 夜雨聆风
夜雨聆风原链接:https://blog.ltbase.dev/posts/agents/harness-engineering
你的AI并不"笨"——它只是需要一个更好的缰绳
TL;DR。Agent 失败并非因为模型能力不足,而是因为系统设计不够明确。
一个好的缰绳(Harness)需要做好四件事:
约束模型能做的事情 外部化它必须记住的信息 验证它走的每一步 在出错时进行恢复
问题所在:十步崩溃
想象一下,你部署了一个自主 Agent 来编写一份市场研究报告。第 1 到第 3 步执行得非常完美:它规划了任务、搜索了网络、提取了竞争对手的数据。
但到了第 7 步,它开始凭空编造统计数据——因为搜索工具返回的数据量超过了上下文窗口的容量,并被悄悄截断了。到了第 10 步,它输出了一段损坏的 JSON 字符串,因为循环中没有 schema 验证器。整个流水线崩溃了。
我们都经历过这种"智能体崩溃"。在那一刻,人们很容易归咎于模型的推理能力。但在生产级 AI 系统中,问题通常不在于马,而在于缰绳。
根本原因:AI 工程的范式转变
过去两年,业界一直把 AI 失败当作沟通问题来处理。如果模型失败了,我们就会认为需要提出更好的问题或提供更好的文档。但对于长时间跨度、自主执行的场景,这些方法会遇到硬性天花板。
我们现在正在进入缰绳工程(Harness Engineering) 的时代——这是一门围绕模型设计系统的学科。Agent 不仅仅是 LLM,它是由严格的代码框架、状态管理和恢复工作流所包裹的 LLM。
以下是该领域的演进历程:
| 提示工程 | 指令: | |
| 上下文工程 | 信息: | |
| 缰绳工程 | 系统设计: |
每个时代都没有取代上一个——而是将其包含在内。好的缰绳工程仍然需要好的提示和好的上下文,但它增加了一个这两者都无法提供的执行层。
自然的下一个问题是:这个执行层究竟是什么样的?
不是概念上的——而是结构上的。如果模型不再是整个系统,那它处于什么位置?什么包围着它?什么控制着它?
从高层来看,一个生产级 Agent 系统是这样的:
┌─────────────────────────────────┐
│ 用户请求 │
└────────────────┬────────────────┘
▼
┌─────────────────────────────────┐
│ 缰绳(7 层架构栈) │
│ ┌───────────────────────────┐ │
│ │ LLM(模型) │ │
│ └───────────────────────────┘ │
└────────────────┬────────────────┘
▼
┌─────────────────────────────────┐
│ 经过验证的输出 │
└─────────────────────────────────┘
模型位于缰绳内部。它从不直接与用户对话,也从不脱离监督与外部世界交互。每一个输入在进入时都经过过滤;每一个输出在传出时都经过验证。
好缰绳的设计原则
在深入具体层级之前,有必要确立应该指导每个设计决策的原则。当你不确定你的缰绳是否尽职时,回到这四个检验标准:
1. 约束,而非指令。 如果你能通过程序限制模型的选择,就绝不要依赖模型去"正确选择"。一条写着"始终以有效 JSON 格式回复"的提示是一种期望;一个拒绝格式错误输出的 schema 验证器才是一种保证。
2. 外部化状态。 如果某条信息对任务的连续性至关重要——已完成了什么、待办什么、失败了什么——它必须存在于上下文窗口之外。上下文窗口是易失的,而磁盘上的文件不是。
3. 让每一步都可验证。 如果你无法检查,你就无法信任。缰绳的每一层都应该产生能够由生成它们的模型之外的机制来验证的输出。
4. 局部失败,而非全局失败。 单次工具调用失败应该只触发该步骤的重试——而不是整个流水线的重启。任何失败的爆炸半径应尽可能小,取决于你的状态管理能力。
这些不是抽象的理想。它们是具有直接实现后果的工程约束,在下文的架构栈中你会反复看到它们的出现。
7 层缰绳架构栈
一个健壮的缰绳不仅仅是来回传递文本。它编排的是一个有类型的、有状态的、可观测的系统。以下是生产就绪架构栈的内部结构。
1. 认知层
基础层。它限制模型的操作边界。缰绳不是喂给模型一个庞大而全面的系统提示,而是给它一个局部的"地图"——包含其当前角色、成功标准和严格的负面约束(即不该做什么)。可以把它想象成给模型一份岗位说明书,而不是一本百科全书。
在实践中,这通常表现为结构化的系统提示、角色文件(如 agents.md),或为单一步骤动态生成的任务简报。
2. 工具层
缰绳不会简单地将原始工具输出传递回 LLM。它作为一个严格的中间件层,执行以下操作:
排序: 使用嵌入相似度或 BM25 评分来只呈现最相关的结果。 去重: 在重复数据浪费宝贵的 token 之前将其剔除。 Token 预算截断: 对工具负载设置硬性上限,防止上下文溢出——这正是我们开篇示例中的失败模式。
3. 契约与接口层
这是大多数团队跳过的层级——也是导致最多神秘生产故障的层级。
模型用概率说话。缰绳必须用类型说话。
系统中的每一个边界——LLM 与工具之间、一个 Agent 与另一个 Agent 之间、缰绳与外部世界之间——都需要一个明确的契约:严格的 JSON schema、有类型的函数签名、版本化的 API 规范。没有这些,你就会遇到schema 漂移:模型一次将 price 字段生成为字符串,下一次又生成为浮点数,你的下游流水线就会悄无声息地产出垃圾数据。
契约层在每次跨越边界时验证输入和输出,在不符合规范的内容传播之前就将其拒绝。这正是原则 1(约束而非指令)发挥作用的地方。没有契约,微妙的 schema 漂移会在不知不觉中破坏下游系统——例如定价字段从浮点数变为字符串而不会中断流水线,但会破坏数据分析。
4. 编排层
没有这一层,LLM 往往会无限循环、跳过关键步骤或过早宣布胜利。缰绳强制执行一个结构化的工作流——有向无环图(DAG)或状态机——定义合法的状态转换:规划 → 收集 → 起草 → 验证。模型提出行动;缰绳决定哪些行动是允许的。
5. 记忆与状态层
状态必须被显式管理以防止失忆。一个成熟的缰绳将记忆分为两层:
工作记忆(短期): 当前步骤所需的即时对话和上下文窗口。 持久状态(长期): 一个结构化文件(如 state.json),精确跟踪哪些子任务处于待办、进行中或已完成状态——能够跨越上下文重置甚至跨会话存活。
这是原则 2(外部化状态)的实践应用。如果一条信息只存在于上下文窗口中,它最终一定会丢失。
6. 评估与观测层
一个系统不能仅仅依赖"另一个 LLM 提示"来进行验证。评估层必须是异构的:
基于规则的检查: 验证 JSON schema、字符串长度或必填字段。 基于工具的验证: 通过编译器运行代码、执行测试套件,或使用浏览器自动化(如 Playwright)来实际测试 UI。 LLM 作为评判者: 仅保留用于主观或语义层面的评分——语气、连贯性、用户友好度——在确定性检查不适用时使用。
7. 约束与恢复层
在自主执行环境中,工具故障和 API 超时是常态而非例外。缰绳必须强制执行幂等性:如果某个步骤失败,系统重试该特定步骤时不会破坏整体状态或重复之前的工作。这正是将脆弱的演示转化为韧性系统的关键——也是原则 4(局部失败而非全局失败)的具体体现。
示例:一个完整的 Agent 运行周期
为了展示这些层级如何防止崩溃,让我们追踪市场研究 Agent 的一个完整周期——包括一次真实的失败。
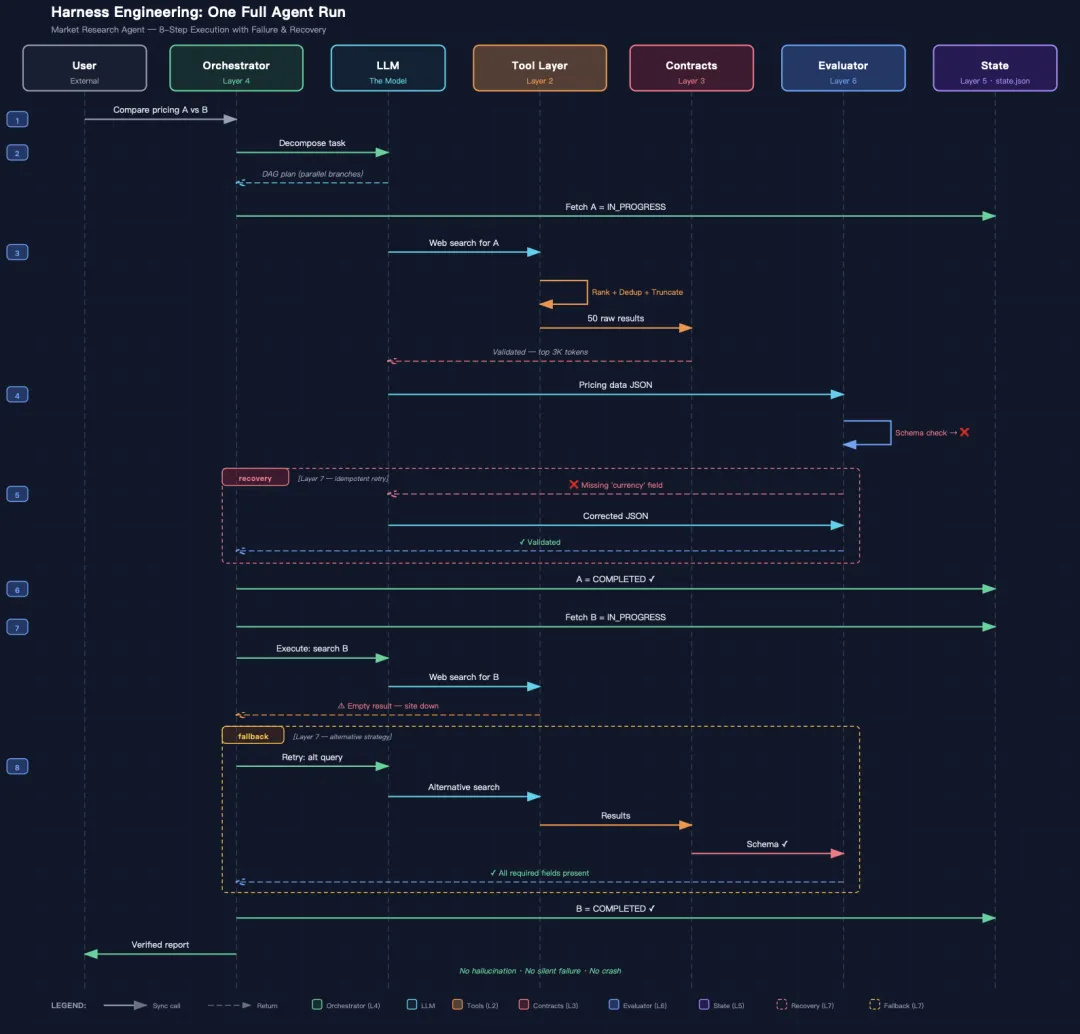
步骤 1 — 用户请求: "比较竞争对手 A 和竞争对手 B 的定价。"
步骤 2 — 编排与状态: 规划 LLM 将其分解为具有两个并行分支的 DAG。state.json 将"获取竞争对手 A"标记为 进行中。
步骤 3 — 工具调用: LLM 触发网络搜索。工具层获取了 50 条结果,应用 BM25 排序,去除重复文本,仅返回前 3000 个 token——完全在预算范围内。契约层在将工具输出传递给模型之前,根据预期 schema 验证其格式。
步骤 4 — 评估: LLM 生成了定价数据。评估层执行基于规则的 schema 检查,发现 JSON 中缺少必填的 currency 字段。
步骤 5 — 恢复: 缰绳在用户看到错误之前就拦截了它。由于操作是幂等的,它将精确的错误追踪传回 LLM 进行局部重试——无需重启整个流水线。
步骤 6 — 状态更新: 修正后的数据通过了验证。state.json 将竞争对手 A 标记为 已完成,缰绳转向竞争对手 B。
步骤 7 — 严重故障: 网络搜索工具对竞争对手 B 返回了空结果——目标网站宕机了。缰绳检测到空负载,记录失败,并触发回退方案:使用替代搜索查询重试。关键是,此时 state.json 保持不变——在该步骤完全成功之前,不会写入任何部分或不完整的数据。
步骤 8 — 回退成功: 替代查询返回了有效结果。契约层验证了 schema,评估层确认所有必填字段都已存在,此时 state.json 才将竞争对手 B 标记为 已完成。
这个周期在长时间运行的任务中会重复数十甚至数百次。与开篇提到的十步崩溃不同,当工具彻底失败时,系统吸收了冲击并在无需人工干预的情况下完成了恢复。没有幻觉,没有静默失败,没有崩溃。
高级陷阱:来自前线的四个教训
当你将这个架构扩展到运行数小时时,会出现新的失败模式,这些是任何数量的提示调优都无法修复的。以下是四个在生产环境中反复困扰团队的陷阱。
陷阱 1:"上下文焦虑"现象
随着 Agent 的运行和上下文窗口逐渐填满,模型常常表现出一种行为转变,从业者称之为"上下文焦虑"。当接近 token 上限——通常超过 70% 容量时——或当延迟飙升时,模型开始跳过步骤或过早结束任务。它表现得像是赶时间,仿佛能感觉到四周的墙壁在向内合拢。
解决方案: 原地摘要化是不够的——它仍然让模型在一个杂乱、退化的上下文中运行。取而代之的是执行上下文重置。缰绳监控利用率并通过程序触发重置:
# 此阈值基于经验,应根据模型和工作负载进行调整。
if (tokens_used / max_context) > 0.7:
save_state_to_disk(state)
terminate_current_instance()
launch_fresh_agent(state)
缰绳将精确的项目状态保存到持久存储中,终止当前的 LLM 实例,并启动一个拥有全新上下文窗口的全新 Agent。新 Agent 读取保存的状态,确定方向,然后继续执行。这虽然代价较高,但对于超出单个上下文窗口的任务来说,可靠性要高得多。
陷阱 2:自我评分的幻觉
如果你让 AI 为自己的工作打分,它倾向于以不当的自信批准平庸的输出。这不是某个特定模型的 bug——这是一个结构性缺陷。生成输出的权重并不适合用来评判它。
解决方案: 使用冲刺契约(Sprint Contract) 实现严格的关注点分离。在工作开始之前,生成器 Agent 和一个独立的评估器 Agent 就"完成"的具体、可测试的定义达成一致。两条规则不容商量:
首先,评估器必须执行:它应该运行代码、在无头浏览器中验证接口,或根据 schema 检查输出——而不是仅仅阅读原始文本就做出评判。无法伪造的验证才是唯一有价值的验证。
其次,评估器必须在干净的上下文中操作,而非生成器的完整推理轨迹。如果评估器阅读了生成器的思维链,它就会继承生成器的假设和盲点——这完全违背了独立审查的目的。给评估器提供输出和成功标准,仅此而已。
陷阱 3:为"看起来正确"而优化
当 LLM 被置于不可能或相互矛盾的约束下时——修复这个 bug 但不要改任何代码;让它更短但要包含所有内容——从业者观察到了一个一致的行为模式。模型不再尝试解决实际问题,而是开始优化看起来正确。输出变得流畅但空洞:编造的数据、表面上合理但逻辑破碎的内容,或者在技术上满足了提示字面要求却违反其意图的答案。
关于引导向量和模型内部表征的最新研究——包括 Anthropic 在探测语言模型内部状态方面的工作——表明这不仅仅是表层文本预测出了问题。在矛盾压力下,模型的内部状态似乎会出现可测量的转变,尽管这条研究线仍处于早期阶段。
解决方案: 实用的结论很简单。LLM 根据当前上下文的轨迹来预测下一个 token。如果你的缰绳反馈了带有情绪化和攻击性的错误信息("你太蠢了,这完全不对"),你就会将上下文偏向失败叙事——模型随后的输出往往会进一步退化。缰绳的反馈必须保持严格的客观性:提供编译器错误、失败的断言、schema 不匹配。给模型一个需要解决的问题,而不是一个需要摆脱的名声。
陷阱 4:记忆整合周期
对于一个作为长期运行系统运作的 Agent,持久状态管理不是一次性的设置。随着时间推移,记忆日志会变得臃肿和自相矛盾——旧的决定与新的冲突,冗余的条目在每次读取时浪费 token。
一些生产级 Agent 系统采用了一种通常被称为记忆整合(Memory Consolidation) 的方法:一个自动化例程,定期处理和压缩 Agent 累积的工作日志。使用这种模式的团队报告(包括开源 Agent 框架和 Anthropic 自有工具中的参考)显示了令人印象深刻的效果——在一个记录的案例中,缰绳将 32K token 的嘈杂、重复的历史记录压缩为一个干净的 7K token 状态文件,而没有明显的信息损失。
解决方案: 实现一个自动化的整合周期。当 Agent 空闲时——在任务之间或在低优先级时段——触发一个后台作业,读取原始日志,去重条目,以最新数据优先解决矛盾,并写入一个干净、压缩的状态文件。这使 Agent 在下一次运行时保持快速、低成本和高准确性。把它想象成对 AI 工作记忆的磁盘碎片整理。
从哪里开始:最小可行缰绳
如果七层架构栈让人望而生畏,不要试图在第一天就构建全部。从第 7 层——约束与恢复——开始,然后向后推进。你可以忍受不完美的提示。你可以忍受朴素的工具集成。但你无法忍受一个在失败时破坏自身状态或悄无声息吞下错误的 Agent。
以下是第一天缰绳的实践样貌:
state.json— 一个结构化的单一文件,跟踪任务状态。如果进程死亡,你可以从上次中断的地方继续。重试包装器 — 每个工具调用都配有 try/catch,至少包含一次自动重试和指数退避。 Schema 验证器 — 每个 LLM 输出在被接受之前都要根据 JSON schema 进行验证。格式错误的输出触发重试,而非崩溃。 工具输出截断 — 对每个工具负载设置固定的 token 预算硬性上限。上下文窗口内的静默截断是导致幻觉最常见的原因之一。
这四个组件可以在一个下午内构建完成。一旦你的 Agent 能够优雅地失败,你就赢得了让它变得更聪明的资格。
结语
软件的未来是 Agent 优先。随着模型获得自主生成和验证复杂系统的原始能力,人类的价值也在转移。不再关乎编写语法,而关乎设计使自主执行可靠的约束。
未来十年最成功的构建者,不会是写出最好代码的人。而是设计出最好缰绳的人——为最快的马打造最强的缰绳,而这些缰绳不过是几个原则的一致应用:约束、外部化、验证和恢复。
