 夜雨聆风
夜雨聆风摘要:在 Agent 迈向工程化落地的进程中,单点提示词已难以承载复杂的业务流。本文将深度拆解 ReAct、Plan-and-Execute 等 5 种核心设计模式,提供一种基于业务场景的架构选型思路——以最小必要复杂度构建生产级 Agent。
过去一年,让 Agent 稳定、可预期地完成复杂任务,是所有开发者共同的痛点。单靠一句简单的提示词,已经无法撑起真正的业务流。
为了约束大模型的发散性,业界摸索出了不同的“Agent 设计模式”——本质上,它们就是给 Agent 设定不同的工作流和脚手架。随着各大厂商相继推出 Agent SDK,这些模式正在固化为标准组件。
本文将聚焦其中常用的 5 种设计模式:ReAct、Plan-and-Execute、Tool Use、Reflection 以及 Multi-Agent。通过系统拆解其运转机制、能力边界与工程代价,为真实业务场景下的架构选型建立理性的评估标准。
ReAct:让 AI 边想边做
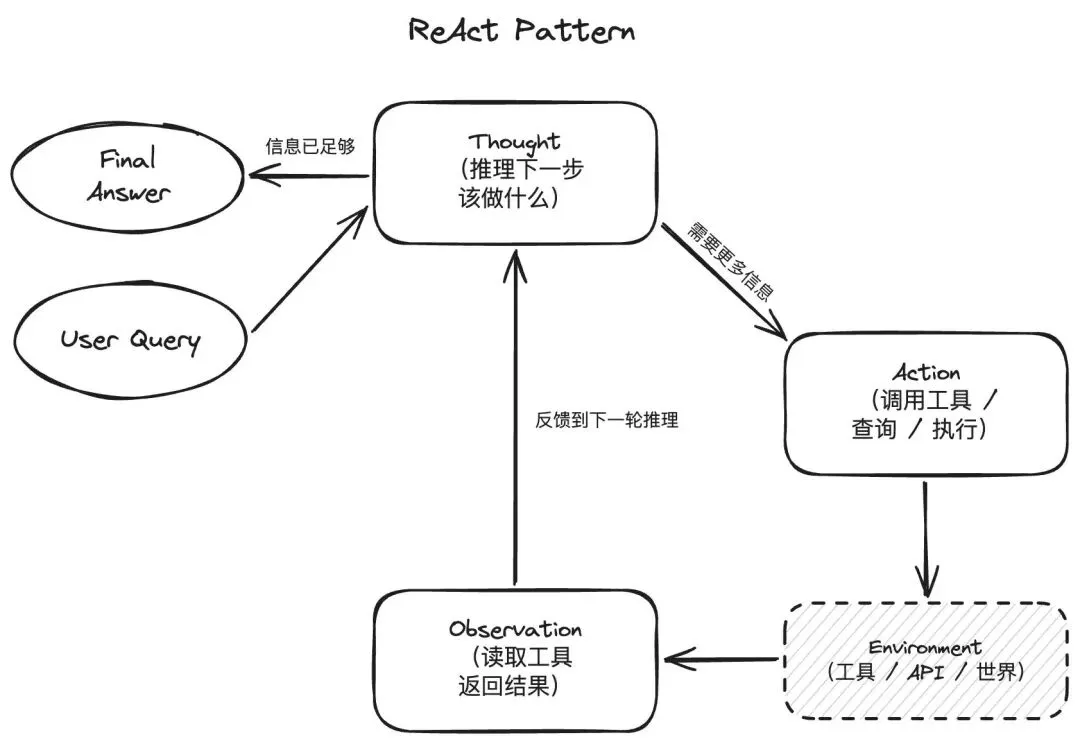
ReAct(Reasoning + Acting)是目前最基础的 Agent 设计模式,也是大部分 Agent 框架的默认工作方式。它的运行逻辑很简单:思考→ 行动→ 观察→ 再思考。Agent 先用自然语言说明自己的推理过程,然后选择一个工具执行操作,并回收结果,基于新信息决定下一步。
举个具体场景:用户问"上季度华东区销售额同比变化多少"。Agent 的思考链可能是——"我需要先查数据库里的销售记录,按区域和时间筛选,然后计算同比"。接着调用 SQL 查询工具,拿到数据,再计算差值。整个过程,每一步推理都写在了上下文里,可以回溯审计。
ReAct 模式的核心优势是透明度。在金融、医疗这类受监管行业,"AI 做了什么决策、为什么这么做"不是可选项,而是合规要求。然而,这种透明度同样伴随着显著的性能损耗:每一步"思考"都要一次模型调用,链路越长延迟越高。一个需要 8 轮工具调用的任务,意味着至少 8 次推理,响应时间可能从秒级延长到分钟级。
Plan-and-Execute:先规划,再干活
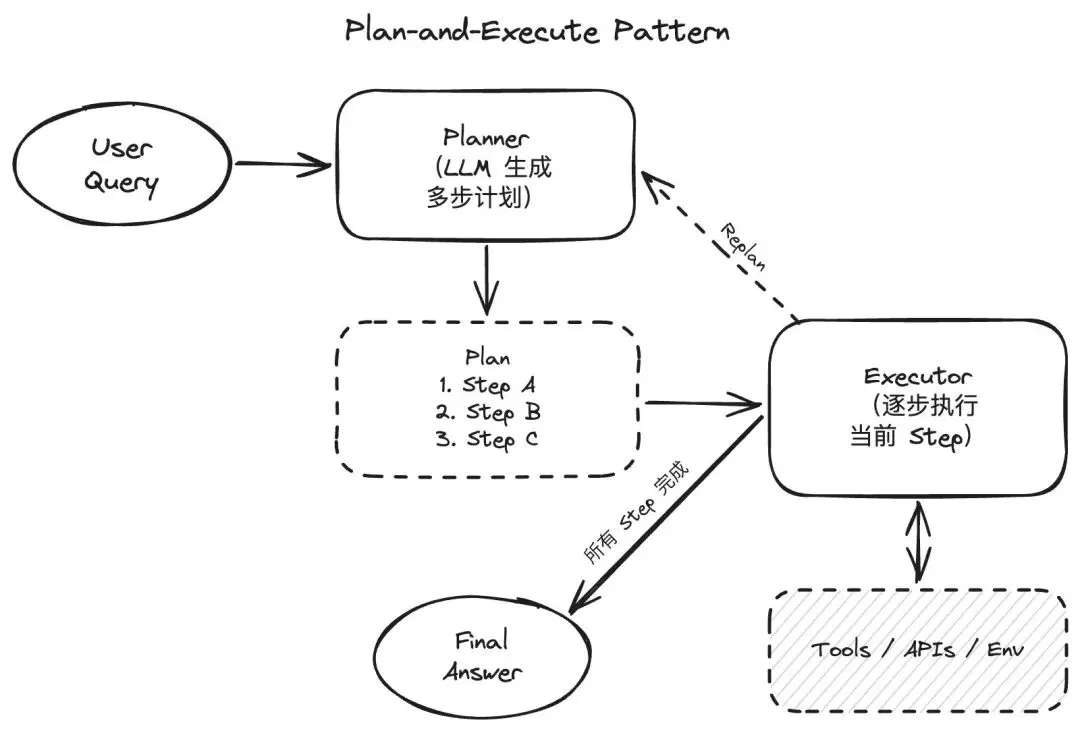
ReAct 模式的问题在于缺乏全局统筹视野。当任务涉及十几个子步骤、步骤之间有前后依赖时,Agent 很容易走弯路——先做了后面才需要的步骤,或者漏掉关键的中间环节。Plan-and-Execute 模式的做法是:先把整个任务拆解成一张有向无环图,明确哪些步骤先做、哪些可以并行,然后按计划逐步执行。
这个模式在架构上做了一个关键分离:规划用大模型,执行用小模型。规划阶段需要强推理能力,调用 GPT-5.4 级别的模型来分析任务依赖关系;执行阶段的子任务相对简单,用更小更快的模型就够了。据 n1n.ai 引用的基准测试数据,这种分离让任务完成率达到 92%,比顺序 ReAct 快 3.6 倍,成本也显著降低。
然而,Plan-and-Execute 模式也面临着固有的局限性。计划一旦生成,系统便天然倾向于"按剧本走"。如果执行过程中出现了计划时没预料到的情况——比如某个 API 突然不可用,或者中间结果和预期差异很大,系统需要一个"重新规划"机制来修正路线。
Tool Use:Agent 的手和脚
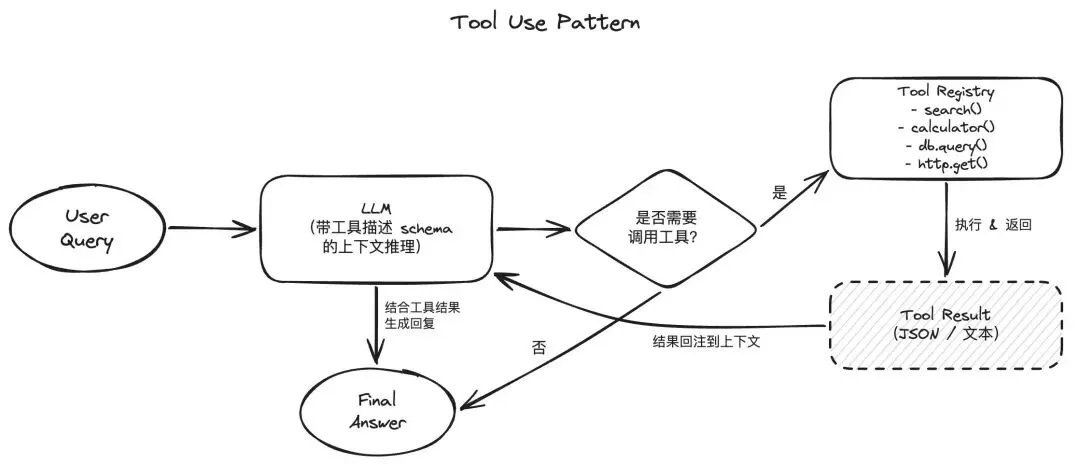
严格来说,Tool Use 不是一种独立的 Agent 模式,而是所有 Agent 都依赖的基础能力。没有工具调用,Agent 就只是一个能聊天的语言模型——能讨论天气,但不能查实时天气;能分析 SQL 语句,但不能连接数据库。
在底层机制上,Tool Use 模式的核心是大模型的函数调用(Function Calling)。这相当于开发者给 Agent 递上了一个工具箱——里面既包含读写文件、查数据库等本地操作,也装有通过 MCP(Model Context Protocol)协议标准化接入的各类外部 API。面对具体任务时,Agent 会自主评估,动态决定要从箱子里抽出哪把工具。
Tool Use 模式的价值在于打破了大模型的“信息孤岛”,使其能直接干预现实业务。但能力的延伸也伴随着脆弱性——API 限流或网络超时都可能导致运行中断。此外,工具箱绝非越满越好:过多的工具不仅剧烈消耗上下文,还会呈几何级放大模型在工具调度时的“幻觉”概率。
Reflection:让 AI 自己检查答案
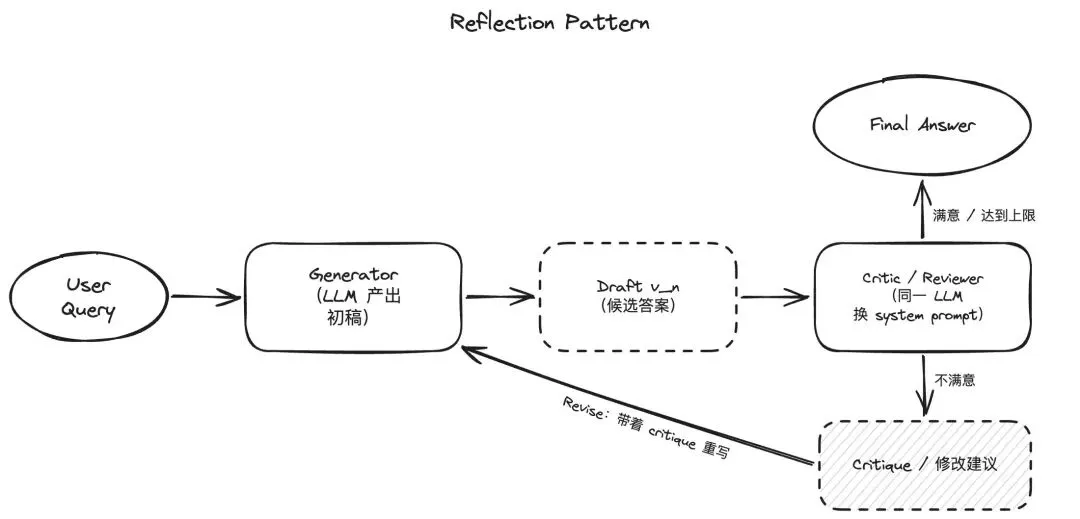
Reflection 模式的核心逻辑在于自我反思——Agent 生成初始答案后,不是直接输出,而是先自我评审一遍。具体分三步——生成初始响应、用另一个提示词或另一个模型来评审这个响应、根据评审意见重新生成。
Karpathy 在 2026 年 3 月发布的 AutoResearch 项目,是 Reflection 模式的一个标杆实践。整个系统用 630 行 Python 代码实现了一个自主机器学习实验循环:Agent 自动设计实验、运行代码、评估结果、根据失败原因调整参数,再跑一轮。据其公开的数据,仅用 2 天就完成了约 700 个 ML 实验。该项目的核心设计思路是"快速迭代优于缓慢优化"——与其花半天调一个完美参数,不如 10 分钟跑 5 个实验,让系统自己判断哪个方向有效。
Reflection 模式带来的质量增益十分显著——据 n1n.ai 披露的测试数据,它能将代码生成的准确率从 80% 提升至 91%。然而,这种“多轮博弈”的代价不仅是成倍攀升的推理延迟,更在于其工程实现上的脆弱性:系统表现极度依赖评审维度的颗粒度。如果反思指令过于宽泛,Agent 的自我审查极易流于形式,最终陷入“自圆其说”的无效消耗。
Multi-Agent:跨域协作
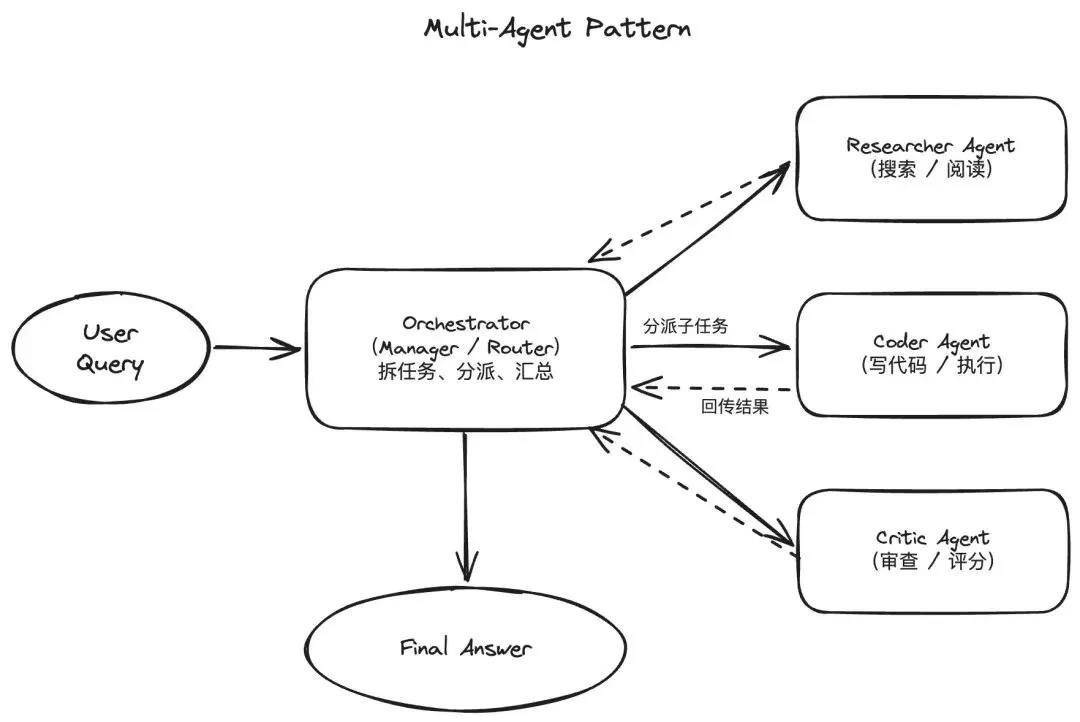
当业务复杂度突破单体 Agent 的承载极限时,Multi-Agent 模式提供了一种行之有效的解法。其核心机制在于职责解耦——将高度复杂的业务流拆解为多个子域,交由具备特定能力模型的专业 Agent 独立处理。以软件开发流水线为例,系统通常会配置负责需求理解的分析 Agent、负责代码生成的开发 Agent,以及专职质量把控的测试 Agent。
目前业界摸索出的协作拓扑大体分为三类:第一种是如同工业标准流水线般的顺序接力(Pipeline),上一个 Agent 的输出严格作为下一个的输入,适用于边界清晰的定向任务;第二种是由一个核心大脑负责调度分发的层级路由(Supervisor),主管 Agent 拆解需求、统筹多个专家节点并最终汇总产出,适合处理包含多个子模块的复合型业务;第三种则是允许多节点共享上下文的对等讨论(Joint),Agent 之间像人类开会一样自由发言、相互诘问与迭代,常用于开放性的头脑风暴或需要多方交叉验证的场景。
Multi-Agent 模式带来的工程优势是——Agent 间职责解耦、便于独立调试、支持并行提效。但这种拆分也会使系统的架构复杂度呈指数级攀升——Agent 之间如何建立通信机制?部分 Agent 崩溃时如何容错?多方输出发生冲突时以谁的决策为准?这些在单 Agent 场景下根本不存在的困扰,在多 Agent 架构中全部变成了必须专门设计的核心模块。
如何选择:模式不是越多越好
Agent 正在从实验室走向真实的业务线,这个阶段最大的陷阱就是“技术堆砌”。这 5 种模式虽然可以支持嵌套组合,但绝不意味着要把它们全套搬进同一个项目里。每多加一层架构,就意味着多付出一层延迟、算力与系统容错的成本。
真正成熟的架构设计,往往表现为极度的克制:一个常规的客服机器人,基础的 ReAct 配合 Tool Use 就已经足够;当任务被拉长到十几个步骤且相互依赖时,才有必要引入 Plan-and-Execute;当面对容错率极低的代码或文书生成时,才需要挂载 Reflection 来把控质量;而只有当业务逻辑明确跨越了不同的专业领域时,Multi-Agent 才能带来实质性的效率收益。
归根结底,在进行架构选型时,只需回答一个核心问题:"为了解决当前问题,必须引入的最小必要复杂度是什么"。只有充分理解这 5 种模式的特点,才能在面对具体问题时,快速地给出最精准、代价最小的解法。
🔗 相关资源: 5 AI Agent Design Patterns to Master by 2026(n1n.ai):https://explore.n1n.ai/blog/5-ai-agent-design-patterns-master-2026-2026-03-21 The 5 Agentic AI Design Patterns(Codebridge):https://www.codebridge.tech/articles/the-5-agentic-ai-design-patterns-ctos-should-evaluate-before-choosing-an-architecture Karpathy AutoResearch:https://github.com/karpathy/autoresearch AI Agent Design Patterns(HeyTob):https://www.heytob.com/blog/ai-agent-design-patterns-2025 |
✨ THE END ✨
