 夜雨聆风
夜雨聆风Build Seele AI with AI.
上一篇文章,跟大家分享了个人在AI办公场景中可以提效的一些技巧。顺着这个问题往前思考:当 Agent 真正进入组织,它会先撞上哪些问题?又该怎么把它从“一个好用的工具”,变成“一个能跑起来的系统”?今天这篇,就想讲清楚这件事。
个人使用和组织使用,看上去都在“用 Agent”,但其实又不太一样。一个人用 Agent,最先关心的是它能不能替自己把事做掉;一家公司开始用 Agent,问题就会变成:多人一起用会不会乱,任务在不同人之间流转会不会断,出了问题之后能不能追,跑上一段时间后系统会不会越来越重。
我们选 OpenClaw,是因为相比从零自研或在 IDE Agent 上改造,它更适合做组织级 Agent 的底座,它不是只服务 coding 的工具,而是一个面向多通道、多任务、多角色的通用 Agent运行时 ,既有适合组织治理的系统层能力,又开源可改,skill 体系也标准化,适合长期扩展。
很多 Agent 的默认前提,和组织环境本来就不匹配
今天大多数 Agent,其实还是顺着个人使用逻辑长出来的。
一个人提需求,一个会话接住上下文,一组工具往下执行,一段历史保留记忆。这套结构放在个人场景里没有问题,甚至相当高效。
但组织不是个人的放大版。组织里同时存在多人并发、权限差异、任务流转、审批要求、信息分层和结果复盘。一个原本适合个人效率的系统,被直接搬进来之后,当然还能跑一部分事情,但它很难天然适应组织运行的复杂度。
更具体一点说,很多 runtime 很会处理“眼前这段会话”,却不天然擅长处理“这段会话背后的人和关系”。它知道现在在聊什么,却不一定知道这是谁发起的任务,谁有权批准,谁应该收到结果,谁的偏好应该被继续沿用。个人使用时,这种缺口不一定马上暴露;一到组织环境里,它很快就会变成结构性问题。
第一个真正会出问题的地方,是归属关系
很多系统记内容不差,记归属却未必稳定。
它可能知道你刚刚说了什么,却没有把同样多的精力放在另一件事上:这段话到底是谁说的,这个任务该算在谁头上,这个 preference 应该跟着谁走,这段项目历史应该连到哪条线上。
在个人场景里,这类偏差往往只是一次答偏;在组织里,这种偏差会一点点累积,最后伤到的是信任本身。
因为对组织来说,最麻烦的从来不是系统少记了一点,而是它把东西记到了错误的人、错误的任务、错误的上下文下面。
所以到最后,落地 Agent 往往一定会碰到“身份显式化”这件事。系统不能只是知道内容,还得知道内容属于谁;不能只是保留对话,还得把对话挂到对应的人、对应的任务、对应的项目脉络里。
这听上去像实现层细节,但它决定的其实是另一件大事:你得到的到底是一套组织记忆,还是一堆散落在会话里的碎片。
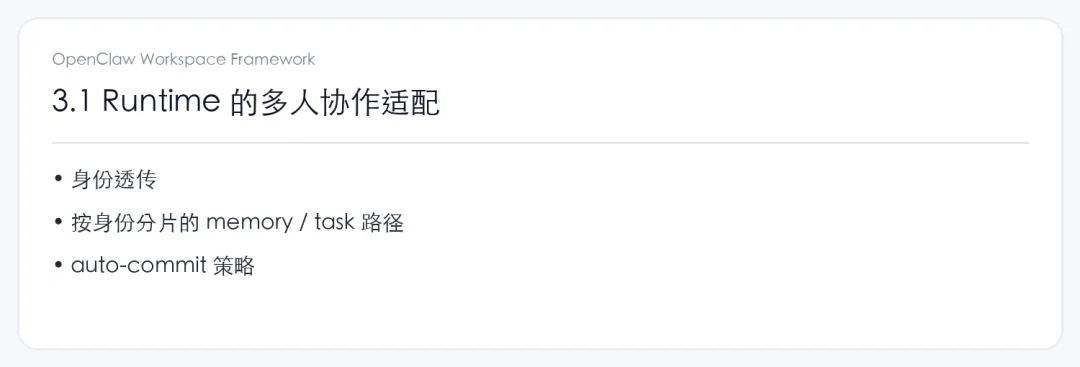
第二个问题,是组织并发会把潜在缺陷一下子放大
一个人用 Agent,大部分时候不太会感受到并发压力,因为目标通常只有一个:把眼前这件事推完。
但组织环境不一样。广告团队在看数据,研发在排查问题,运营在写内容,管理层在盯关键项目。任务同时发生,节奏彼此不同,优先级还在不断变化。
这时候,如果底层仍然默认只有一条主线、一套共享上下文,问题很快就会冒出来:任务相互挤占,上下文彼此污染,结果虽然出来了,却挂错地方、回错对象,甚至还带着上一条任务留下的残留信息。
说到底,这不是“模型突然不行了”,而是 session 设计还没准备好进入组织。个人场景里,一个主会话很多时候够用;组织场景里,lane、thread、isolated session 这类并发隔离迟早都得补上。cron 会不会占住主线,子任务会不会回灌污染,多人请求能不能分流,本质上都是这一个问题。
真正让团队疲惫的,往往也不是 Agent 完全不可用,而是它在忙起来之后开始变得不稳定。对组织来说,不稳定比不可用更麻烦,因为它会反复消耗信任。
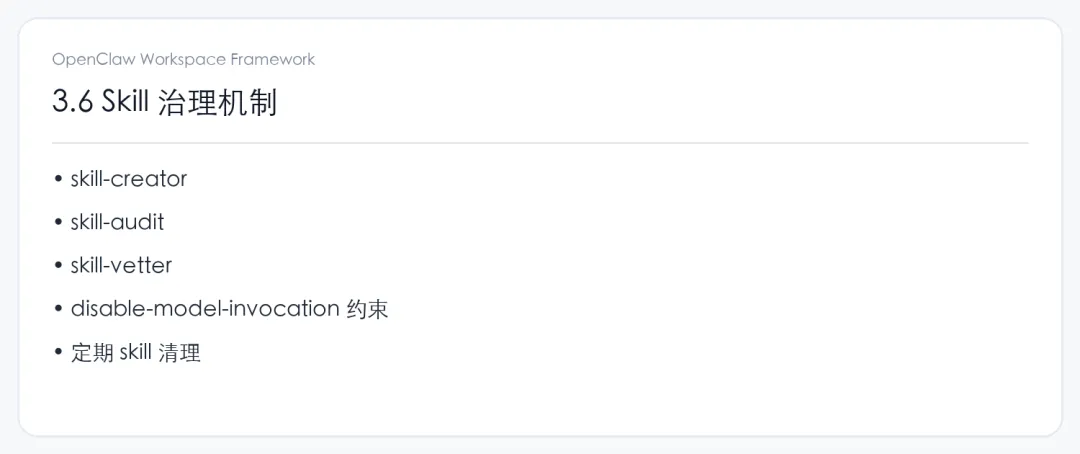
第三个问题,是能力长得很快,治理却未必跟得上
Agent 这套东西很容易进入一种“越接越多”的状态。
接更多工具,补更多 skill,开更多入口,短期内看上去能力当然是在上涨的。但跑一段时间之后,组织会逐渐意识到,真正拉开差距的从来不是“接了多少”,而是“这些能力是不是还能长期保持清楚”。
哪些能力可以自动激活,哪些动作必须手动触发,哪些高风险操作要进审批,哪些 description 已经互相重叠,哪些 skill 实际上没人再用却还在持续污染上下文——这些事如果没人处理,系统就会越来越像一个典型的企业现场:东西越来越多,边界越来越糊,人人都知道有用,但没人说得清到底该怎么维护。
所以问题不在于有没有 tool,也不在于 skill 多不多,而在于组织有没有能力治理这些能力本身。
第四个问题,是记录很多,但真正留下来的判断很少
很多团队会天然以为,只要聊天记录足够多、执行日志足够全,组织记忆就已经开始形成了。
但这两者之间,其实差得很远。
组织真正需要留下来的,不只是“发生过什么”,而是为什么这么做、哪些判断后来被验证了、哪些坑以后应该绕开、哪些经验值得复用、下一次遇到类似情况应该直接调用哪种方法。
所以最后一定会走到 memory 结构的问题:什么该放进 daily,什么该挂进 tasks,什么要沉到长期知识库,什么只该留在短期上下文里,什么必须版本化,什么必须能被检索和追溯。
如果这些东西没有被整理出来,系统表面上每天都在写东西,实际上只是把信息不停往后堆。事情做了不少,但组织真正能复用的判断,并没有跟着积累下来。

所以企业真正要建设的,不是“会用 Agent”,而是“能承接 Agent”
这也是我现在越来越明确的一个看法。
企业落地 Agent,到后面真正要建设的,并不是一套“大家都会用”的使用习惯,而是一套“组织能够长期承接它”的执行结构。
过去,公司通过后台、表单、SOP、审批链路、会议纪要来组织执行。接下来,自然语言会越来越多地成为新的执行入口。但这不意味着底层结构可以模糊掉。恰恰相反,因为入口变简单了,底层反而要更清楚。
谁可以发起,谁可以批准,什么算完成,什么动作算高风险,哪些经验应该沉淀,哪些知识应该长期保留——这些问题,过去靠人和人之间的默契也能先凑合着往前走;一旦交给 Agent,就不能再靠默契了。
你得把组织真正的工作结构,明确到机器可以接手,明确到换一个人也能继续,明确到系统出问题之后还能被追踪和修正。
最后
AI 已经能做很多事,这一点大家都看到了。下一步要重视的是——组织有没有开始形成一种新的基本功:把原来依赖个人经验、个人默契、个人盯着才能推进的事情,整理成一套可以被 Agent 接住的结构。
当下Agent 带来的差异,不仅是某个环节快了一点,而是整个组织能不能更稳地往前跑。 如果这层能力长不出来,Agent 很容易只是增加新的工具和新的忙碌;但如果这层能力开始成型,它改变的就不只是效率,而是组织本身的运行方式。
如果你也在 AI 办公,来进群聊聊你的观察和判断
下期想听哪些角度的分享,欢迎评论区留言

