 夜雨聆风
夜雨聆风

从CUDA执行模型到AI工厂:
一文读懂GPU架构、GEMM优化与NVIDIA全栈演进


在今天的人工智能时代,GPU 早已不是单纯用来打游戏、做图形渲染的硬件,而是支撑整个 AI 训练、推理、科学计算、大数据分析的核心算力底座。不管是大语言模型训练、多模态生成,还是自动驾驶仿真、分子模拟,背后都离不开 GPU 提供的大规模并行计算能力。
但绝大多数人对 GPU 的理解,还停留在 “算力很强”“显存很大” 的表层认知,并不清楚它为什么适合并行计算、内部是如何执行任务、数据是如何流动、性能瓶颈到底在哪里,更不理解 NVIDIA 为什么能从一家显卡公司,一步步变成全球 AI 算力的定义者。
这篇文章,我们从最底层的 CUDA 执行模型开始,一步步讲透 GPU 架构设计、GEMM 核心优化逻辑,再到最新的 Vera Rubin 全栈平台,让你真正看懂 GPU 从 “加速卡” 到 “AI 工厂” 的完整演进。
01 为什么 GPU 天生
就是大规模并行计算王者
GPU 并不是为 AI 而生,它最初的设计目标,是解决图形渲染里极其密集、高度重复、可以同时开展的计算工作。比如一张 4K 图片有 800 多万个像素,3D 场景里有数十万顶点、纹理、光照计算,这些任务彼此独立、规则统一,非常适合用大量计算单元同时处理。
随着 NVIDIA 推出 CUDA 通用并行计算平台,GPU 被彻底解放,不再局限于图形管线,而是开放给科学计算、数据库、深度学习等所有需要高吞吐、高并行的场景。到今天,GPU 已经从 “配件” 变成了算力主力。
要理解 GPU,必须先看懂它和 CPU 完全相反的设计哲学:
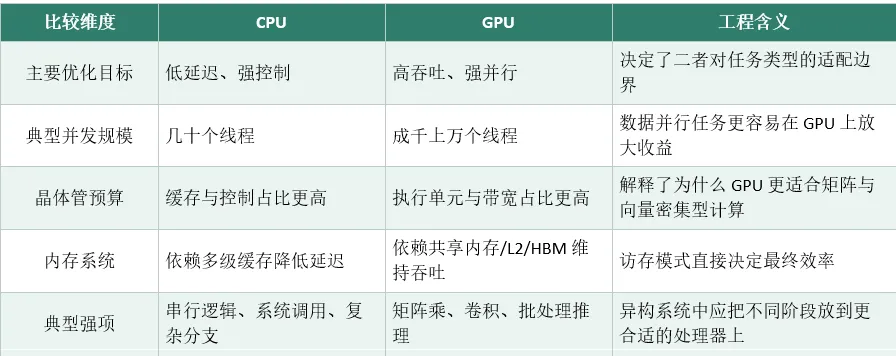
CPU:追求低延迟、强控制,把大量晶体管用在缓存、乱序执行、复杂分支判断上,擅长少量线程、复杂逻辑、快速响应,像一个精准处理复杂任务的总指挥。
GPU:追求高吞吐、强并行,把面积和功耗优先分配给执行单元与数据通路,用牺牲单线程性能的方式,换取整体吞吐量的巨大提升,像一支成千上万同时作业的施工队。
两者不是替代关系,而是明确分工:CPU 负责系统调度、任务编排、复杂控制流;GPU 负责规则统一、数据量大、并行度高的计算任务。
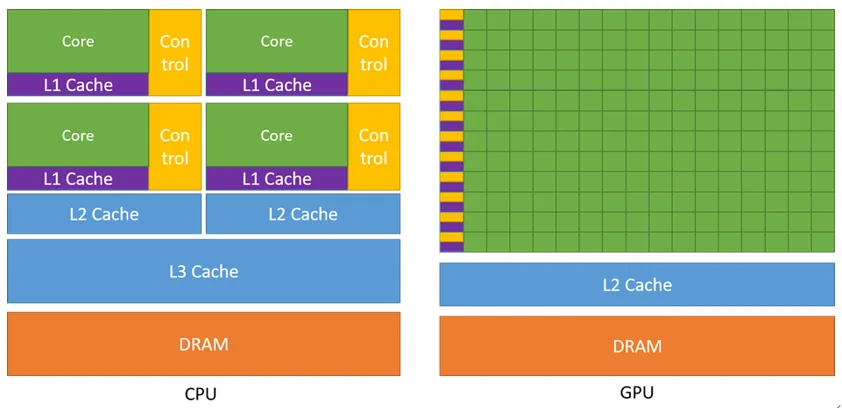
简单说:CPU 擅长把一件事做得很快,GPU 擅长把一万件事同时做完。
02 异构系统:
Host、Device 与数据通路
在 CUDA 体系里,计算机被看作一个异构计算系统,被清晰地分成两个部分:
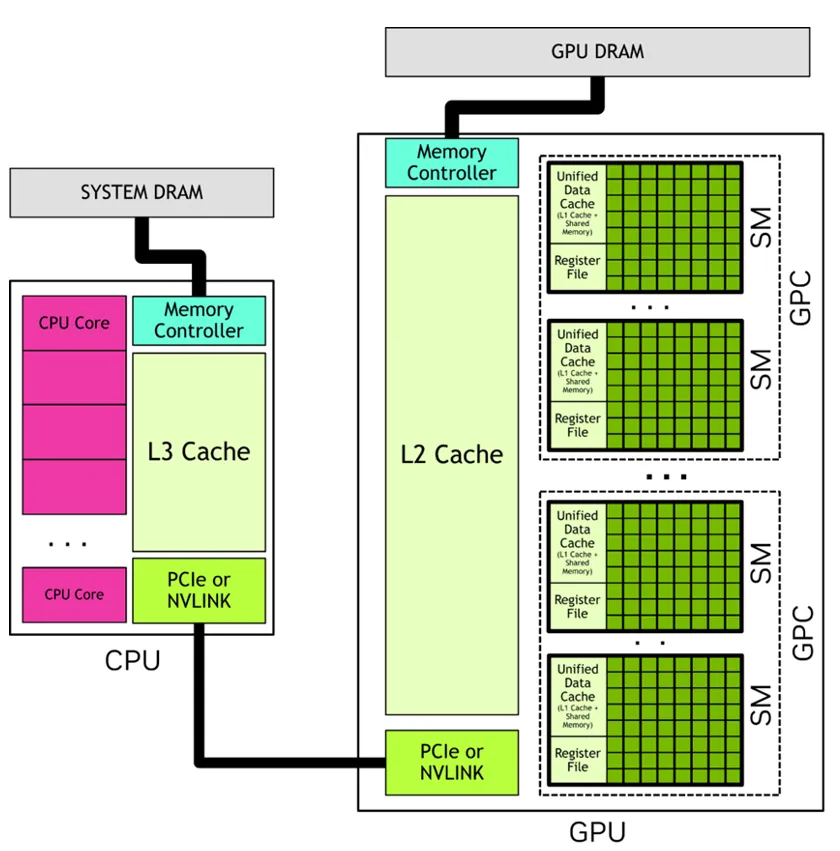
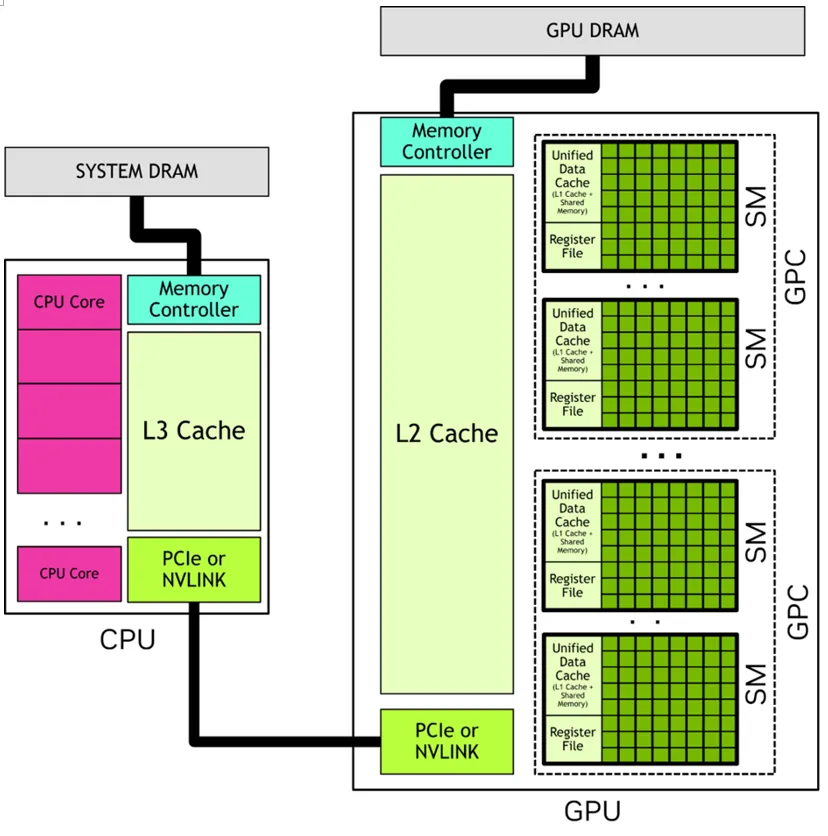
Host(主机端):CPU + 系统内存,负责整个程序的启动、数据准备、内存分配、任务配置,并最终发起 GPU 计算调用。
Device(设备端):GPU + 显存,负责真正的大规模并行计算执行。
我们在代码里写的 GPU 计算,本质是:Host 先把数据准备好,然后把一段 “要在 GPU 上并行执行的函数” 发送给 Device,这段函数就叫 Kernel。
Kernel 是整个 CUDA 模型里最核心的工作单元,可以理解为 “交给 GPU 并行跑的一段计算逻辑”。Host 只负责启动和配置,Device 则会启动成千上万的线程,用同一段代码并发执行,处理不同的数据。
在异构系统里,数据位置是性能第一公理:
CPU 访问系统内存、GPU 访问显存都极快,但跨设备访问(CPU 读显存、GPU 读系统内存)非常慢。所以高性能优化的第一步,不是优化指令,而是让数据尽量停留在最合适的位置,减少来回搬运。
03 CUDA 执行层级:Grid→Block→Warp→Thread
GPU 要同时调度成千上万的线程,不能混乱执行,CUDA 用一套四层层级结构,既方便程序员编写,又方便硬件高效调度:
Thread(线程):CUDA 最小的执行实体,每个线程负责处理一个或少量数据元素,拥有独立的寄存器和私有状态。
Warp(线程束):硬件调度的基本单位,固定 32 个线程为一组,GPU 以 Warp 为单位发射指令,32 个线程锁步执行同一条指令。
Block(线程块):一组可以互相协作的线程,整个生命周期只会驻留在一个 SM 上,内部可以用共享内存和同步屏障高效通信。
Grid(网格):一次 Kernel 启动所产生的所有线程块的集合,代表一次完整计算任务的总规模。
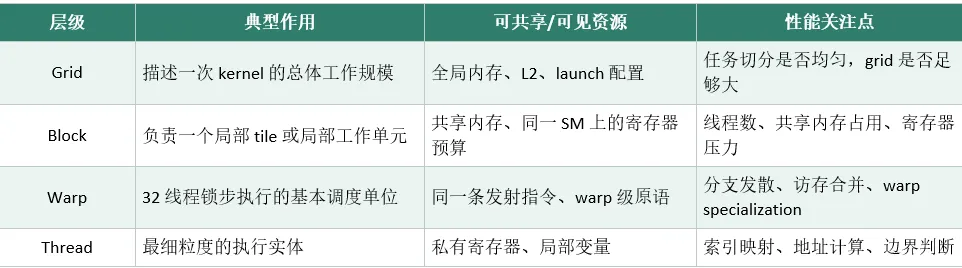
CUDA 使用 SIMT(单指令多线程) 执行模型:
编程时,每个线程看起来是独立执行的;但在硬件里,指令是以 Warp 为单位统一发射,32 个线程一起执行。
这里有一个关键性能问题:Warp Divergence(分支发散)。
如果同一个 Warp 里的线程进入不同的 if/else 分支,硬件只能分批执行,暂时屏蔽不活跃的线程,导致执行效率大幅下降。
而 SM(Streaming Multiprocessor) 是 GPU 真正执行计算的核心单元,一个 Block 只会在一个 SM 上完整执行,不会被拆分,这也是 Block 内部可以高效共享数据的原因。
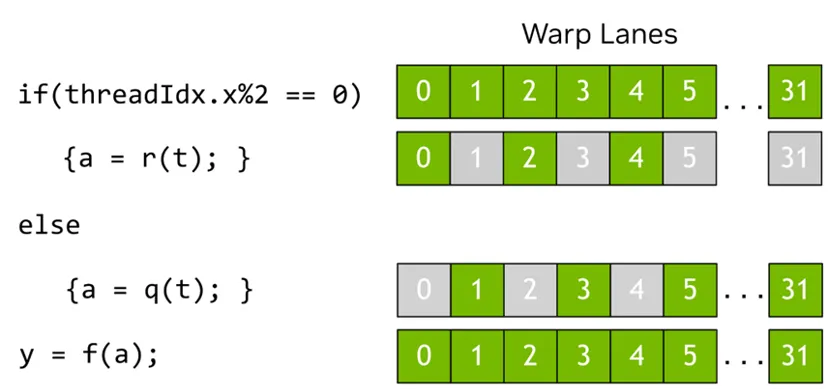
理解这四层结构,你就看懂了 CUDA 程序是如何从软件代码,一步步映射到 GPU 硬件上执行的。
04 内存层级:
比 TFLOPS 更决定上限的是供数能力
很多人判断 GPU 性能,只看宣传里的 TFLOPS(每秒浮点运算次数),但在真实工程里,算力再高,如果数据供不上,都是空谈。真正决定性能上限的,是内存墙—— 数据能不能及时送到计算单元手里。
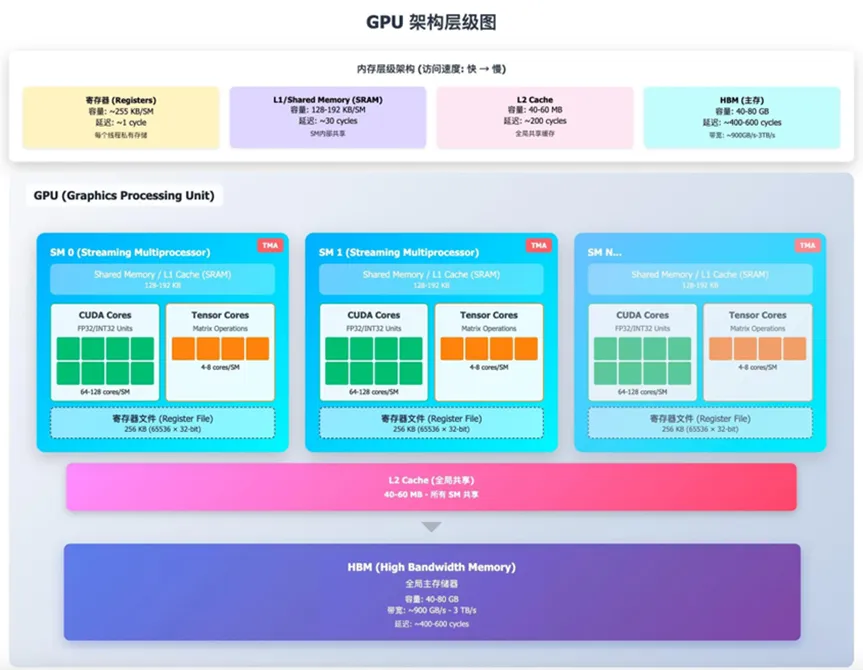
GPU 内存遵循一个朴素规律:离执行单元越近,速度越快、容量越小;离得越远,速度越慢、容量越大。从快到慢,一共四级存储:
寄存器:线程私有,速度最快(约 1 周期),但容量最小,是计算单元的 “手心”。
共享内存 / L1:同一个 Block 内线程共享,片上 SRAM,延迟数十周期,用于高频数据复用。
L2 Cache:全 GPU 所有 SM 共享,是全局缓冲,比 L1 慢,但比显存快很多。
HBM / GDDR:设备全局内存,容量最大,延迟最高(数百周期),是数据仓库。
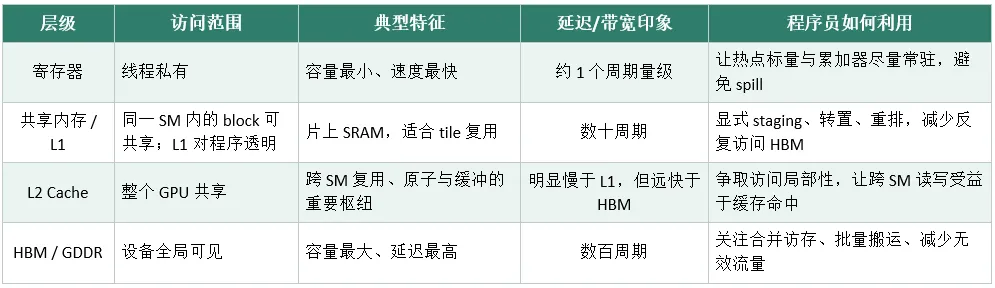
高性能内核的本质,就是把热点数据尽可能放在更靠近计算单元的地方,减少对慢速显存的访问。
这就是为什么有些显卡理论算力很高,但实际跑模型很慢 —— 因为数据搬运跟不上,计算单元一直在空等。
05 SM 内部:
CUDA Core 与 Tensor Core 协同工作
SM 是 GPU 的 “计算核心集群”,可以理解为一个小而完整的并行处理器。一个现代 GPU 包含几十个 SM,它们共同完成所有计算任务。
一个 SM 内部大致分为三部分:
前端:取指、warp 调度、依赖跟踪
中间层:寄存器文件、共享内存 / L1、数据通路
后端:执行单元,包括 CUDA Core、Tensor Core、LD/ST 单元等
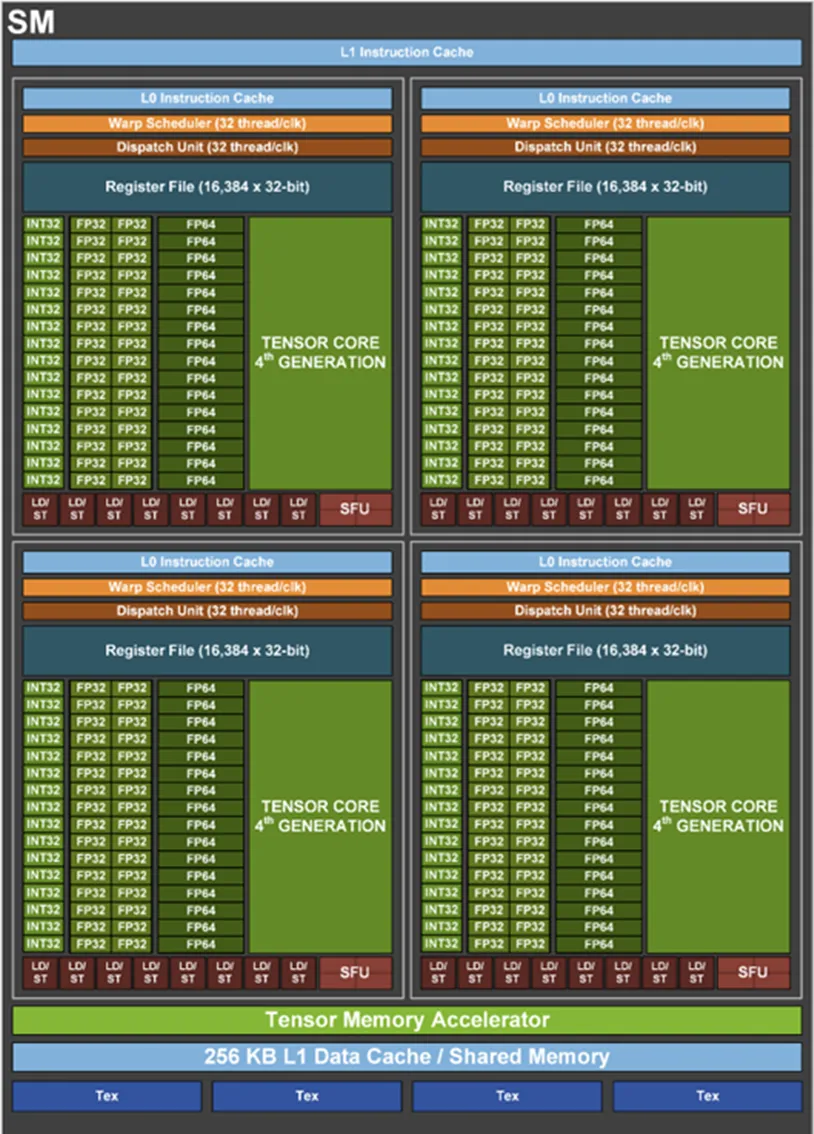
在执行单元里,有两个最关键的角色:CUDA Core 和 Tensor Core,它们不是竞争关系,而是黄金搭档。
CUDA Core:负责通用计算,包括整数运算、标量浮点、地址计算、循环控制、以及主计算完成后的收尾操作(epilogue),比如激活、偏置、格式转换、写回等。
Tensor Core:专门为矩阵乘加(MMA)设计的专用单元,是 AI 计算的真正引擎,通常以 Warp 为单位被驱动。
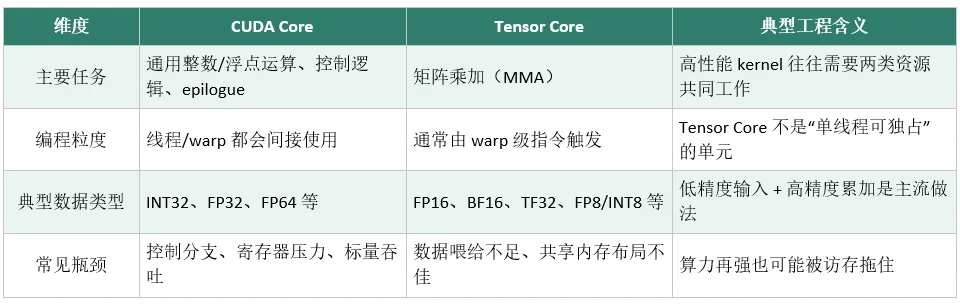
简单分工:Tensor Core 负责核心矩阵计算,CUDA Core 负责数据搬运、格式整理、控制与写回。只有两者高效配合,才能跑出峰值性能。
很多人误以为 “Tensor Core 越多越快”,实际上如果数据组织不好、共享内存布局不合理,Tensor Core 会长期处于饥饿状态,根本跑不起来。
06 以 GEMM 为主线:
看懂 GPU 计算如何层层落地
在 AI 里,GEMM(通用矩阵乘) 是一切的核心。线性层、卷积变换、注意力机制,最后几乎都会变成 GEMM 计算。可以说:看懂 GEMM,就看懂了 GPU 高性能计算的一半。
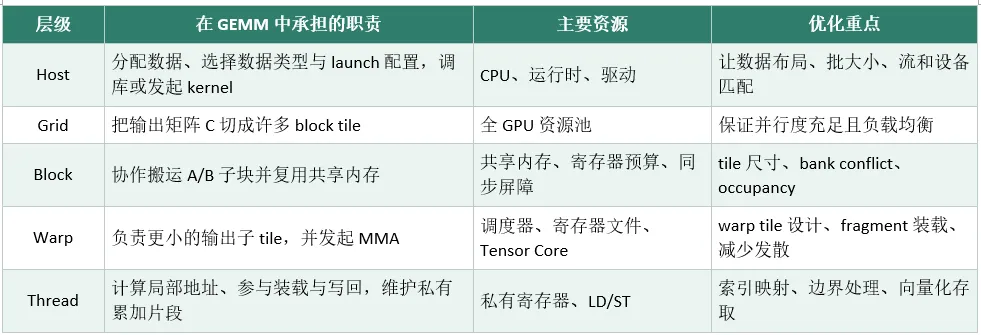
GEMM 的优化不是某一个技巧,而是四层配合、层层落地:
Grid 层:把输出矩阵 C 切分成多个大的 Block Tile(比如 128×128),每个 Block 负责一块输出。
Block 层:把 A 和 B 的对应子块读到共享内存,做片上数据复用,减少显存访问。
Warp 层:把 Block Tile 再拆成更小的 Warp Tile,由 Tensor Core 执行矩阵乘加(MMA)。
Thread 层:每个线程负责搬运数据、计算地址、维护寄存器里的局部累加片段。
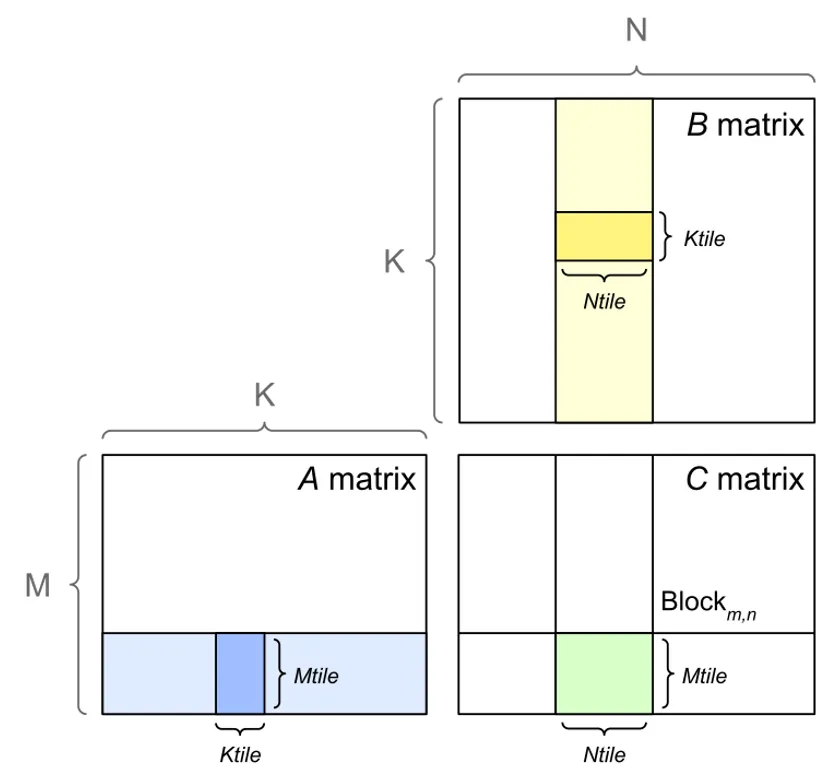
GEMM 经典数据流:
全局内存 → 共享内存 → 寄存器 Fragment → Tensor Core 计算 → 寄存器累加 → 写回全局内存
几个决定性能的关键细节:
累加器必须放在寄存器里:避免中间结果反复写回内存,让计算紧贴执行单元。
共享内存要避免 Bank Conflict:多个线程同时访问同一个存储体,会导致串行化,速度暴跌。
全局访存必须合并:让连续线程访问连续地址,最大化显存带宽利用率。
Tile 尺寸要合理:太小复用率低,太大占满资源,导致并行度上不去。

只要把这一套流程理解清楚,你再看任何高性能算子库(如 CUTLASS、cuBLAS),都能一眼看懂它的设计思路。
07 硬件横评:
从 V100 到 B300,怎么选才对
市面上 GPU 型号繁多,从消费级到数据中心级,差异极大。选卡不能只看显存大小,而要根据场景匹配:
大模型训练:优先看 HBM 容量、显存带宽、Tensor 吞吐、NVLink 多卡互连能力
推理服务:优先看延迟、显存占用、功耗、成本、稳定性
个人研发 / 工作站:优先看性价比、部署难度、通用性
下面是从经典 V100 到最新 Blackwell 架构 B300 的完整横向对比:
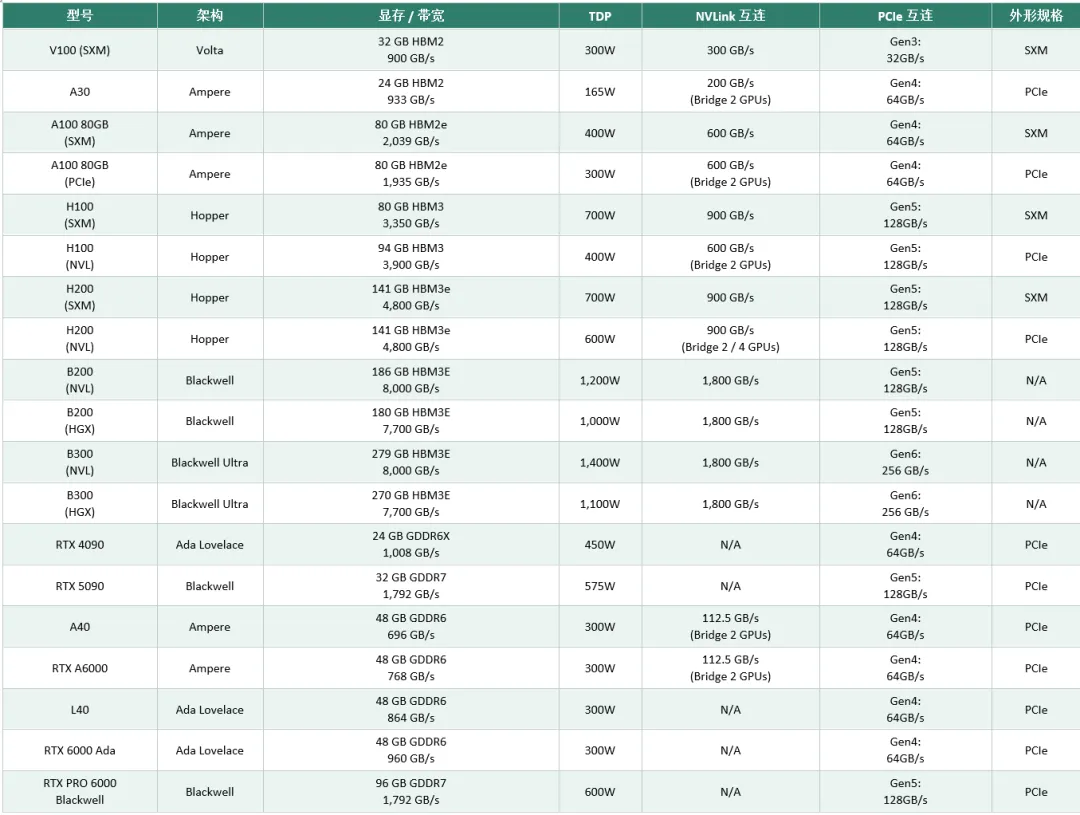
计算能力对比(单位:TFLOPS / TOPS,D = 稠密,S = 稀疏):
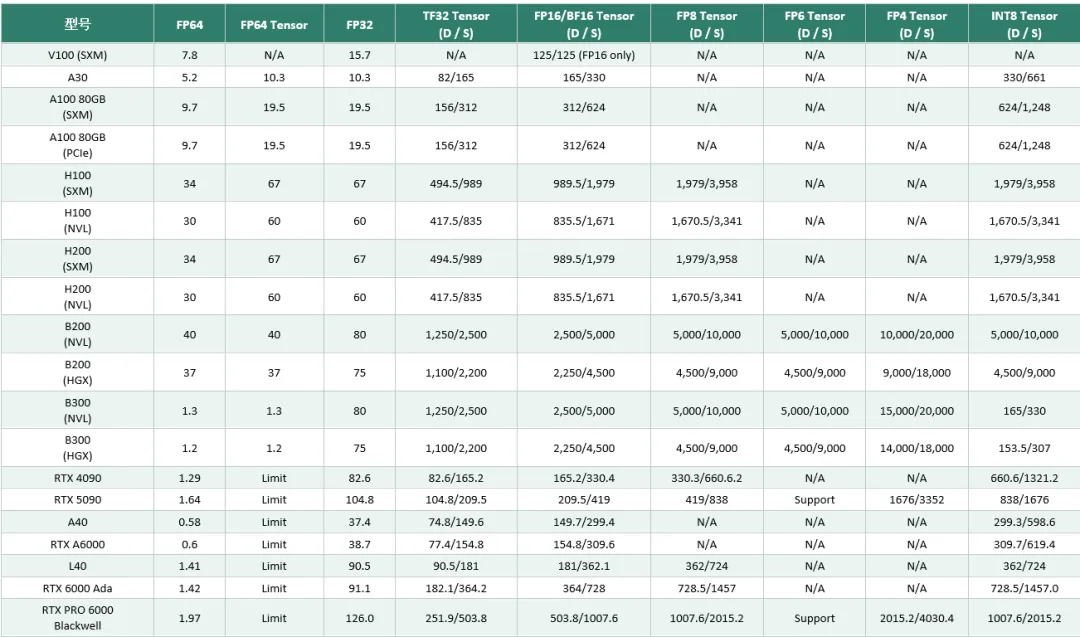
核心结论:
数据中心卡:HBM 高带宽、NVLink 强互连、低精度算力极高,适合大规模训练与推理。
消费 / 工作站卡:GDDR、无 NVLink、性价比高,适合个人研发、验证、中小规模推理。
大模型训练:多卡互连效率 > 单卡 FP32 峰值。
08 监控真相:
GPU-Util=100%≠算力满载
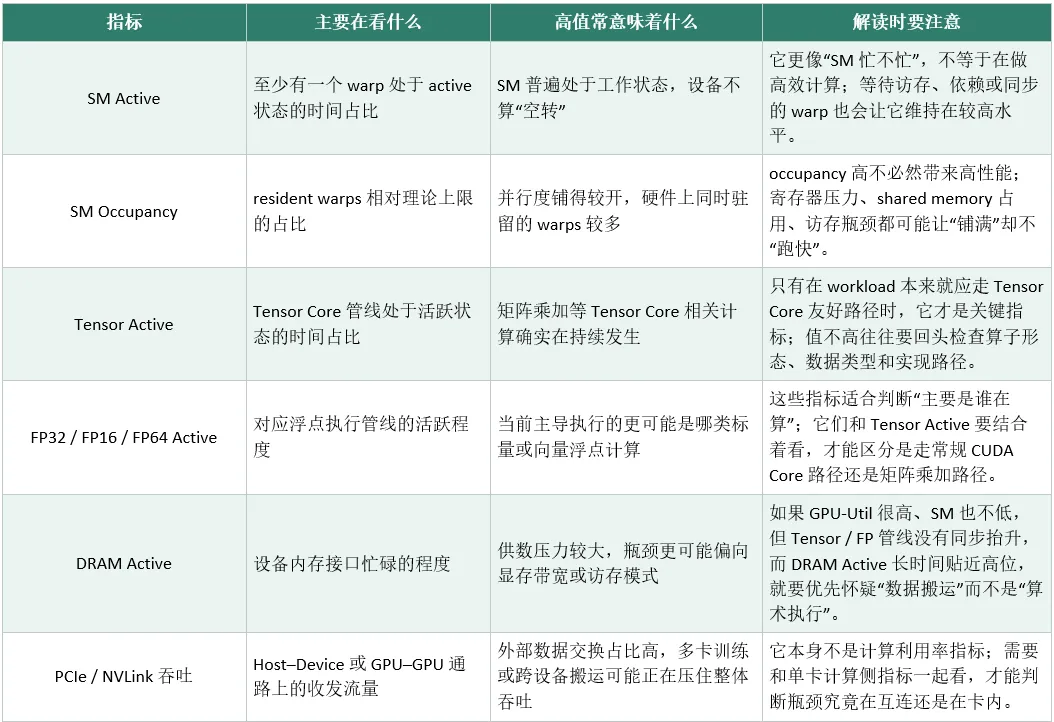
日常排查性能,大家最常用的工具是 nvidia-smi,它可以快速看到 GPU 型号、驱动、显存占用、功耗、温度、进程信息,以及一个关键指标:GPU-Util(GPU 利用率)。
但这里有一个最容易被误解的真相:
GPU-Util = 100% 并不代表算力满载!
GPU-Util 的真实含义是:在采样窗口内,GPU 上有 Kernel 在运行的时间比例。它只表示 “显卡没闲着”,但不代表 Tensor Core、CUDA Core、显存带宽都在高效工作。
显卡可能一直在跑 Kernel,但大部分时间都在等数据、等同步、等依赖、空转,表面利用率 100%,实际有效算力可能只有 20%。
在生产环境里,必须用 DCGM(Data Center GPU Manager) 做细粒度拆解,才能真正定位瓶颈。
由此可得出简单判断流程:先用 nvidia-smi 看全局状态,再用 DCGM 看 SM、Tensor、DRAM、互连利用率,才能知道卡是 “真的在算”,还是 “假装在忙”。
09 NVIDIA 真正护城河:
从卖 GPU 到交付 AI 工厂
今天的算力竞争,早已不是 “谁的单卡 TFLOPS 更高”,而是谁能提供一整套可规模化、可运维、高产出的 AI 工厂。
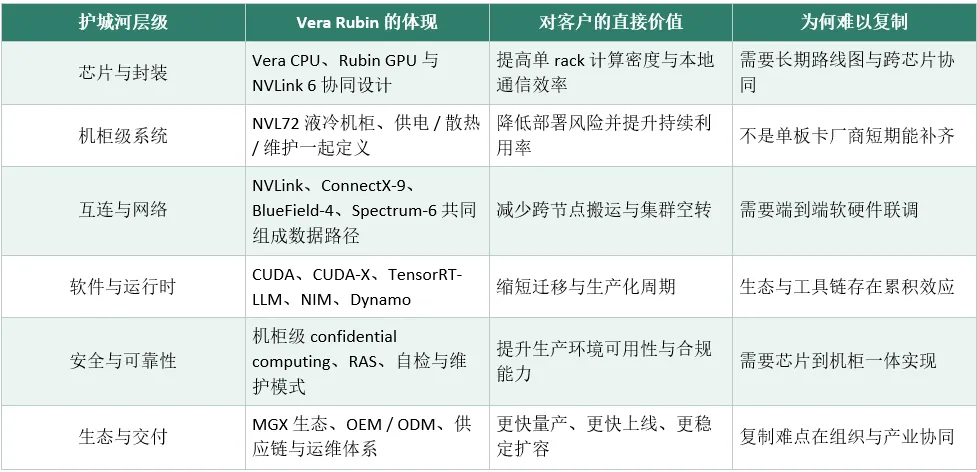
NVIDIA 的 Vera Rubin 平台,就是这种思路的集大成者:它不再把 GPU 当一张独立加速卡,而是把 Vera CPU + Rubin GPU + NVLink 6 + SuperNIC + DPU + 高速交换机 + 整机柜 打包成一个协同工作的一体化系统。
用户买到的不是一堆卡,而是一个机柜级别的 AI 计算单元,从芯片、互连、散热、供电到软件栈全部预协同设计。


它的护城河可以分为五层:
芯片协同:CPU、GPU、NVLink 统一设计,数据路径极致优化。
机柜级系统:液冷、供电、散热、维护一体化,降低部署风险。
互连网络:NVLink、SuperNIC、DPU、交换机端到端打通,减少通信开销。
软件栈:CUDA、CUDA-X、TensorRT-LLM、NIM 全栈覆盖,降低开发与部署成本。
生态与交付:量产能力、供应链、OEM/ODM 生态,是别人难以复制的壁垒。
未来看全栈,不看单点峰值
从 CUDA 线程层级,到 SM 与 Tensor Core 协作,再到内存数据流、GEMM 优化,最后到机柜级 AI 工厂,现代 GPU 计算早已不是单一指标可以定义。
未来评估一个算力平台,不要再只问 “峰值多少”,而要问这五件事:
机柜级一致性与稳定性如何
Scale-up / Scale-out 互连是否连贯高效
软件栈是否完整、好用、可持续迭代
生产级可靠性、运维成本是否达标
生态交付、量产能力是否成熟
只有硬件、软件、系统、生态形成完整闭环,单点的算力优势,才能真正变成长期的平台优势。
