 夜雨聆风
夜雨聆风
导读:这次我做的,不是继续给 AI 助手多塞一点记忆,而是把它的记忆系统重新做了一遍。核心不是“记更多”,而是重新分配:什么该默认常驻,什么该分层存放,什么该在需要时再检索。
这篇文章,是被一个真实项目重新点醒的
最近我看到一个挺有意思的项目:Milla Jovovich 参与做了一套 AI 记忆系统,叫 MemPalace。
打动我的不是“明星做 AI”这件事,而是它背后的问题意识:不要让系统替你草率决定什么该记、什么不该记。
这和我这次改 OpenClaw 时,面对的是同一类问题。
我们做的当然不是 MemPalace 那套实现,也不是把 OpenClaw 改成“记忆宫殿”。但问题是一样的:
一个成熟的 AI 系统,不该靠把所有东西都常驻背在身上,来显得自己记性很好。
真正成熟的方向,应该是:
- 有些东西长期常驻
- 有些东西分层归档
- 有些东西按需检索
- 让系统知道什么该一直带着,什么该需要时再取
所以这次我做的,不是给 OpenClaw 再塞更多记忆。
而是反过来做了一次手术:
把它的记忆系统,从“重常驻、大仓库、混层堆积”,改造成“轻常驻、检索优先、分层归位”。
真正的问题,不只是聊天变长
很多人第一次碰到 context 变大,直觉都会落在聊天记录上:
- 是不是聊太久了?
- 是不是 `MEMORY.md` 写太多了?
- 是不是多 `/new` 几次就好了?
但这次真往下拆,我发现问题没有这么表面。
把 context 顶起来的,往往不只是一轮对话,而是整套默认启动负担:
- 系统提示本身
- 工具 schema
- available skills 列表
- workspace 常驻注入文件
- 没有分层、不断累积的“伪记忆”
也就是说,真正的问题不是“聊太久”,而是:
系统默认背了太多东西。
如果底层结构不改,`/new` 只能清掉聊天,清不掉真正的大包袱。
所以这次要改的,不是删记忆,而是重做结构
看到 context 大,很多人第一反应是删。
但删通常只能解决眼前,不解决结构:
- 删狠了,系统失忆
- 删轻了,context 还是胖
- 删完之后,往往还会继续乱长回来
所以这次从一开始,我定的目标就不是“少一点内容”,而是:
把记忆从“大仓库常驻”改造成“轻常驻 + 检索优先 + 分层归位”。
翻成人话就是:
- 长期硬规则,常驻
- 稳定 workflow,沉成 topic
- 排障过程和历史证据,沉到 raw
- 当天发生的事,记进 daily
- 真要回忆时,再按需取
动手之前,我先定了四个判断
这轮能收住,不是因为搬文件搬得勤,而是因为先把底层判断定清楚了。
1)先升级,再优化
先把 OpenClaw 升到较新的稳定版本,先确认主系统、备份链路、cron、插件都站稳。
原因很简单:底座不稳,后面的改造容易返工。
2)先打第一战场,不急着碰第二战场
这次先收最可控、收益最大的部分:
- `MEMORY.md`
- `AGENTS.md`
- `TOOLS.md`
- `memory/` 的分层结构
而不是一上来就去碰更深层的大头。
3)保守迁移,不打断启动链路
一开始没有把所有 daily 直接暴力搬走。
因为前面先问了一个更现实的问题:
session startup 的读取链路,会不会先被我自己搞断?
所以前期做法是:先建新目录,先写 topic 样板,先瘦常驻层,等结构和规则收住,再切 daily 主路径。
4)topic 优先,raw 补充,daily 定时间
不是所有历史都该常驻,也不是所有历史都该直接拿原文来回答。
更合理的顺序应该是:
1. 先查 `topic`
2. 再查 `raw`
3. 最后查 `daily`
这一个顺序一改,AI 的“记忆气质”就会完全不一样。
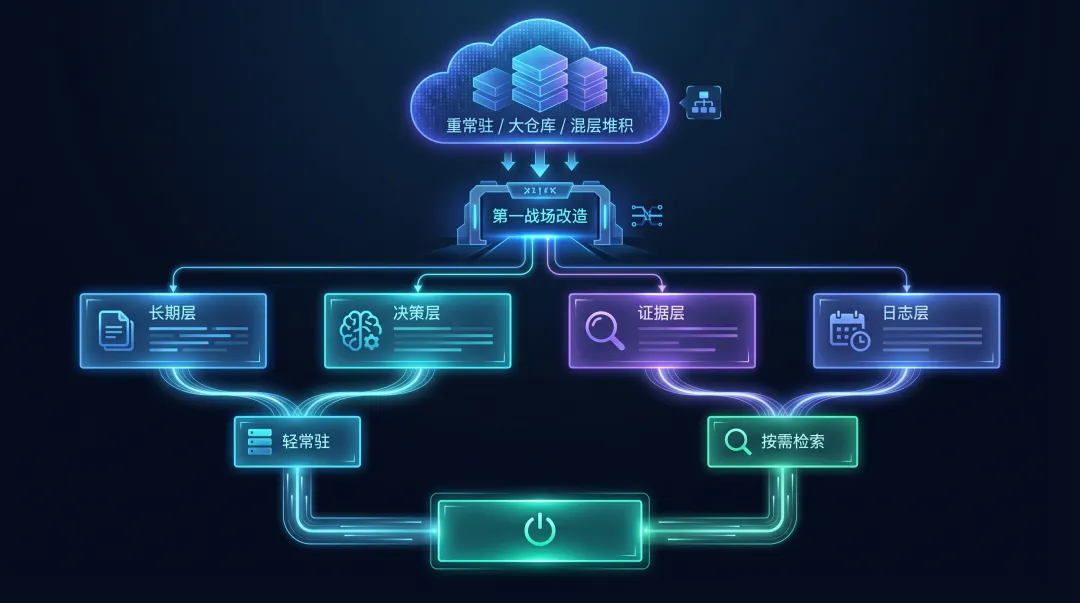
真正开工后,我做了三件关键的事
第一件:先把常驻层瘦下来
先收三份最关键的常驻文件:
- `MEMORY.md`
- `AGENTS.md`
- `TOOLS.md`
重点不是简单删内容,而是改角色:
- `MEMORY.md` 只保留长期规则、硬约束、稳定偏好、topic 路由
- `AGENTS.md` 回到启动顺序、分层原则、安全边界、执行风格
- `TOOLS.md` 只保留稳定目录、本机速查和高频路径规则
这一步做完以后,最直接的变化不是“好看了”,而是:
每个文件重新知道了自己该干什么。
第二件:把记忆正式拆成四层
这一步,才是整个系统的骨架。
我们把记忆明确拆成了四层:
- 长期层:`MEMORY.md`
- 决策层:`memory/topics/`
- 证据层:`memory/raw/`
- 日志层:`memory/daily/`
真正重要的,不是目录更工整了,而是:
每类信息终于有了明确语义。
以前的问题恰恰是:规则像日志,日志像专题,专题像仓库,仓库又被当成常驻层。系统当然会越用越乱。
第三件:把 `memory/` 根目录彻底清空
这是这轮改造里最有仪式感的一刀。
前面先做低风险归位:脚本移走、JSON 移走、导出报告移走、tmp 文件移走、一批典型 raw 先迁进 `memory/raw/`。
再往后继续推进:抽 topic、迁 raw、把根目录剩余 `.md` 全部分流进 `daily/` 和 `raw/`。
最终结果是:
`memory/` 根目录 `.md` 文件数 = 0。
这一刀不只是视觉上清爽,而是从结构、语义、运行口径三个层面,把系统真正收了回来。

最后的结果,不是完美,而是 9.9 分收口
如果只图好看,完全可以在结尾写一句“这套系统已经完美收工”。
但那不诚实。
更准确的说法是:
第一战场已经做到 9.9 分:结构层完成,运行口径完成,地毯式审计通过,正式进入维护态。
为什么不是 10 分?
因为还留着一点小尾巴:
- 有些高价值 topic 还能继续补强
- `topics` 未来还能做第二轮统一清洗
- `archive` 目录还没真正启用
但这些已经不再是硬伤,只是后面还能继续抠的边角。
这次改造给我最大的启发
如果只用一句话总结,我会写:
记忆不是塞得越多越好,关键是默认带什么、按需取什么。
很多人做 memory,最后都会掉进两个坑:
- 觉得“多存一点总没错”
- 觉得“都带着最保险”
但越这么做,系统越容易变成:
- 常驻越来越胖
- 规则越来越混
- 新旧信息越来越打架
- 该记住的没记稳,不该常驻的反而一直背着
真正成熟的方向,反而是:
- 把长期规则和高权重记忆提出来
- 把 workflow 总结成 topic
- 把历史过程沉到底层 raw
- 把当天活动放进 daily
- 让 retrieval 真正成为默认方式
这样系统才会越用越稳,而不是越用越重。
结论:这不是一次整理文件,而是一次给 AI 助手重做记忆结构的手术。它真正解决的是:如何让一个 AI 系统,不靠越来越重的硬背,也能长期保持稳定、清醒和可维护。
