 夜雨聆风
夜雨聆风
嗨,新产品体验如何?
4月16日(昨天),我们发布了两款新产品——Kerminal 和 KerWork,对,你可能已经试过,我猜你最开始大概会有这样的感受:
“跑不出来”:让它写个算子,结果编译不过,改了两轮还是不对
“不好用”:什么都要我解释,还不如自己写
“不够自动”:我以为它能自动搞定,结果还是得我盯着
这些感受是真实的,也是正常的。前几次使用的体验确实是最差的——因为 Agent 对你的项目一无所知:不知道编译命令是什么,不知道代码规范是什么,不知道头文件在哪个仓。
但这里有一条不那么直觉的曲线:你在前几次使用中踩的坑,恰好就是让后面越来越顺的燃料。每次 Agent 犯的错、问的蠢问题,你把答案写进一个叫 AGENTS.md 的文件里(后面第四节会讲),下次它就不会再犯。重复的操作流程做成 Skill(第五节会讲),以后自动触发。
积累到一定程度后,你会发现一句“参考 xxx 写一个 YYY 算子”就能直接出活——因为它需要的背景知识、操作流程、编码规范全都已经在它的“记忆”里了。
写作这份指南,就是为了帮你更快地走过前期的摩擦期。
开始之前,不妨先来个速查
7 个核心方法,你用了哪些?
1. 像交代任务一样说话:说清楚要做什么、可以参考什么代码、有什么特殊约束。不需要学特殊句式。
2.失败是过程,不是结论:Agent 第一次没做对很正常。让它接着改,改两三轮是常态。随着积累,一次成功率会越来越高。
3.它说“做不到”?先别急着接受:试试让它再想想,或者换个角度重新描述你的目标。很多时候它只是陷入了死角,推一把就通了。
4.感觉不对就喊停:如果你在讨论一个开始时没预期到的技术细节,停下来问自己"这跟我要的结果是什么关系"。说不清就让 Agent 帮你重新梳理全局。
5. 刚开始,一次对话干一件事:拆成几步,每步目标明确,效果更可控。随着 AGENTS.md 和 Skill 的积累,Agent 对你项目越来越熟,能一次搞定的事会越来越多。
6.重要信息写下来:反复跟它解释的东西,写进项目里的 AGENTS.md 文件,它下次自动能看到。
7. 先让它出计划:复杂任务开始前说"先列个计划我看看",确认方向再动手,省得做完了方向不对。
怎么样?
以上方法用得多,恭喜你们协作顺利
如果用得偏少,推荐你继续阅读正文
Part 1
我该怎么跟它说?
你不需要学什么“prompt 工程”。想象你团队来了个新同事——技术功底很强,但完全不了解你们的项目。你怎么给ta交代任务,就怎么跟 Agent 说话。
(随着你在项目里积累 AGENTS.md 和 Skill,Agent 会越来越“熟悉”你们的项目,需要你手动交代的事情会越来越少——就像新同事逐渐变成老同事。)
说清楚三件事就够了:
做什么:具体的目标,不要太笼统
参考什么:已有的代码、文档、类似实现有什么特殊情况:环境依赖、编译约束、踩过的坑
对比:
❌ "帮我写一个 MatMul 算子"
✅ "参考 kernels/matmul/ 的实现,帮我写一个支持转置的 MatMul 算子,输入是 float16,Tiling 参数定义放在 tiling/目录下。编译命令是 xxx"
❌ "帮我在昇腾上部署deepseek-ocr-2模型"
✅ "在这台昇腾设备上适配部署DeepSeek-ocr-2模型,模型权重链接:https://www.modelscope.cn/models/deepseek-ai/DeepSeek-OCR-2,适配部署方案参考:https://github.com/deepseek-ai/DeepSeek-OCR-2/。制定适配方案,先跑通模型,再做性能优化。"
你不确定该说多少?让它来问你:
"在开始之前,你觉得还需要知道什么信息?先问我。"
Agent 会列出它觉得缺少的信息,你只需要回答就行。这比你自己猜"它需要知道什么"高效得多。而且它问出的问题,往往就是后面值得写进 AGENTS.md 的内容(后面第四节会讲)。
比如:
❌ "帮我写一个mhc-post算子"
✅ "使用Ascendc,基于25年12月31日deepseek发布的论文(mHC: Manifold-Constrained Hyper-Connections),实现其中的mhc_post操作,如果不清楚算子定义,搜索论文(https://arxiv.org/pdf/2512.24880)和相关代码,先写测试后写实现。算子开发之前或算子开发过程中,你觉得还需要知道什么,先直接询问我 "
❌ "帮我部署一个Qwen3.5-27B"
✅ "使用vllm-ascend镜像部署Qwen3.5-27B,模型权重链接:XXXX,部署参考手册:https://ai.gitcode.com/vLLM_Ascend/Qwen3.5-27B。在部署开始之前或者部署过程中,你觉得还需要知道什么信息,先直接询问我"
Part 2
它做错了,是不是不行?
刚开始用的时候,Agent 第一次就写对的情况存在,但不是常态。改两三轮是正常的工作方式,不是工具有问题。 不过随着你在 AGENTS.md 里沉淀了编译环境、代码规范、常见坑点等信息,Agent 的一次成功率会明显提高——它犯过的错不会再犯第二次。
这和你自己写代码一样——写完跑一下,报错了看报错信息,改了再跑。区别只是现在这个循环里有个助手帮你写和改。
报错了怎么办?
Kerminal 能直接执行编译、运行测试,它自己就能看到报错信息并尝试修复。大多数时候你不需要手动贴报错,让它跑就行。
但有些场景下 Agent 可能需要你帮忙:
报错信息本身质量差:有些工具链的报错很模糊(比如只给一个错误码没有上下文),Agent 看了也一头雾水。这时候你的经验就是关键信息——"这个错误码通常是因为 XX"或者"你去看看 YY 文件里的 ZZ 配置"。
报错发生在 Agent 够不到的地方:比如在远程设备上运行、或者需要特定硬件环境才能复现的问题,你需要把报错信息拿过来给它看。
对比:
❌ 看到报错 → "它不行" → 关掉工具 → 自己写
✅ Agent 自己跑命令看到报错 → 自己尝试修复 → 如果报错信息太模糊,你补充一句"这个错通常是 XX 原因" → 继续修
✅ 远程设备上的报错 → 你贴过来 → "这是在 NPU 上跑出来的报错,帮我分析下原因"
不同类型的任务,配合方式不同:
你想做什么
怎么跟 Agent 配合
探索方案
"这个问题有哪些思路?各自的优缺点?"
— 它给选项,你做决策
写代码
"按这个思路实现"
— 它写,你审查
查问题
"这个报错什么原因?"
— 一起分析
审查代码
"这个问题有哪些思路?各自的优缺点?"
— 它给选项,你做决策
有意识地选择当前是哪种模式,比含糊地说:"帮我搞一下"效果好得多。
比如:
在完成mhc-post算子的开发后,要对性能进行优化,可以告诉它:"对于mhc-post这个算子,性能上还有没有可以优化的空间?给我一些优化选项和建议。"
当它给出具体的优化建议时:
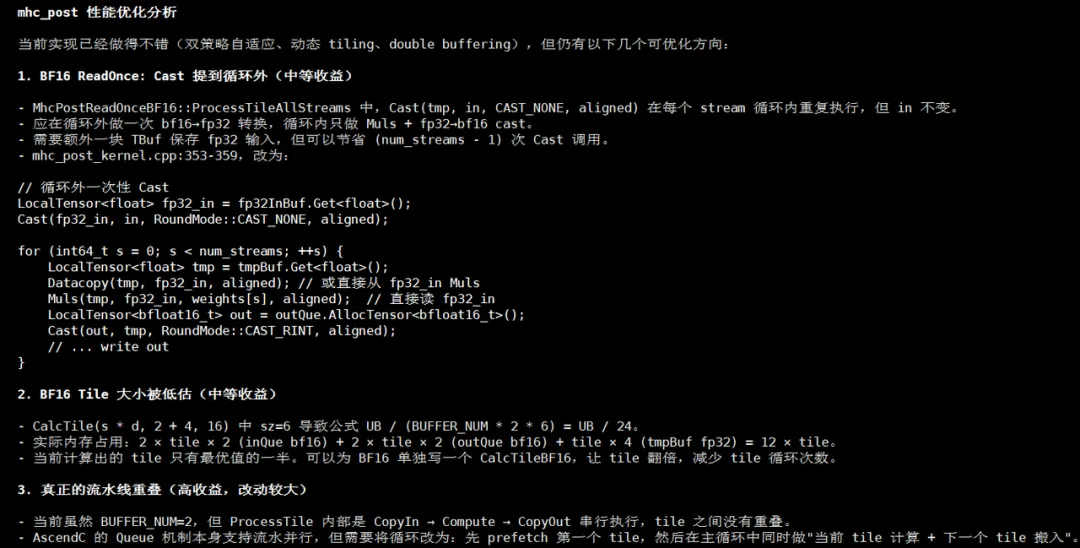
我们可以根据自身经验进行识别,筛选有价值的优化方向,告诉它:"先按照第三个优化点的思路进行实现。"
在实现过程中,如果没有在目标硬件上运行Agent,且遇到了报错,可以将完整报错内容粘贴给它或将报错信息写入error.log报错日志文件,放在Agent工作目录下,告诉它:"算子编译过程中遇到了报错,帮我分析目录下的error.log报错日志文件中的详细报错信息,并给出解决的方案。"
算子计算逻辑跑通后,我们可以把算子开发的规范文档或算子仓库内的相似参考给它,让它进行代码格式和规范的审查:"参考
docs/DevelopmentSpecifications.md中的规范,审查mhc-post算子项目,将存在的问题按照整改优先级排列。"
以上2个协作方法,希望可以帮到你
意犹未尽?
后续,我们将发布《指南》下半部分,特别是大家最关心的【如何创建让你的 AI “长记性”的 AGENTS.md 文件】和【复盘方法论】。
今天是两款新品Kerminal 和 KerWork 限时免费活动的第二天,明天23:59活动就截止啦,速速上车,期待你的使用和反馈!
>>> Kerminal 官网:
https://kerminal.cn
>>> KerWork 官网:
https://kerwork.cn/
>>> 欢迎加入我们的社群
(如遇二维码失效,欢迎在后台发送“进群”,小助手将联系你🥰)

Kerminal用户群

KerWork用户群
