 夜雨聆风
夜雨聆风
过去一年,AI Agent 的能力边界被迅速拉高,
函数调用、工具链编排、长上下文、多轮推理,这些问题基本已经被解决。
但当你试图把 Agent 接入真实系统时,会遇到一组更棘手的问题:
消息入口如何统一接入?
多渠道会话如何持久化与同步?
工具调用的权限与隔离如何设计?
失败任务如何观测、追踪与重试?
配置变更如何做到不停机生效?
这些问题有一个共同点:
它们都不属于“模型能力”,而属于“系统工程”,也就是如何在复杂环境中,稳定、持续、可治理地运行。
OpenClaw,在这方面做出了很好的示范。
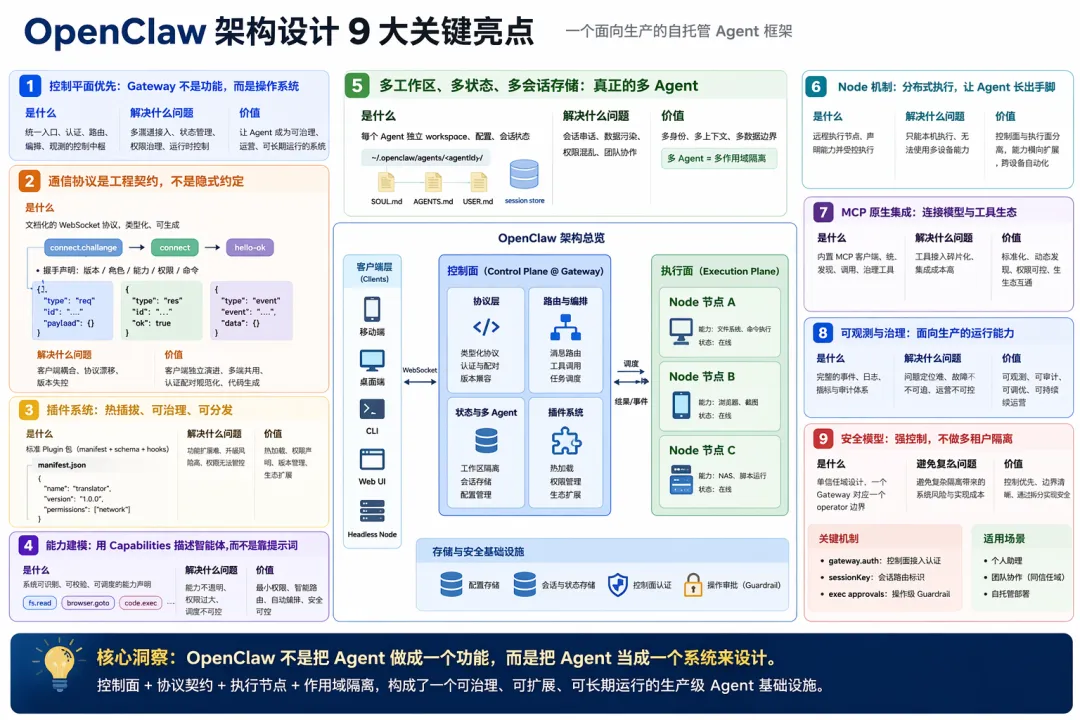
一、 OpenClaw 的核心架构:一个 Gateway,统一所有入口、状态与路由
OpenClaw 的架构核心非常明确:一个长期运行的 Gateway 进程,统一拥有所有消息入口、会话状态、路由能力和控制接口。
它的中心是一个单一、长生命周期的 Gateway 进程。
这个 Gateway 持有所有消息面:比如 WhatsApp、Telegram、Slack、Discord、Signal、iMessage、WebChat。
控制端客户端,比如 macOS App、CLI、Web UI、自动化模块,也都通过 WebSocket 接入同一个 Gateway。
节点设备,例如 macOS、iOS、Android 或 headless 节点,同样走这条连接,但会显式声明自己的role: node以及能力边界。
官方还强调:每台主机只应有一个 Gateway,它是该主机上唯一打开 WhatsApp 会话的地方。
这意味着,OpenClaw 的系统组织方式不是“每个端各跑各的 Agent”,而是“所有端都连到同一个神经中枢”,这个神经中枢负责三件事:
第一,维护外部提供方连接。
第二,暴露类型化的 WebSocket API。
第三,作为会话、路由、事件和状态的单一事实来源。官方文档直接把它称为 sessions、routing、channel connections 的single source of truth。
这不是简单的“消息转发器”,而是一个统一控制面 + 统一状态面。
OpenClaw 的基本思路不是“每个端各跑一个 Agent”,而是“所有入口都汇聚到一个中枢”。
这一步非常关键,因为生产系统最怕的不是功能不够,而是状态分裂:渠道各自维护状态,工具各自维护上下文,客户端各自保存逻辑,最后整套系统没有单一事实来源。
而生产级系统最怕的,恰恰就是状态分裂、入口分裂、权限分裂,
OpenClaw 的第一刀,就是先把这些分裂消掉。
这套设计背后,有一个很现实的工程判断:
Agent 系统真正的复杂度,不在单轮推理,而在跨轮、跨端、跨任务、跨时间的状态协调。
而 Gateway 正是协调器。
没有它,Agent 只是一个会调用工具的大模型,有了它,Agent 才开始像一个能持续运行的系统。
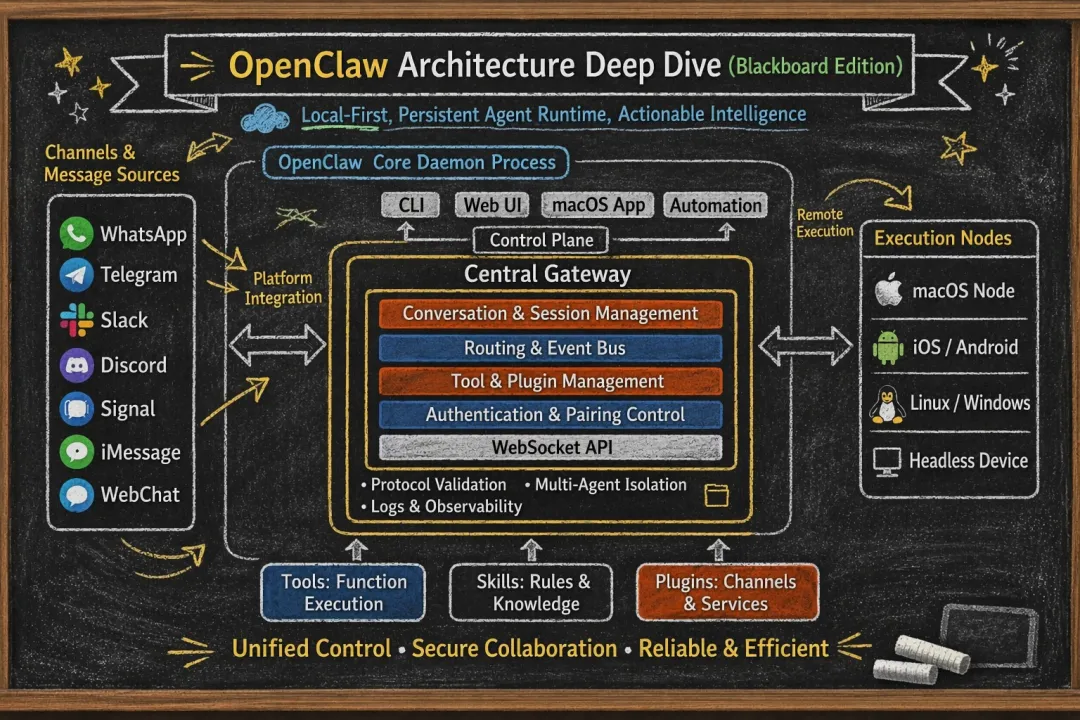
二、协议设计:把通信协议变成“系统契约”
1. 是什么(What)
2. 解决什么问题(Why)
3. 它是怎么实现的(How)
使用 TypeBox 定义 schema 自动生成 JSON Schema 可进一步生成客户端模型(如 Swift)
4. 带来的架构影响(Impact)
三、 第三个关键设计:工具、技能、插件三层分离
OpenClaw 没有把“能力扩展”混成一锅粥,而是明确分成三层:
工具,是 Agent 真正调用的 typed function,比如exec、browser、web_search、message。
技能,是注入系统提示的SKILL.md,告诉 Agent 什么时候该用什么工具、遵循什么约束、按什么步骤执行。
插件,则是把 channel、model provider、tools、skills、speech、realtime transcription、image generation、web fetch 等能力打包成可安装扩展。
这三层分离非常高明,因为它避免了两种常见错误:
一种错误是“所有能力都写进 prompt”,结果模型知道很多规则,但没有稳定执行面;
另一种错误是“所有能力都做成工具”,结果工具很多,但模型不知道何时用、怎么用、用到什么边界。
OpenClaw 的做法是:工具负责执行,技能负责方法,插件负责分发与装配。
这让 Agent 能力不只是“多”,而是“可组织”。
尤其是技能这一层,非常像给 Agent 提供了一层轻量操作手册。
官方文档明确说明,技能会在会话开始时做快照,同一会话内复用。
当 skills watcher 开启或新节点出现时,还能在会话中途刷新,相当于一种热更新。
这说明 OpenClaw 并没有把 prompt 当成一次性文本,而是把它当成运行时可治理配置的一部分。
四、第四个关键设计:插件系统不是“随便挂钩子”,而是有清晰边界
OpenClaw 的插件系统有两个很值得注意的地方。
第一,它要求原生插件必须携带openclaw.plugin.json,并且这个 manifest 要能在不执行插件代码的前提下,完成身份识别、配置校验、认证与 onboarding 元数据暴露、静态能力描述、UI hints 等工作。
缺失或非法 manifest 会直接阻断配置验证。
第二,它把核心与插件的边界切得很清。
比如消息能力上,OpenClaw 在核心里只保留一个共享的message工具;
channel 插件负责各自平台的 action discovery、capability discovery、会话/线程语法,以及最终执行动作的 adapter。
也就是说,核心不再硬编码 Slack、Discord、Telegram、WhatsApp 的动作细节,而是把这些都推回插件边界。
这套设计有一个非常大的工程收益:
配置验证、UI 表单、能力发现,可以先于运行时代码完成。
也就是说,系统可以在“插件还没真正跑起来”之前,就知道它是否合法、能干什么、需要什么配置。
这才是真正可运营的扩展系统。
否则,一切都得先执行代码再说,那就不叫插件系统,那叫动态风险源。
五、第五个关键设计:多工作区、多状态、多会话存储
OpenClaw 的多 Agent 设计也非常像生产系统,而不是“给不同 prompt 起不同名字”。
官方文档说明,单 Agent 模式下默认agentId=main,
而多 Agent 模式下,每个 agent 都有自己独立的 workspace、SOUL.md、AGENTS.md、可选USER.md,还有独立的agentDir与 session store,路径落在~/.openclaw/agents/下;
不同 agent 可以绑定不同渠道账号、不同人格、不同会话空间,默认不串话,除非显式配置跨 agent 的 transcript search。
这件事的含义非常大:很多人以为多 Agent = 多人格,但在工程上,多 Agent 真正意味着的是:
多身份、多上下文、多数据边界、多权限边界。
OpenClaw 明确把这些东西拆开了。
这就让一个 Gateway 可以服务多个“人”或多个“岗位”,但仍然把脑子、记忆、渠道、状态分隔开来。
这一步一旦做到,Agent 才有资格从个人玩具走向团队系统。
六、第六个关键设计:Node 机制,把 Agent 变成“可分布式执行”的系统
OpenClaw 引入了一个非常关键的角色:Node(节点)。
可以把它理解为:Agent 的远程执行端
Node 不是普通客户端,而是以 role: node 接入 Gateway 的执行节点。
它在连接时会主动上报:
自己是谁(设备身份)
能做什么(capabilities)
能执行哪些命令(commands)
权限边界在哪里
同时,它可以向系统暴露设备能力,例如:
文件与命令执行(Linux / Windows / NAS)
浏览器能力(browser proxy)
摄像头、屏幕录制、定位等(移动设备)
这个设计解决了什么问题呢?
在没有 Node 的情况下,Agent 的执行范围是被锁死的:所有动作只能发生在 Gateway 所在机器
这会带来一个明显限制:
不能操作远程服务器
不能使用其他设备能力
不能做跨环境自动化
引入 Node 后,发生了什么变化?
OpenClaw 把执行面拆出来,变成一个可扩展的分布式执行网络:
Gateway 负责“决策与调度”,Node 负责“具体执行”。
这意味着:
Agent 可以在远程服务器上执行任务
可以调用不同设备的能力(电脑 / 手机 / NAS)
可以跨机器完成复杂工作流
架构本质:控制面 vs 执行面分离,这个设计可以用一句话总结:
Gateway = 控制面(Control Plane)
Node = 执行面(Execution Plane)
一旦这两层分离,系统能力会发生质变:
执行能力可以横向扩展(加 Node 即可)
不同设备能力可以被统一调度
权限、审批、路由依然集中在 Gateway 控制
Node 机制的本质,是把 Agent 从“只能在本机调用工具的程序”升级为:“可以在多机器、多设备上执行任务的分布式系统”
七、第七个关键设计:自动化不是补丁,而是系统内建能力
OpenClaw 没把定时任务、后台任务、工作流追踪当成外围脚本,而是内建进了系统。
官方文档说明,Cron 是 Gateway 内建调度器,运行在 Gateway 进程内部,任务会持久化到~/.openclaw/cron/jobs.json,重启后不会丢。
所有 cron 执行都会创建 background task 记录。
后台任务系统则专门跟踪脱离主会话的工作,包括 ACP、subagent、isolated cron、CLI 发起任务等,并维护从queued → running → terminal的状态流转。
terminal 记录默认保留 7 天。
不仅如此,OpenClaw 还有 hooks 机制:内部 hook 会在/new、/reset、/stop、session compact、agent bootstrap、gateway startup等事件上触发。
外部 webhook 则允许外部系统触发 OpenClaw 工作。
更进一步,OpenClaw 的“Standing Orders”设计,其实已经很接近企业自动化里的 SOP。
官方建议把长期授权、触发条件、审批门槛、升级规则写进AGENTS.md,再由 cron 负责“什么时候执行”。
这其实把“授权模型”和“调度模型”拆开了:前者定义能做什么,后者定义何时做。
这非常像生产系统,而不是聊天机器人。
因为生产系统从来不是“你叫它做一次,它做一次”,而是“它持续在规则内运行,并在异常时升级”。

八、第八个关键设计:配置验证、热更新、诊断工具等完善的运维能力
判断一个 Agent 系统是否具备生产级,最直接的方法,不是看它的 Demo,而是看三件事:配置如何更新?计划任务怎么跑?出问题怎么查?
OpenClaw 在这三件事上都做得很完整。
首先,配置方面,Gateway 支持 hot reload。
官方配置文档说明,~/.openclaw/openclaw.json会被自动监控;
默认hybrid模式下,安全变更立即热应用,关键变更自动重启;
channels、agents、models、routing、hooks、cron、session、messages、tools、skills、audio、UI 等大部分配置都可以无停机生效,真正需要重启的主要是gateway.*这一类监听和认证层参数。
其次,自动化方面,cron 是 Gateway 内建调度器,而不是外挂脚本。
官方说明,cron 运行在 Gateway 进程内,任务会持久化到 ~/.openclaw/cron/jobs.json,重启不会丢;
所有 cron 执行都会生成 background task 记录。
再次,诊断方面,OpenClaw 内置了比较系统的 runbook:openclaw status、openclaw gateway status、openclaw doctor、openclaw security audit、openclaw channels status --probe 等命令都围绕统一的状态面组织。
一套完善的运维能力是生产级Agent稳定运行的基石。
九、安全模型:强控制,但不做多租户隔离
1. 是什么(What)
OpenClaw 采用的是一种单信任域(single trust domain)安全模型:
一个 Gateway 对应一个 operator(操作者)边界
默认假设系统内所有组件处于同一信任环境
不以内建“多租户隔离”为目标
2. 解决什么问题(Why)
在 Agent 系统中,安全通常有两条路径:
路径一:强隔离(多用户、多租户、零信任)
路径二:强控制(单用户或单团队,集中治理)
OpenClaw 选择的是第二条:
优先保证系统可控,而不是在单实例内做复杂隔离
这样可以显著降低系统复杂度:
不需要在每一层做权限隔离(会话 / 工具 / 状态)
不需要构建完整的多租户安全模型
控制逻辑可以集中在 Gateway
3. 它是怎么实现的(How)
从具体机制可以看得很清楚:
gateway.auth
→ 只负责控制面接入认证(谁能连进来)
sessionKey
→ 只是会话路由标识(消息属于哪个上下文)
exec approvals
→ 是操作级确认机制(是否允许执行某个动作)
这些能力的共同特点是:它们都在“控制行为”,而不是“隔离数据”
4. 带来的架构影响(Impact)
这种设计意味着一个重要结论:安全边界不在系统内部,而在系统外部
也就是说,如果你的场景涉及:
多用户共享
不同信任级别(mixed-trust)
潜在对抗用户
正确做法不是在一个 Gateway 内做隔离,而是:
拆分为多个 Gateway 实例
使用不同 OS 用户或容器
必要时隔离到不同主机
OpenClaw 选择的是:用“系统边界拆分”来解决安全问题,而不是在系统内部做复杂隔离。
为什么这个设计是成熟的?
很多系统的问题,不是能力不够,而是边界不清。
OpenClaw 的做法恰恰相反:
明确不做什么(不做强多租户隔离)
明确适用场景(单人 / 单团队 / 同信任域)
明确扩展方式(通过拆分 Gateway 实现隔离)
这是明确的架构取舍:放弃复杂的多租户隔离模型,换取更简单、可控、可落地的系统边界。
这在工程上是更现实的路径,因为相比“理论上支持一切”,更重要的是清楚系统的安全边界,并让它始终成立。
10. OpenClaw 真正拆开的,是 Agent 时代的软件骨架
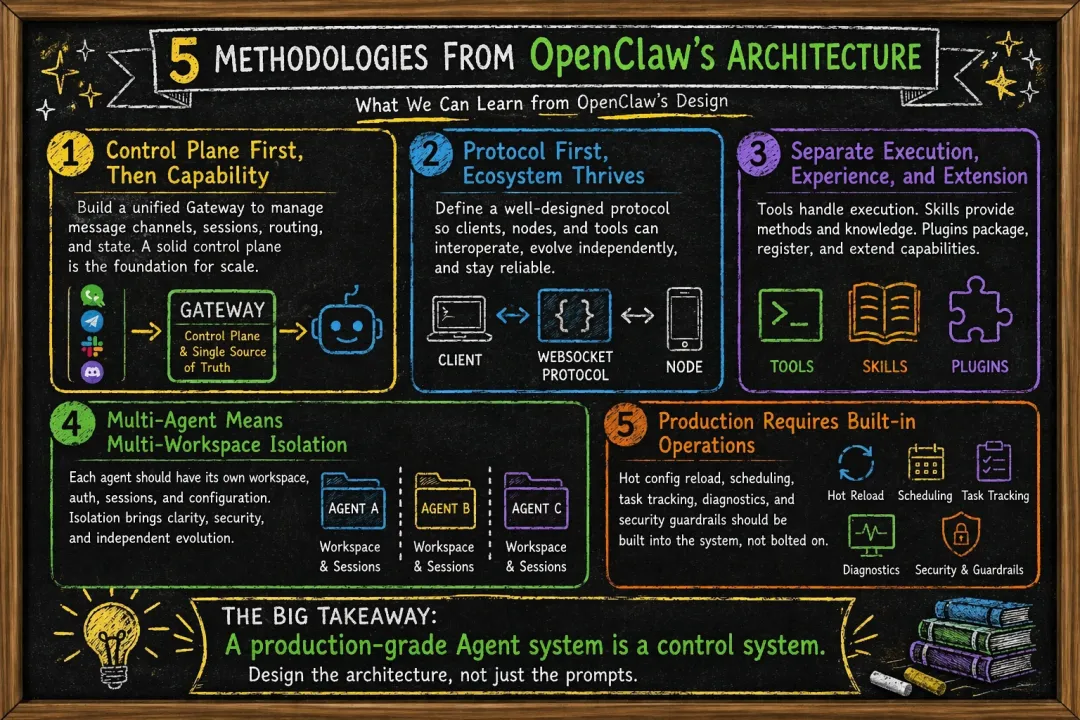
OpenClaw 真正值得学的,不是某个功能,而是它背后的系统方法论
如果把 OpenClaw 抽象成方法论,我认为它至少给了 Agent 系统设计五个重要启发。
第一,先做控制平面,再做功能平面。
没有统一 Gateway,Agent 很快就会碎成一堆渠道适配器和脚本。
第二,先定义协议,再放大生态。
只有协议硬了,客户端、节点、插件和自动化模块才能并行演进。
第三,把“能力”拆成执行、经验、装配三层。
也就是工具、技能、插件三分。这样才能既能扩展,又能治理。
第四,把多 Agent 当成多工作区系统,而不是多 prompt 系统。
否则你做不出真正的身份隔离、会话隔离和长期记忆隔离。
第五,承认 Agent 是一个持续运行系统,而不是一次性问答接口。
所以你必须认真处理 cron、hooks、tasks、subagents、health、status、schema、hot reload、supervision,这些才是生产级系统稳定运行的基石。
OpenClaw让我们看到,真正的生产级 Agent 系统,不是“在聊天框里加几个工具按钮”,而是:
以 Gateway 为控制平面,
以协议为系统总线,
以插件为扩展机制,
以多 Agent 为作用域隔离,
以节点为执行平面,
以热更新、调度和审计为运维底座。
这些才是 OpenClaw 最值得所有 Agent 开发者认真研究的地方。

