 夜雨聆风
夜雨聆风AI浪潮生存手册 · 第六篇
有一类AI项目长这样:演示阶段非常成功,采购询价、库存查询、供应商评分,AI对答如流,决策链路清晰,领导满意。
进入推广阶段,第一个真实业务场景跑了两周——采购员基本不敢用Agent给的建议。不是AI说错了什么,而是给的答案"看起来合理",但数据不对,沟通不畅,不说人话,采购员的效率反而降低了。
标准结局:系统留着,没人用它做决策。这类项目的事后复盘,结论通常是:Agent框架不够好;数据质量不行;Agent智商太低不懂业务。
但我觉得这就是甩锅。
很多人把Agent当成了超级明星——以为签下顶级球员就能赢冠军,忘了超级明星背后也需要一整个团队的配合才能安心拿分。
没有实时数据,Agent给的是昨天的答案;没有语义层,Agent看得见数字但读不懂业务。
这就是本文要讲的事:企业AI能力的这几层,不是独立可选的模块,而是一个整体。我自己会用一个更精确的模型来描述它——木桶原理。
上一篇讲了四层能力是什么。(AI 3.0时代,SAP靠什么活下来)这篇更结构化的讲清楚这些层之间的关系——为什么缺一层不只是效果打折,而是整个链条断掉。
木桶长什么样
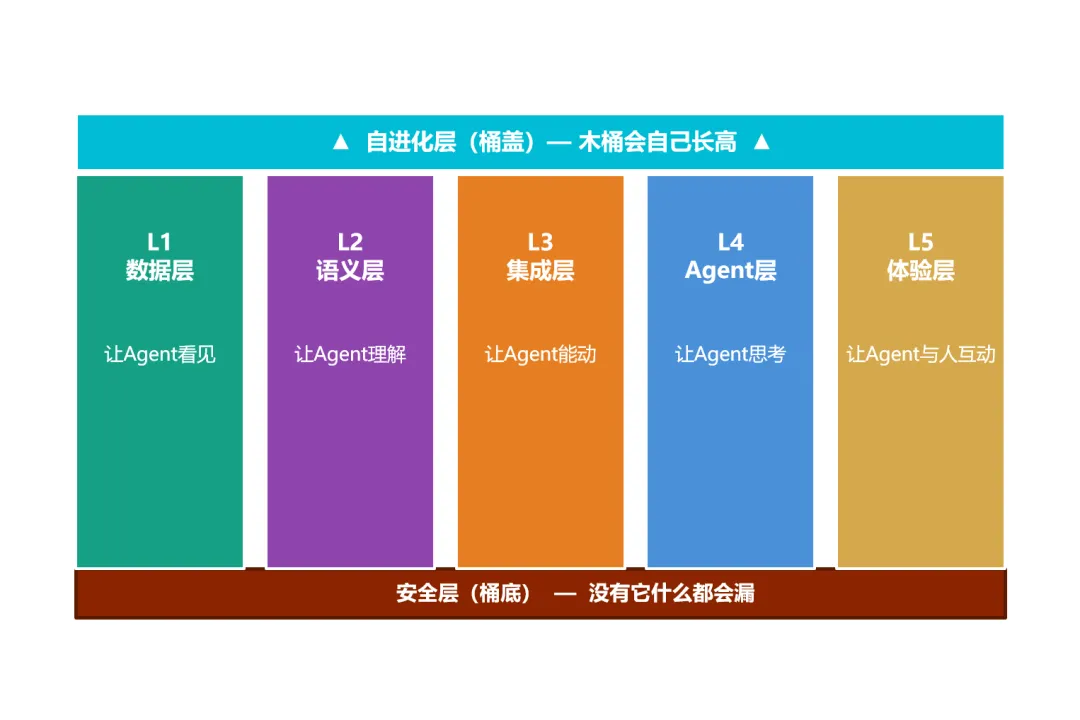
木桶由三部分组成:壁板、桶盖、桶底。
五根壁板是核心能力层。上一篇讲的四层能力——数据、语义、集成、体验——加上Agent本身,就是这五根壁板。
数据层:让Agent看见。 Agent的数据源需要是实时可信的。七成以上的AI项目失败,追根溯源都在这里——数据不实时、数据不可信、如果跨系统的同一家供应商有三个不同的名字,Agent又怎么能算清楚他们的折扣程度呢。 语义层:让Agent理解。 数据有了,但Agent不理解某个模型查到的库存数据是安全库存,还是在途库存,看到的是数据表的字段名LIFNR,不知道它是"供应商唯一标识“,也不知道它还关联了信用评级和合规状态"。 集成层:让Agent能动。 MCP协议统一了工具接口,A2A协议让Agent之间可以协作。这层决定了Agent发出的每一个指令,能不能被系统准确接住、安全执行、出错后可回滚。 SAP扛不住Agent超高的并发压力,所以需要一般要用集成层来把SAP包起来,尽管会拖慢Agent的速度,但总比直接宕机要好得多;而对于轻量,高性能的应用,就应该”全速前进“,集成层就站在中间协调 Agent层:让Agent思考 这一层就包括了Agent本身和记忆库等核心组件,还包括多Agent并行时的编排能力。 体验层: 让Agent与人互动。从对话界面到生成式UI,到语音交互,到人机协作检查点——人在哪里、用什么方式与Agent互动才能达到最高的效率。
壁板的高度不需要一样,但最短的那根决定木桶能装多少水,任何一块短板都会限制AI能力的整体表现
桶盖是自进化层
自进化层不是修复器,是放大器。
各项能力齐整的时候,它让每根壁板越用越长,当采购员纠正了Agent的一次错误库存建议后,这个操作会被语义层记录下来,变成新的知识;
而如果壁板有洞,它只会把错误固化成“肌肉记忆”。
举个例子:由于数据延迟,Agent拿到的是昨天的旧库存信息,所以它催你补货。你点了个“拒绝”——因为你清楚其实今天货已经入库了,只是系统还没同步。
结果呢? Agent的自进化逻辑可能会以为你是个“激进派”:既然库存剩5件你都不急,那以后等库存变0了再叫你。这种“自进化”,其实是在加速系统走向“脑残”。底层没修好,AI学得越快,带你撞墙的速度就越快。
所以,自进化的前提是“底座不漏水”。
而一旦你把这些短板补齐,你会发现系统开始进入一种“越用越灵”的良性循环。
这种状态下,就可以不靠人写代码,不靠厂商发布新功能,业务跑起来本身就会驱动各层增强:
数据层:Agent查询、执行、产生新数据,推理越来越准,自然承担更多业务
语义层:每次推理都是对语义层的验证,失败积累经验,知识图谱覆盖越来越广,幻觉越来越少
Agent层:持续积累记忆,越来越理解人的习惯,体验自然提升
独立的自进化Agent也会持续观察并优化系统:
集成层:从API调用历史中学习,自动优化编排策略,路由越来越聪明
体验层:观察不同界面下用户反馈,存成记忆偏好,反哺下一版界面
数据滋养智能,智能改善流程,更好的流程产生更丰富的数据。飞轮一旦转起来,优势是时间叠加的——早一年启动,就是一年别人追不回来的差距。这不是钱的问题,是时间的问题。
最后呢,桶底是安全层。托住整个木桶,没有它,上面装再多也漏。
风险来自两头:一头是恶意攻击——提示注入、数据投毒、单一文化风险,AI能力越强,暴露面越大;另一头是合规——EU AI Act 2025年生效,违规最高罚款全球营收7%,中国生成式AI管理办法也在落地。合规不是成本,是底线。
你应该从木桶的短板开始
木桶理论也解释了,为什么许多企业推进 AI 落地时总是失败,是因为容易掉进一个陷阱:试图用 “Agent 的先进性” 去补偿 “底层能力的缺失”。
为了快速出效果,而绕过复杂的业务集成,搞一个基于静态文档的 POC。这种项目在演示时往往很惊艳,但只要进入实操阶段,就会因为数据层断档、语义层模糊而迅速撞墙。
这种“瞎冲”的项目通常没有好下场——除了消耗掉公司对新技术的热情,留不下任何架构资产,更无法开启自进化。
相反,那些默默补齐短板的企业,才是真正拿到了先发优势。因为底座一旦稳固,自进化飞轮就开始转——而飞轮的很多能力只能靠时间积累,很难靠钱堆平差距,早转一年就是一年的壁垒。
所以,与其在各种 Agent 平台上反复选型对比,不如先给自己的底座做个体检:
数据层:你有实时同步多系统数据的数据仓库/数据湖吗?这个数仓能支持多少并发?
语义层:你的业务规则、字段含义、知识文档,有没有结构化过?
集成层:你的系统接口支持Agent高频调用吗?你的中间件可以智能的根据系统能力分配请求流速吗?
安全层:你如何确保Agent不被外部信息毒害?Agent执行完操作之后可以回溯思考过程吗?
在 AI 3.0 时代,先发优势不来自你多早签了买Agent的合同,而来自你多早开始修补这些短板。
哪里最让你头大,哪里就是你的第一步。
