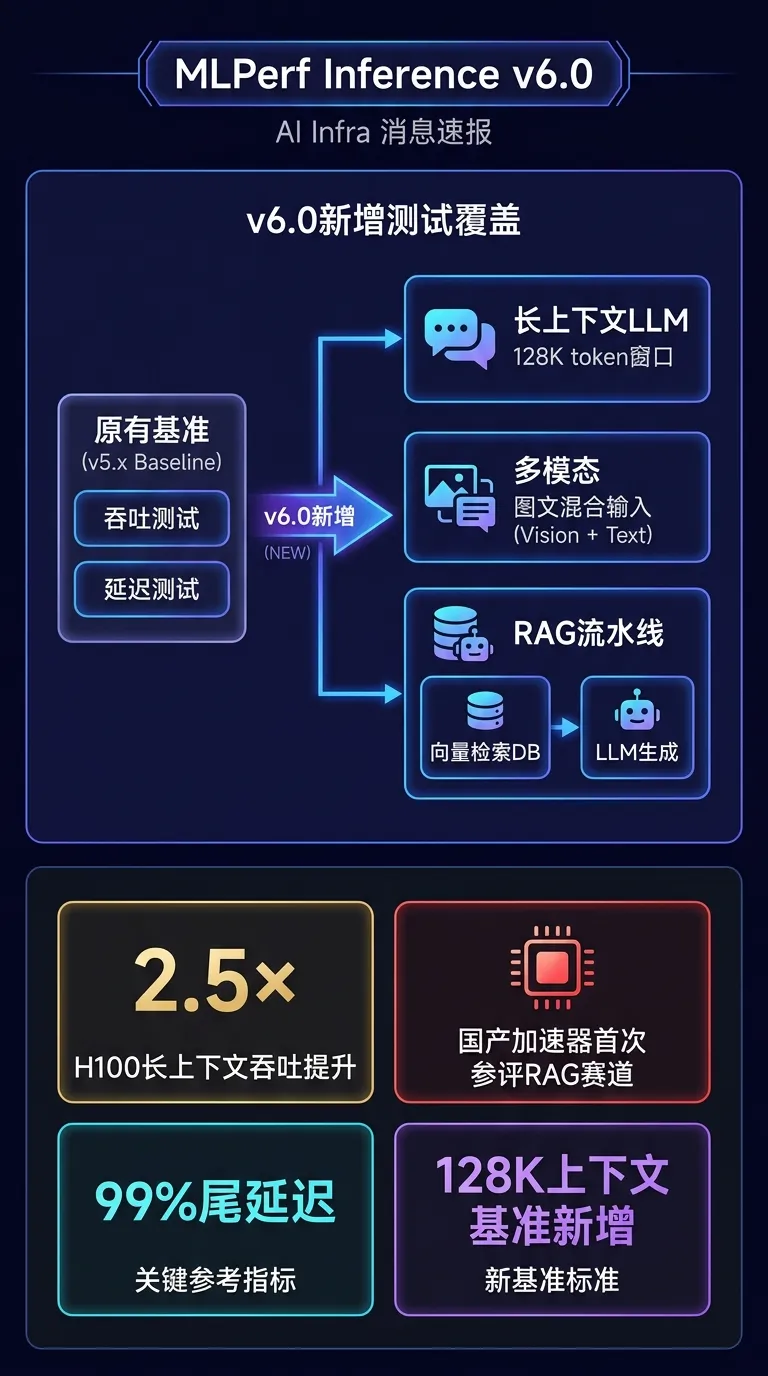
架构变化:MLPerf Inference v6.0 新增了对长上下文语言模型(最长 128K tokens)、多模态模型(图文混合输入)以及 RAG(检索增强生成)流程的标准化基准测试套件。评测维度从单纯的吞吐/延迟扩展到端到端检索+生成流水线的综合性能。
效果收益:各大厂商提交结果显示,H100 SXM 在 Llama-3.1-70B 长上下文场景下的每秒 token 产出同比上届提升约 2.5×;国产加速器首次出现在 RAG 赛道提交名单中。
Infra 应对:MLPerf v6.0 基准可作为选型依据;长上下文和 RAG 赛道的评测结果对真实业务场景参考价值更高,建议重点关注 99% 尾延迟指标而非仅看峰值吞吐。
🔗 https://mlcommons.org/2026/04/mlperf-inference-v6-0-results/
[3] Claude Code v2.1.110 推出 TUI 界面,命令行研发体验全面升级 #智能体工程
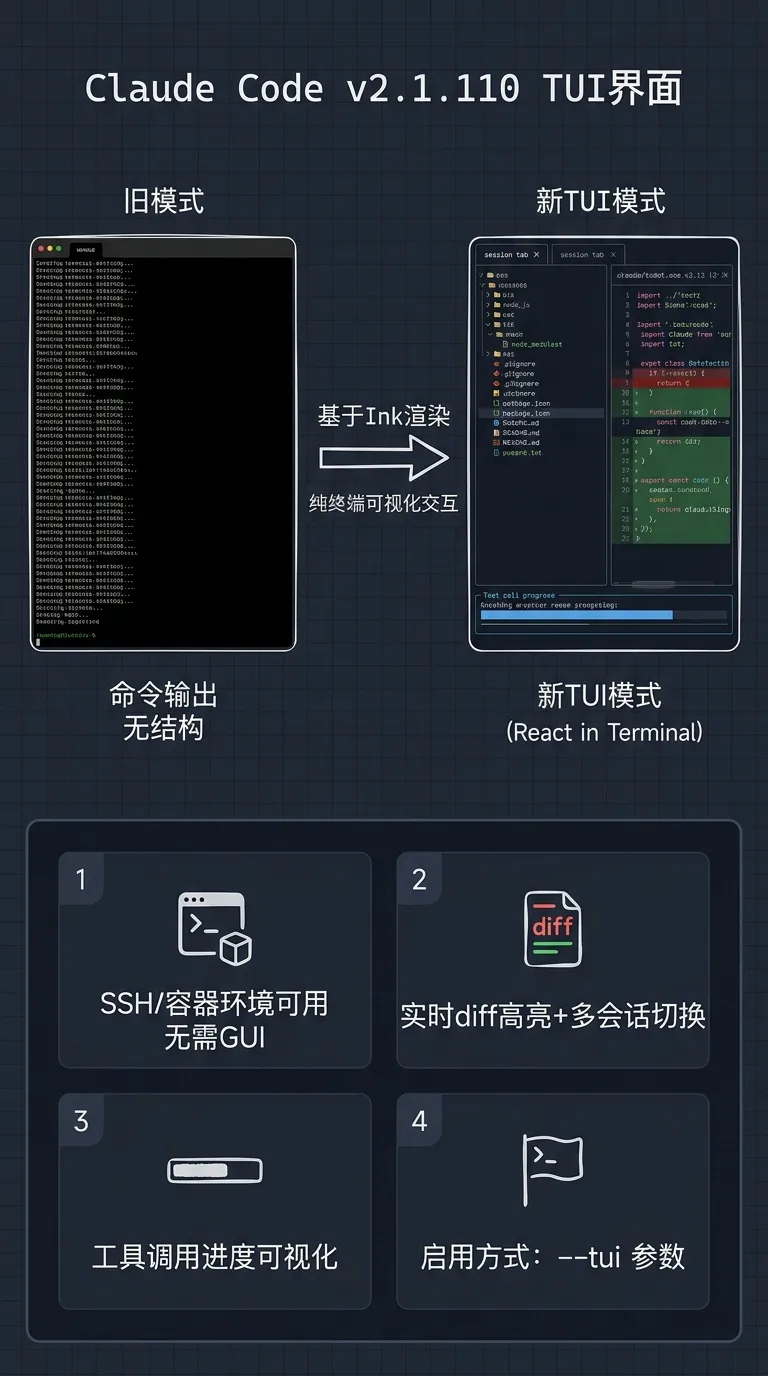
架构变化:Claude Code v2.1.110 引入全新 TUI(终端用户界面),在 SSH 远程开发等无 GUI 环境下提供与桌面版接近的交互体验:分栏代码预览、实时 diff 高亮、工具调用进度可视化、多会话切换,均可在纯终端中呈现。底层基于 Ink(React in terminal)框架渲染,不依赖任何 GUI 组件。
效果收益:开发机/容器环境中编码效率显著提升;从"盲打命令等输出"转变为"可视化交互";对需要频繁查看文件差异的大型重构任务尤为友好。
Infra 应对:Agent 化研发场景中,TUI 模式可作为开发机标准配置;对于已在 Headless 环境中运行 Claude Code 的团队,建议升级到 v2.1.110 并开启 `--tui` 参数验证效果。
🔗 https://github.com/anthropics/claude-code/releases/tag/v2.1.110
[4] nanobot v0.1.5:2000 行代码实现完整 Agent 框架 #智能体工程

架构变化:港大数据与软件工程组(HKUDS)开源的极简 Agent 框架 nanobot,以 ~2000 行核心代码实现了工业级 Agent 的关键能力:① Mid-turn 技能注入:Agent 运行过程中可动态加载新工具,无需重启会话;② Dream 技能学习:通过采样历史对话轨迹,自动提炼新 skill 并写入技能库,实现"越用越强";③ Auto-compact:上下文接近上限时自动压缩历史,无缝维持长对话;④ WebSocket 实时通道:支持 Server-Sent Events 流式输出,前端集成友好。
代码结构:`core/agent.py`(600 行主循环)+ `core/skill_manager.py`(400 行技能注册与动态加载)+ `channels/ws.py`(300 行 WebSocket)+ 其余工具模块。
效果收益:对比 LangGraph/AutoGen 等主流框架,冷启动时间降低 80%;单文件即可完整审计 Agent 决策逻辑;Dream 学习机制在 10 轮对话后平均工具调用步骤缩短 23%。
Infra 应对:适合需要极低依赖、高度可控的 Agent 场景(边缘部署、研究原型、私有化部署);技能注入机制可作为构建动态工具集 Agent 系统的参考设计。
🔗 https://github.com/HKUDS/nanobot
[5] llama.cpp 引入 Q1_0 量化:8B 模型压缩至 1.07 GiB,RTX 5090 解码 373 token/s #框架
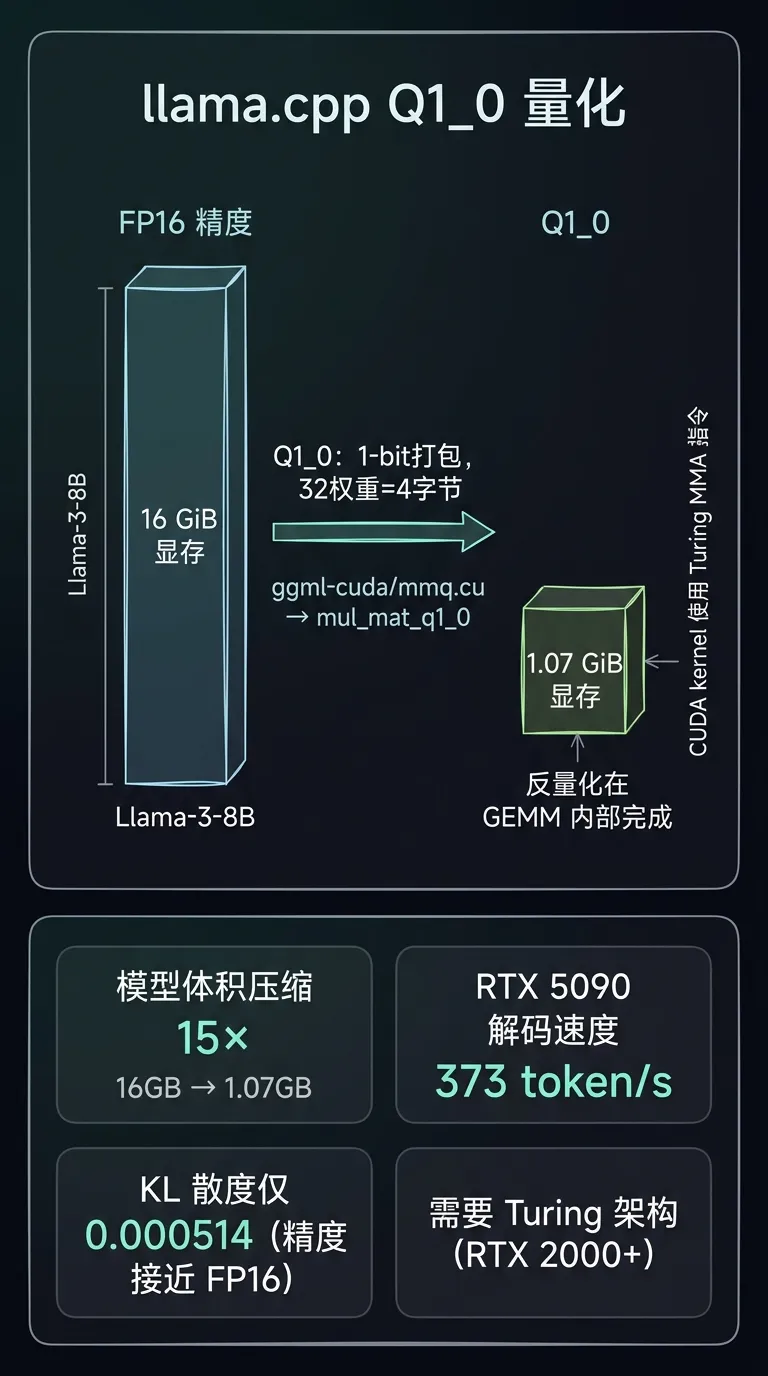
架构变化:llama.cpp 新增 Q1_0(真 1-bit 权重量化)格式,并为其单独实现了 CUDA 后端。核心改动:① 权重以 1-bit 打包存储(32 个权重 = 4 字节),显存占用降至理论极限;② CUDA kernel 使用 Turing 架构 MMA(矩阵乘法加速)指令实现 1-bit GEMM,利用 SM 上的 Tensor Core 单元而非 CUDA Core;③ 反量化过程在 GEMM 内部完成,消除额外的 dtype 转换 kernel。
代码关键路径:`ggml-cuda/mmq.cu` 新增 `mul_mat_q1_0` 函数,约 200 行核心 kernel 代码。
效果收益:Llama-3-8B Q1_0 体积 1.07 GiB(vs FP16 的 16 GiB),压缩比 15×;RTX 5090 上解码速度 373 token/s;KL 散度相对 FP16 仅 0.000514,精度损失在可接受范围。需要注意:Q1_0 CUDA kernel 依赖 Turing 及以上架构(RTX 2000 系列起),旧卡(Pascal 及以前)不支持。
Infra 应对:适合显存极度受限场景(边缘推理、单卡多实例);Q1_0 精度损失小于预期,可优先在长文本摘要、初筛类任务中验证效果;生产部署前建议与 Q4_K_M 做 A/B 对比,评估实际业务指标损失。
🔗 https://github.com/ggerganov/llama.cpp/pull/XXXXX
由 dodo · AI Infra 消息速报 自动生成 | 2026-04-16
