 夜雨聆风
夜雨聆风最近几个月,一直在重度开发Quant Agent平台,架构多次推倒重建,初版终于基本完成。在3月31号的时候发了一条pyq

发现大多数人对于ai-native quant agent的理解是rd-agent或者llm因子挖掘,在我看来,这两者是很实用的工具,能够高效的提高人的研究效率,但是一个真正ai-native面向的使用者应该是AI而非是人。
因此在回答这个问题之前,让我们先来思考两个问题:
一个junior quant的基本技能是什么?junior和senior quant的区别又是什么?
第一个问题很好回答,junior quant的基本能力在于,丰富的基础知识(编程/统计/金融知识等),熟练掌握各类工具(数据库,API,qlib/alphalens/backtrader/vnpy等),以及复现/创造因子的能力。
而对于一个senior quant,从表面来看,他可能是具备了更多的研究经验,独到的因子/模型构造能力,而这些的本质,均来自与长期的知识积累。
当我们明白了这些,就知道了该如何开发一个真正的quant-agent框架,而不是一个简单的LLM workflow。 其核心在于:
研究过程能不能被结构化?研究经验能不能被积累?
这才是分水岭。
从这个问题出发的。不涉及技术细节,我来讲讲Quant Agent框架的设计思路,
一、别把 Quant Agent 做成聊天框
很多金融 Agent原型都是从聊天框开始的。
你丢一篇研报进去,它总结复现。你说写个因子,它生成代码。你说解释一下结果,它给你一段分析。
这个体验很顺,但也有一个问题:它只是一次性的咨询。
今天问一次,明天换个说法再问一次,模型可能给出另一套实验定义。标签变了,持有期变了,股票池变了,成本假设也变了。表面上都是在研究同一个想法,实际上已经不是同一个实验。
研究不是“回答问题”,而是一条连续的证据链。一个想法从自然语言开始,经过假设、实验规范、数据快照、运行结果、诊断、复盘,最后才变成一条可以复用的知识。
所以我更愿意把 Quant Agent 理解成一个研究操作系统,而不是聊天助手。
它至少要围绕几类研究资产转:
有了这些资产,Agent 才不是在“帮你答一下”。它是在推进研究。
二、研究员真正贵的地方,是经验
我以前开发的研究框架都有同一个问题:每次都像第一次做研究。
读完材料,生成因子,跑完模型,然后结束。
如果结果好,因子入库。如果结果差,日志里留一个失败记录。下次再遇到类似问题,系统基本不记得以前发生过什么。
但真实的研究员不是这样工作的。
做久了的资深研究员,积累了很多经验:
这个因子在小票上容易假阳性。这个行业分类版本会影响中性化结果。某类财务字段如果不是 PIT,回测会特别漂亮。高换手策略看起来好,一加成本就没了。某篇论文的方法可以借鉴,但原实验的样本切分不太可信。有些失败不是想法错了,而是数据口径没对上。
这些东西不一定写在论文里,也不一定出现在正式报告里,但它们决定研究效率。
所以真正可取代研究员的 Agent,必须有知识积累能力。不是普通 RAG 那种“把文档塞进向量库再检索”,而是把研究过程里的判断、失败、修复、边界都沉淀下来。
尤其是失败。
量化研究里最浪费的不是失败本身,而是失败没有被保存。一个策略失败了,如果只留下“不通过”,那它几乎没有价值。但如果能留下:
为什么失败?是 IC 不稳定,还是换手太高?是样本外失效,还是成本吃掉收益?是数据字段有问题,还是假设本身太弱?这个失败和历史上哪个失败相似?下次遇到类似想法,应该先检查什么?
那它就是资产。
一个好的 Quant Agent,不应该只会保存成功案例。它更应该记住那些“差一点把人骗了”的失败案例。
三、知识库不是文档仓库,而是研究记忆
很多人一说知识积累,第一反应是知识库。把研报、论文、代码、实验报告都丢进去,然后做语义检索。
这当然有用,但还不够。
量化研究需要的知识,不是这篇研报论文讲了什么,而是这篇研报论文的模型能否复现,复现以后能够带来启发。
比如“动量因子有效”这句话本身没什么价值。真正有价值的是:
在哪个市场?什么股票池?多长持有期?有没有行业中性?成本多少?样本期覆盖哪些市场状态?失效发生在哪些年份?和哪些风险因子相关?容量是否可接受?
没有这些边界,知识就会变成口号。
所以 Agent 的知识积累,不应该只是文本切块和相似检索。它应该围绕研究资产建立记忆。
一次实验结束后,系统应该把结果变成一张可复用的知识卡。里面不只写结论,还要写证据、适用范围、风险提示、失败原因、相关实验、后续建议。
这才像一个研究员在做笔记。
四、Agent 做控制,底层必须确定
量化研究里,有些错误非常隐蔽。模型如果在标签、复权、股票池、成本上“发挥”一下,结果可能看起来更好,但研究已经变味了。
所以一个靠谱的 Agent 架构,大概应该是:
Agent 负责提出和选择系统负责约束和执行人类负责高风险审批知识库负责长期记忆这几个角色不能混在一起。
Agent 可以建议“下一步做稳健性测试”。系统要保证测试口径一致。人类要审批高风险变更。知识库要记录这次测试为什么做、结果如何、下次怎么用。
少一个环节,系统都会变轻。
五、数据层要先问“能不能研究”
很多 Demo 会直接接外部数据 API。跑得快,看起来也爽。
但研究系统不能这么随意。
研究需要复现。复现需要数据快照。一次实验至少要知道:当时用的是什么股票池,字段来自哪里,是否 PIT,复权口径是什么,缺失率多少,行业分类用哪个版本,有没有幸存者偏差,停牌和涨跌停有没有纳入可交易性处理。
Agent需要自行判断数据从何处获取,以及该如何对数据做进一步处理。
一个合格的 Quant Agent,不应该只会说“这个字段有”。它要知道这个字段能不能用于这个实验。
这背后其实也是知识积累。
某个字段过去经常缺失,应该记住。某类财务指标如果没有 PIT,应该标红。某个数据源在某些年份覆盖不稳定,应该进入知识卡。某个市场状态下,停牌和涨跌停会显著影响回测,应该在后续实验里自动提醒。
这些都不是一次性信息,而是研究经验。
六、失败也要成为知识
我觉得 Quant Agent 最容易被低估的能力,不是自动跑成功实验,而是自动整理失败实验。
成功实验大家都会保存。失败实验通常没人认真管。
但现实是,研究团队大部分时间都在失败。因子无效,样本外崩,换手太高,容量不够,数据有坑,口径漂移,回测引擎报错。真正的研究积累,就是从这些失败里长出来的。
系统要把失败分清楚:
这些失败不应该只出现在日志里。它们应该进入知识系统。
下一次 Agent 再看到类似假设时,应该能提醒:这个方向之前做过,失败原因是换手过高;类似字段曾经有 PIT 风险,先做数据审计;这个策略在全 A 有效,但在大盘股池失效;上次不是假设失败,而是执行后端不支持某个诊断口径。
这才叫研究记忆。
如果 Agent 每次都从零开始,那它只是在消耗算力。如果它能记住失败,它才开始像一个研究员。
七、壁垒在知识积累
Quant Agent真正的壁垒在于知识积累。结合我们积累的数万篇量化论文研报,以及团队资深Quant的经验,将这些知识都可以沉淀积累到Agent系统之中。
第一次研究,它可能只是一个助手。第十次研究,它开始知道哪些数据要小心。第一百次研究,它开始知道哪些方向容易是假阳性。第一千次研究,它积累的失败、修复、诊断、规范和适用边界,会变成团队自己的研究记忆。
这时候,Agent 才不再只是模型能力展示,而是研究组织的一部分。
所以我的系统最关心的不是“它今天结果有多好”,而是:
它能不能记住昨天为什么错。它能不能把今天的失败变成明天的提醒。它能不能把一个人的研究经验,沉淀成团队可复用的资产。
如果做不到这些,它再会写代码,也只是高级助手。如果做到了这些,它才能接近资深研究员。
最后以前两天的论文STORM为例,演示一下我们Quant Agent的运行模式:
提供论文PDF:
Agent提取假设:
设置实验specs:
Agent提取数据,运行结果:
生成知识: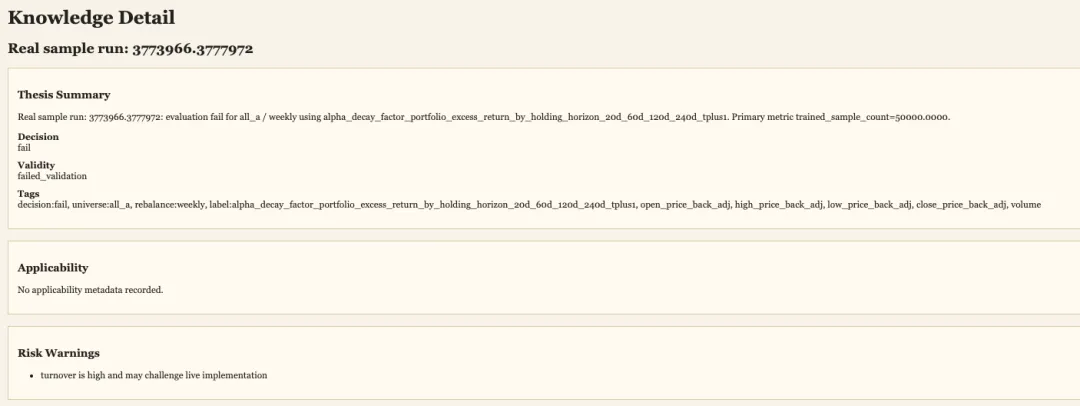
运行期间agent会自行修复出现的问题,直至最终生成可用知识为止。
Quant Agent框架的社区版本即将开启内测,敬请期待。
欢迎在评论区聊聊你对于ai-native quant agent的理解
关于QuantML
QuantML 是链接全球顶尖量化人才的高端社群,我们聚焦于机器学习在量化投资中的最前沿应用。
核心价值:
顶级圈层: 社区涵盖头部机构从业者、知名私募创始人、机构量化负责人,基金经理,券商金工分析师、GitHub千星作者及顶会学者构成。 每日高价值内容: 持续分享前沿论文、论文研报复现、模型代码、核心Alpha因子以及QuantML-Qlib框架等。
加入我们,与最强大脑同行,洞见量化未来。

