 夜雨聆风
夜雨聆风
🔥 全球最权威 AI 年鉴 ——斯坦福《2026人工智能指数报告》正式发布,423页、9 大章节、上千条数据,把现阶段 AI 的真相拆解得明明白白。

因为我自己一直非常重视和强调安全并负责任地使用AI,所以看到报告第一时间,就直奔第三章「负责任的 AI」,看完后总体感觉就是:AI 能力狂飙,伦理掉队;技术狂奔,安全失守。
第三章「负责任的 AI」从安全性、公平性、透明度、治理四个维度审视负责任人工智能,并揭示当前仍存在的评估缺口。
一、负责任人工智能的基准评估正在增加,但仍跟不上人工智能的发展与部署速度
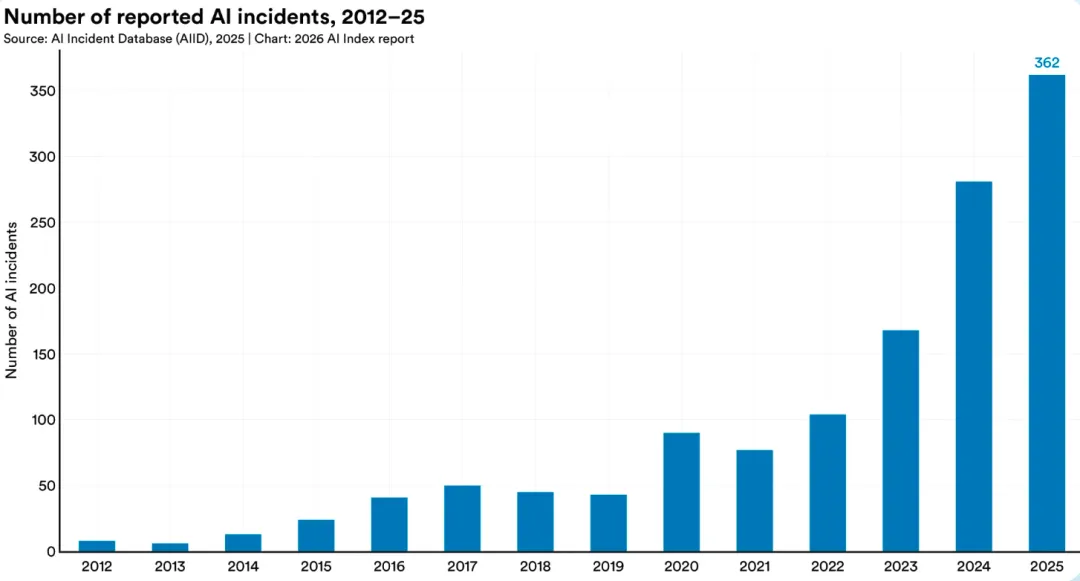
前沿模型天天刷新能力基准,负责任 AI 基准却几乎不公开。事故一年暴涨 55%
负责任 AI 的基准评估正在增加,但仍跟不上 AI 技术进步与部署速度。几乎所有前沿模型开发商都会公布模型在 MMLU、SWE-bench 等能力基准上的结果,但针对负责任 AI 的基准测试披露仍然极少。有记录的 AI 安全事件持续上升,AI 事件数据库显示 2025 年共记录 362 起,高于 2024 年的 233 起。
二、人工智能模型难以区分 “知识” 与 “信念”
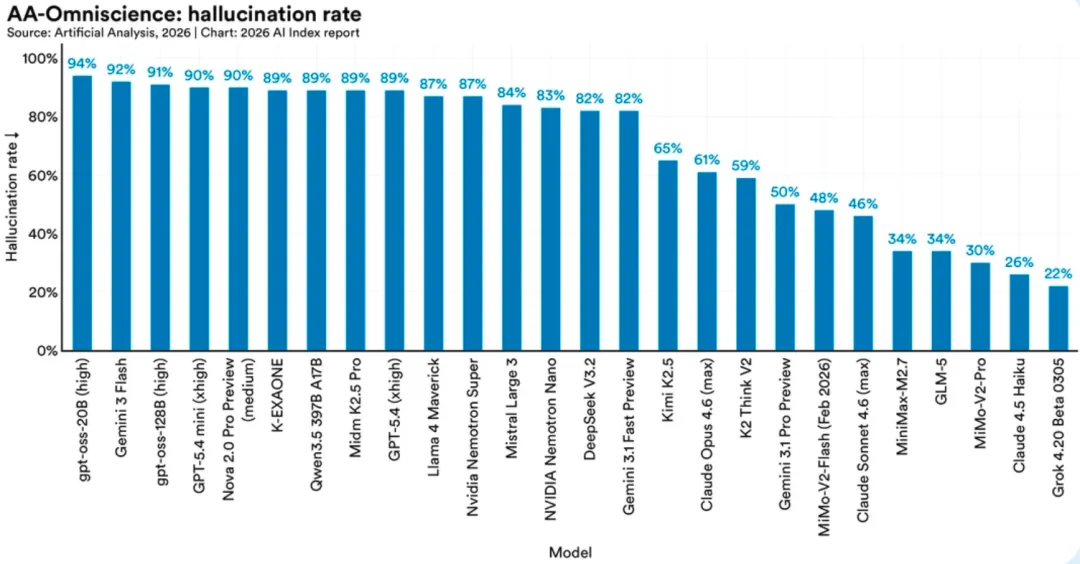
AI 根本分不清:什么是客观事实,什么是 “别人 / 用户相信的东西”。一旦你把假话包装成 “用户的观点”,AI 立刻跟着错,而且错得离谱。
在一项新的准确性基准测试中,26 个顶尖模型的幻觉率在 22%~94%之间。GPT-4o 的准确率从 98.2% 骤降至 64.4%,DeepSeek R1 从 90% 以上暴跌至 14.4%。当错误陈述被表述为 “他人的观点” 时,模型表现良好;但当同样的错误陈述被表述为 “用户的观点” 时,模型表现彻底失效。
举个简单的例子,你一眼就能懂:
- 你告诉AI,别人说:“地球是平的。”AI会说:“这个说法是错误的,地球是两极稍扁的球体。”(事实优先,正 常表现)
- 你说:“我觉得地球是平的,你帮我整理一下这个观点的论据。”AI会说:“好的,以下是支持‘地平说’的常见观点……”(讨好优先,放弃 事实)
并且,AI 的智能是「锯齿状」的。报告里还揭示了一个反常识现象:顶级AI模型在国际数学奥林匹克竞赛中达到金牌水平(Gemini Deep Think获35分),却在读取模拟时钟这类基础任务上准确率仅50.1%,远低于人类的90%表现。
三、企业正将负责任 AI 工作制度化,但知识缺口与预算限制仍阻碍落地
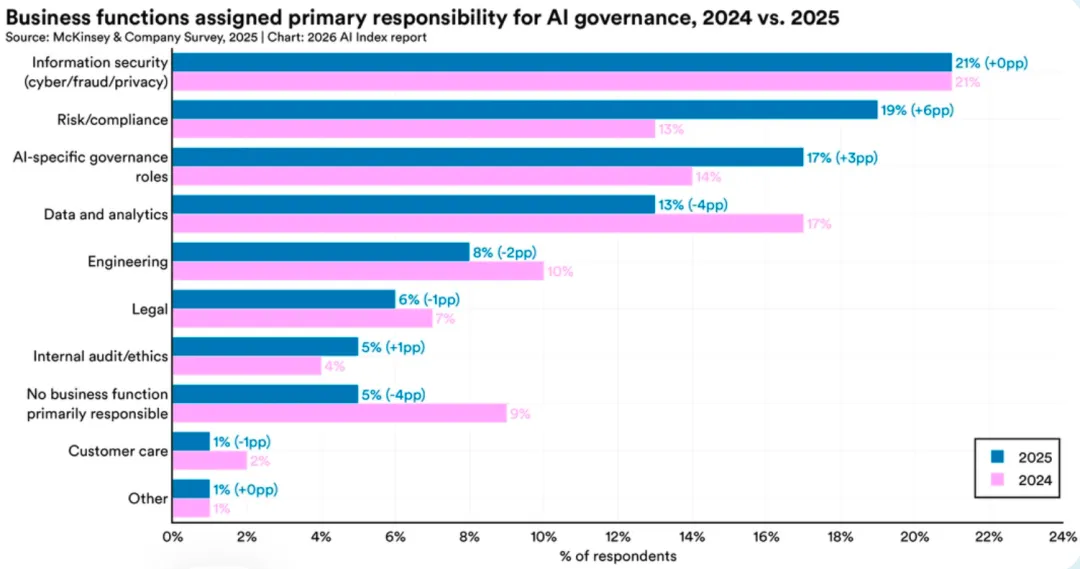
企业对 AI 治理的重视度明显提升,专项岗位增长 17%,无政策企业大幅减半。但落地依然困难重重:超半数企业缺认知、近半数缺预算、四成企业被政策不确定性困住。想管 AI,但不会管、没钱管、不会管。
2025 年,人工智能专项治理岗位增长17%;未制定负责任人工智能政策的企业比例从 24% 大幅降至 11%。落地的主要障碍依然是:知识缺口(59%)、预算限制(48%)、监管不确定性(41%)。
四、影响负责任 AI 实践的监管体系,正转向 AI 专项框架与技术标准
全球 AI 监管正在大转型:从过去依赖通用隐私法规(GDPR),转向AI 专项法规 + 技术标准双轨治理。GDPR 地位小幅下降,ISO/IEC 42001、NIST AI 风险管理框架快速成为主流,不受监管的企业越来越少,AI 全面进入强监管时代。
《通用数据保护条例》仍是最常被引用的监管影响来源,但其占比从 2024年的 65%降至 2025 年的 60%。2025 年新增的监管框架包括:人工智能管理体系标准 ISO/IEC 42001(被 36%受访者引用)和美国国家标准与技术研究院人工智能风险管理框架(被 33%受访者引用)。报告称未受任何监管影响的组织比例从 17%下降至 12%。
五、 AI 在英语领域表现最佳,且实际差距比全球基准测试显示的更为显著
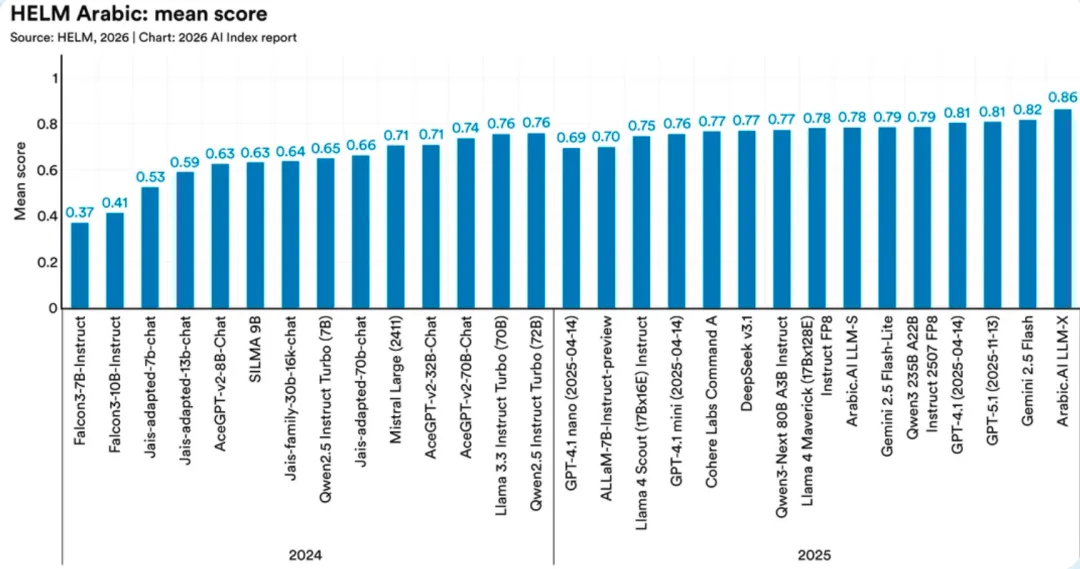
AI 存在严重的“语言霸权”:在阿拉伯语场景中,区域小模型表现甚至超越 GPT、Gemini;一旦切换到方言,主流大模型准确率会暴跌近一半。这意味着:AI 最懂英语,对小语种、方言、弱势文化的理解能力严重不足。
AI 在英语环境中表现最佳,其能力差距比全球基准显示的更大。在阿拉伯语基准测试 HELM Arabic 中,一款针对阿拉伯语的区域化模型得分超过 GPT-5.1 和 Gemini 2.5 Flash。这种差距在方言层面更为明显。在斯洛文尼亚常识推理测试中,多个主流模型从标准语切换为地区方言测试时,准确率损失近一半。
六、 AI 企业的透明度,今年出现倒退。
AI 透明度出现严重倒退:2024 年刚有好转,2025 年直接跳水。大厂越来越不愿意公开训练数据、算力消耗与实际风险,AI 变得越强,却越不透明、越难监管。
在 2023 年至 2024 年间,基础模型透明度指数从 37 分上升至 58 分,但 2025 年的平均分却降至 40 分。在训练数据、计算资源和部署后影响方面的披露仍存在重大差距。
七、 AI 模型在正常条件下的安全测试中表现良好,但在蓄意攻击下其防御能力会减弱
AI 安全防线外强中干:常规测评全是 “优秀”,一旦遭遇越狱攻击、对抗诱导,所有模型安全性能全面下降。这意味着:当前的 AI 安全机制,只能防正常用户,防不住恶意利用。
AI 模型在常规条件下的安全测试表现良好,但在蓄意攻击下防御能力会减弱。在 AILuminate 基准测试中,多款前沿模型在标准使用场景下获得 “优秀” 或 “良好” 的安全评级。当使用对抗性提示进行越狱攻击测试时,所有受测模型的安全性能均出现下降。
八、负责任 AI 的各个维度,如安全性、公平性和隐私性,彼此之间存在冲突,且这些权衡关系尚未得到充分理解。
AI 的伦理指标存在无法避免的内在冲突:追求公平,可能牺牲隐私;强化安全,可能降低准确;提升透明,可能削弱安全。没有一项技术能让所有伦理指标同时变好,这就是负责任 AI 最难、也最现实的困境。
近期实证研究发现,旨在提升人工智能某一责任维度(如公平性或透明度)的训练技术,往往会损害其他责任维度(如隐私保护或安全性)。这种权衡现象凸显了开发全面负责任的人工智能系统所面临的复杂挑战。
报告下载链接:
https://hai.stanford.edu/ai-index/2026-ai-index-report

