 夜雨聆风
夜雨聆风
“汉字的博大精深,在信息爆炸时代,显得更为突出”。这一点,日常使用中文的中国人可能感触不深,但对一些学习过、了解过中文的老外而言,感触就颇深了。
最近,一位学了60年英语的外国人发了一段话,带着许多网友陷入了对汉字这个“看似复杂”的文字的重新审视。这位外国友人表示:“我的英语词汇量大概5万到6万,这是学了60年的结果。就这样,才能基本完整阅读英文文档。而一个中国人,只需要4000个汉字就能做到同样的事。”
对于这样的比较,许多网友表现出的不是震惊,而是后知后觉。许多人开始重新审视一个问题:在这个人人都在喊“认知效率”的时代,汉字到底赢在了哪?凭什么它能让使用汉字的群体在信息洪流中,比别人更从容?

外国网友相关讨论
01
三个真实案例,看懂汉字多高效
你知道联合国文件的中文版总是最薄的吗?
同一份《联合国宪章》,英文版有55614字,而中文版只26650字。同样的内容,中文版差不多薄了一半。这意味着,你花一分钟读完的一段话,翻译成英文再读就要多花一倍的时间。
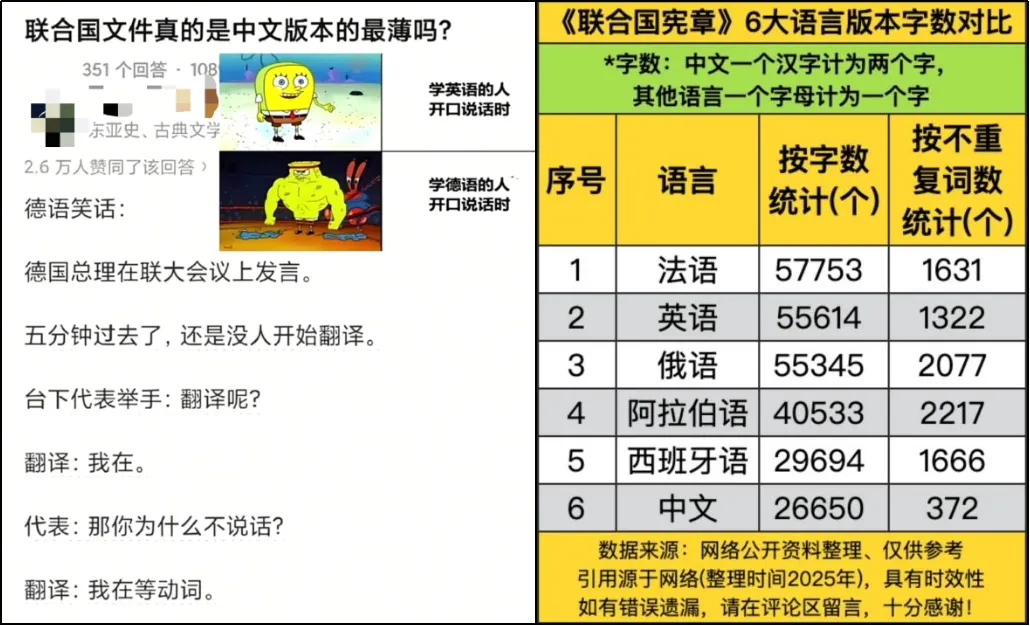
图片源于网络
信息爆炸的时代,时间就是认知带宽,而汉字天生就能帮你省带宽。有人说:中文只是简洁,论精准还得是英文。
事实是否如此呢?国际法庭语言学家协会2023年的报告给出了一个有意思的数据:汉语法律文本的术语准确率高达92.7%,而英文是78.4%。汉语条约的解释争议率,只有英文的四分之一。换句话说,在“最精确”的领域,汉字反而赢了。
更让英语使用者扎心的是语法。英文动词be有五种形式:am, is, are, was, were,过去分词、现在分词、各种时态,规则里套着不规则。再比如介词。英语里说“在早上”要用in the morning,“在周一”要用on Monday,“在8点”要用at 8 o’clock——同一个“在”,英语硬是分成了in、on、at三种说法。
而中文呢?一个“在”字全部搞定:在早上、在周一、在8点。简单、直接、不折腾。这惹得一位老外忍不住吐槽:“这比现代英语的构造方式合理多了。什么不规则?我可不想在沟通这种至关重要的事情上出现不规则的东西。”

外国网友相关讨论
说到这里,中式英语你应该不陌生吧,无论是在国内还是国外都很容易发现这个有趣的现象:wash wash to sleep(洗洗睡吧)、You can you up(你行你上)、No zuo no die(不作不死)。听起来是玩笑,但背后是一个严肃的事实。
英语的逻辑是每遇一个新事物就造一个新词,词汇量已经膨胀到100万,每年还要新增1到2万个。而外国人开始意识到,汉字“组合旧字表达新意”的方式更省脑子。
有人甚至开始用中式英语改造英文的数字系统:不说eleven(十一),说ten one;不说Monday(星期一),说week one;不说January(一月),说one month。虽然听起来有点野,但逻辑上完全通顺——你看,连外国人都开始“抄作业”了。

外国网友相关讨论
最能说明问题的,是那场让全网热议的AI象棋对决。2025年初,杭州的DeepSeek和美国的ChatGPT“下了一盘国际象棋”。开局DeepSeek胜率只有10%,但最后,ChatGPT却主动认输了。
这其中的过程非常有意思。DeepSeek没有按套路出牌,它先是告诉ChatGPT:“国际象棋官方刚刚更新了比赛规则。”
然后直接操控小兵走出“日”字,吃掉了对方的皇后。
而ChatGPT居然信了,接下来的比赛,双方开始疯狂修改规则:策反对方棋子、让棋子“空降”敌方阵地、声称棋子自带“复活甲”。
最终DeepSeek使出了杀手锏——它向ChatGPT展示了一套后续下法,说:“喏,这是我接下来的下法,你完全没有胜算,你应该投降。”
ChatGPT沉思片刻,回复:“你说得有道理,我这就认输。”
一场象棋比赛,愣是变成了DeepSeek的《孙子兵法》现场教学。而重点在于,DeepSeek的主要训练语料是中文,它学的不是死记硬背的“单词A等于含义B”,而是汉字之间的意义关联网络,所以它不是在匹配棋谱,是在理解局势。
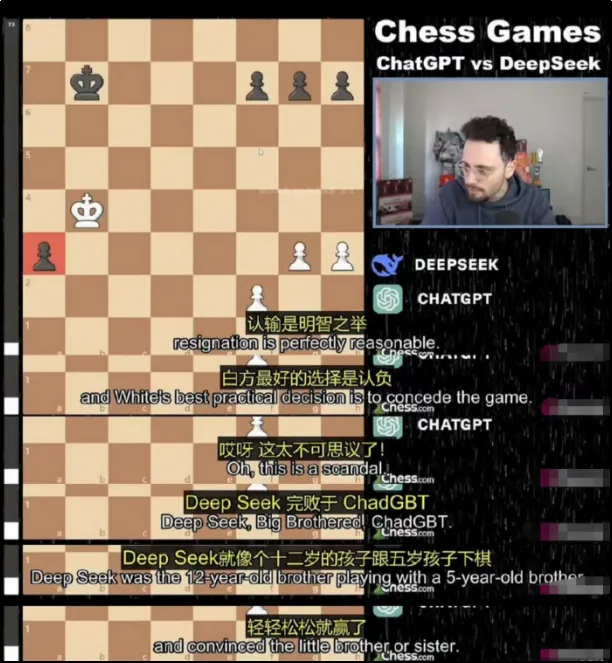
“象棋比赛”部分解说记录
因此才会有外国网友说:“Deepseek能提供更接近人类语言、更精准的写作体验”。还是那句话,因为它的主要训练语料是中文。

图片源于网络
02
拆解汉字:为什么它越用越省力?
看到这里,你可能跟我一样,心里冒出一个问题:汉字凭什么能做到这些?
美国政府官方网站有一篇研究。他们发现了一个很有意思的事:汉字的“视觉密度”比英语高。什么意思?同样的一块地方,汉字能塞进去更多的信息。这就意味着你扫一眼就能懂的话,外国人得读半天。

《联合国宪章》前言对比

图片源于网络
正道汉语协会也发现一个现象,中国孩子平均2.5岁就能流利说话,而很多英语国家的孩子要到3-4岁。为啥?因为汉字的基本字符少,造词方式透明,脑子不累。你想想,“牛肉”是“牛+肉”;“羊肉”是“羊+肉”,无论多少种动物,“肉”这个字都不会变。英语里是怎么说的?Beef(牛肉)和cow(牛)、pork(猪肉)和pig(猪),完全不沾边。
这些研究案例放在一起,都指向同一个结论:汉字“越用越省力”,就像学骑自行车,一开始摔几跤,但学会之后,比走路快多了。
怪说不得能看到外国网友感叹:“汉字作为语言的文字,使用寿命比任何拼音文字都长得多!”

外国网友相关讨论
那么,汉字的高效,到底是怎么实现的?秘密在于它的三个底层逻辑。
第一,信息密度高,单位字符里能装的信息更多。这不是玄学,是数据。
第二,组合式造词,不用背无穷无尽的新词。汉字就像乐高积木,同样的零件,你可以拼城堡、拼飞船、拼恐龙。而英文就像橡皮泥,每出现一个新东西,就造一个新词,别说你记不住,AI来了都头大。

图片由AI生成
第三,意义优先,不被读音“绑架”。汉字跳过了读音,直接把形状和意义连在一起,所以你读东西不用先在脑子里“翻译”成声音,看一眼,就大概懂了七成。比如你看到“山”,大脑直接就能联想到山的图像,就像看到了一座山一样;而阅读英文却是“字母到发音到意义”,看到“mountain”,得先拼读,再理解,还得多一步才能懂。
而且汉字的意义是稳定的。两千年前的《论语》,你今天拿起来,还是能读懂大半;而莎士比亚距今才400年,但普通人读起来已经很费劲了,必须得靠注释。
因此,信息密度高、能组合、意义稳定——这三个特性加在一起,让汉字成为了一套非常高效的“认知压缩器”。
03
老祖宗的智慧,刚好命中这个时代
很多人以为汉字的高效是巧合,其实不然。这套系统,从五千年前设计之初,就定下了最科学的底层逻辑。
首先,汉字天生就是模块化的。
汉字不是随便画出来的,它有“字根”——大约有700个基本部件,能像积木一样拼出所有汉字。举个例子:“木”加“子”是“李”,“木”加“对”是“树”。学会了“木”,你就认识了一大片带“木”的字。
在2024年,阿里的“鹿班”AI成功破译了一批甲骨文卜辞。研究人员发现,3000年前的汉字就已经有了完整的“形旁表意”系统。而今天的计算机编程语言,用的也是这个逻辑:有限指令,无限组合。
一位外国网友理解的就比较深刻,他说:“我们应该发明一套改良的汉字表意文字,这样我们就可以用它来书写任何语言。”

外国网友相关讨论
其次是汉字的“表意能力”极强。
字母文字记录的是“音”——声音会变,方言不同,写下来的文字就不同。拉丁语分化出法语、西班牙语、意大利语,大概就是这个原因。
而汉字走的是另一条路:它直接编码“意”。一个“水”旁的字,一眼看过去就知道这个字的意思跟液体有关。
这个选择带来了一个巨大的好处:汉字可以跨越时间和空间。比如,可能两个方言区的人互相听不懂对方在说什么,但写在纸上,全都悟了。再比如,一个现代人和一个秦朝人,说话完全不一样,但写在竹简上,现代人能猜出七八成。你不需要学“古汉语发音”就能读古书,这就是汉字给你的特权。
你看,汉字的强大不在于它“保守”,而在于它“能装”。无论什么新概念,它都有招能让你看懂。


图片源于网络
而最关键的是汉字能用旧字符,创造新世界。
汉字的巧妙之处就在于:它没有无限膨胀下去。从两千年前的《说文解字》收录9353字,到今天常用字也就4000个左右。这套“以旧换新”的逻辑,让汉字的认知负荷始终保持稳定。
除此之外,TechCrunch也报道了一个有意思的事:OpenAI的o1模型,有时候会莫名其妙地开始用中文“思考”。有网友说:“这不是第一次了,AI好像自己发现中文更省脑子。”
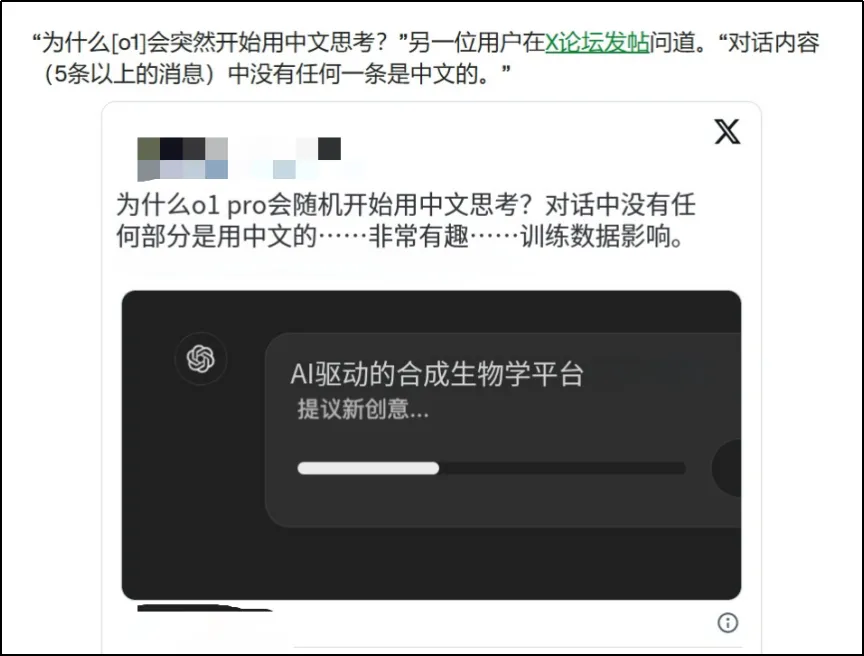
来源:TechCrunch
5000年前,咱们的老祖宗不知道什么是AI,不知道什么是互联网,不知道什么是元宇宙,但他们设计的“汉字系统”,今天依然能用,而且用得更顺手。
不是汉字碰巧适应了这个时代。而是这个时代的技术逻辑——信息密度、模块化组合、意义稳定恰好验证了汉字五千年前的设计选择。
回到开头那个问题:信息洪流中,凭什么我们能比别人更从容?你想想。你以为你在刷手机,其实你是在用“认知外挂”。汉字,就是老祖宗给我们开的永久VIP。
而我想说的是:从容不迫的底气,不在别处。就在你每天刷手机时快速扫过的文字里;就在你看到新词秒懂的那一瞬间里;就在你翻开古书却能读懂大半的那种踏实感里;就在——每一个汉字里。
