 夜雨聆风
夜雨聆风线性回归:医疗预测的精密标尺
从“找一条最优直线”到临床血压预判,打开连续值预测的黑盒
在易知AI|我们为什么需要懂AI中,我们聊到机器学习的核心能力之一就是 “预测”。那在医疗健康场景里,当健康管理师想测算 “运动 3 小时能带来多少体重变化”,或是医生想预判 “患者的血压会出现怎样的波动”,该用什么算法实现精准估算?
答案就是线性回归。它是机器学习中最简单、最经典的基础算法,更是所有复杂预测模型的 “敲门砖”,凭借易理解、可解释的特性,成为医疗领域做连续值预测的实用工具。我们在易知AI|不懂这两个模型,别说你懂AI医疗:线性回归与逻辑回归全解析已经有一定介绍,本期我们进行更为详细的介绍。
一、原理篇:找一条 “最合适” 的线
想要探究两个变量之间的关联,比如运动时长和体重变化、年龄和骨密度的关系,线性回归就能帮我们找到其中的规律。
简单来说,线性回归的核心,就是在散落的实验数据点之间,画一条最优拟合直线。这条线不是随意绘制的,它必须满足一个关键条件:所有数据点到这条直线的距离平方之和最小,这样才能最大程度贴合实际数据规律。
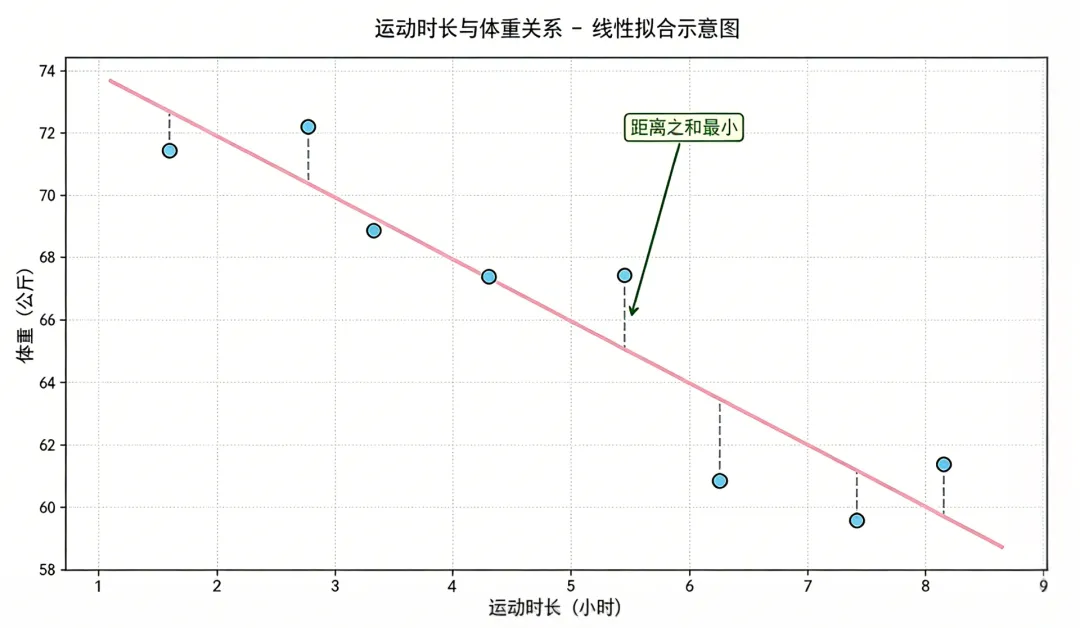
蓝点为数据样本,红线为拟合直线,垂直虚线代表残差——目标:残差平方和最小
数学公式表达:y = wx + b(y 代表预测结果,x 代表影响因素,w 权重,b 偏置)
人工智能在这个过程中,其实就是通过不断调整权重 w 和偏置 b 的数值,反复计算找到那组最优解,画出最贴合数据的直线,这个求解过程最常用的就是最小二乘法或梯度下降法。
为了衡量拟合直线的优劣,我们引入了损失函数。在线性回归中,最常用的是均方误差(MSE),也就是所有预测值与真实值差值的平方的平均值。我们的核心目标,就是让这个损失函数的数值尽可能小,数值越小,说明拟合直线的预测效果越好。
有时公式里会在均方误差前加一个 1/2,这纯粹是为了后续求导计算时消去系数,让运算更简便,并不会影响最终的求解结果。
二、梯度下降:如何一步步找到最优解?
如果面对的是少量实验数据,用最小二乘法能直接计算出解析解,快速找到最优拟合直线。但当数据量庞大时,这种方法会耗费大量时间和计算资源,这时梯度下降就成了更优选择 —— 这是一种通过迭代逐步逼近最优解的优化方法。
梯度下降的原理可以用一个很形象的场景理解:想象你站在一座山顶,想要以最快的速度走到山脚,你会先观察脚下最陡峭的下坡方向,迈出一步;到达新位置后,再次寻找当前最陡的下坡方向,继续迈步,反复如此,最终就能一步步靠近山脚。线性回归中,“山顶” 就是损失函数的最大值,“山脚” 就是损失函数的最小值,每一步的 “下坡方向” 就是梯度,通过不断迭代调整 w 和 b,就能逐步找到最优解。
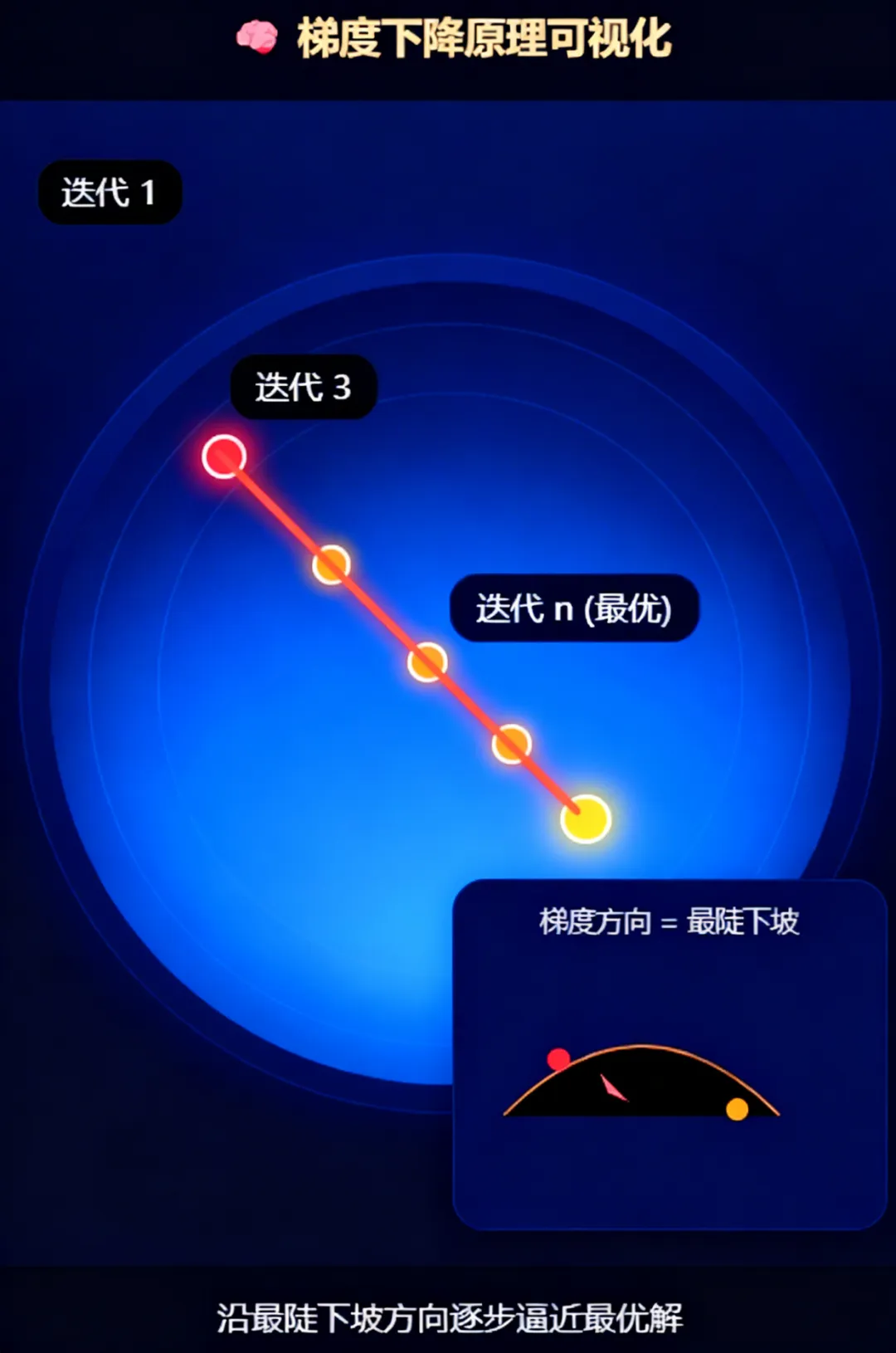
损失值随迭代次数下降,每一步沿负梯度方向更新参数,最终抵达最小值“山脚”。
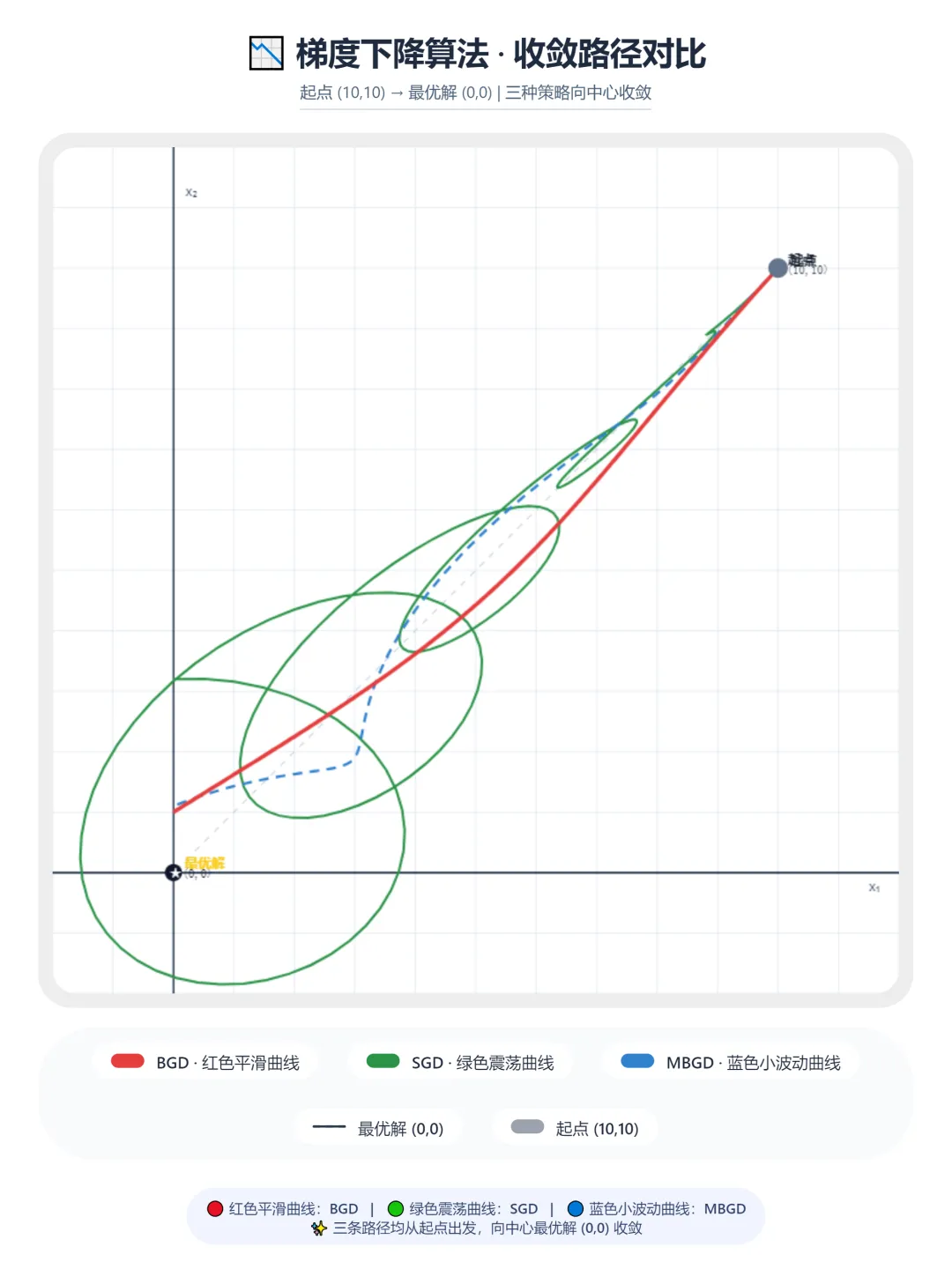
梯度下降主要有三种常见形式,各有优劣,适用于不同的数据分析场景:
批量梯度下降(BGD):每一步迭代都用所有训练样本来计算梯度。优点是计算结果精准,能找到全局最优解;缺点是数据量越大,计算量越高,耗时越久。
随机梯度下降(SGD):每一步迭代只选取一个样本计算梯度。优点是计算速度极快,适合海量数据;缺点是迭代路径容易震荡,可能在最优解附近来回波动,难以精准收敛。
小批量梯度下降(MBGD):每一步迭代选取一小批样本(比如 64 个、128 个)计算梯度。兼顾了速度和稳定性,是实际医疗数据分析、工程应用中最常用的梯度下降方法。
三、正则化:防止模型 “钻牛角尖”
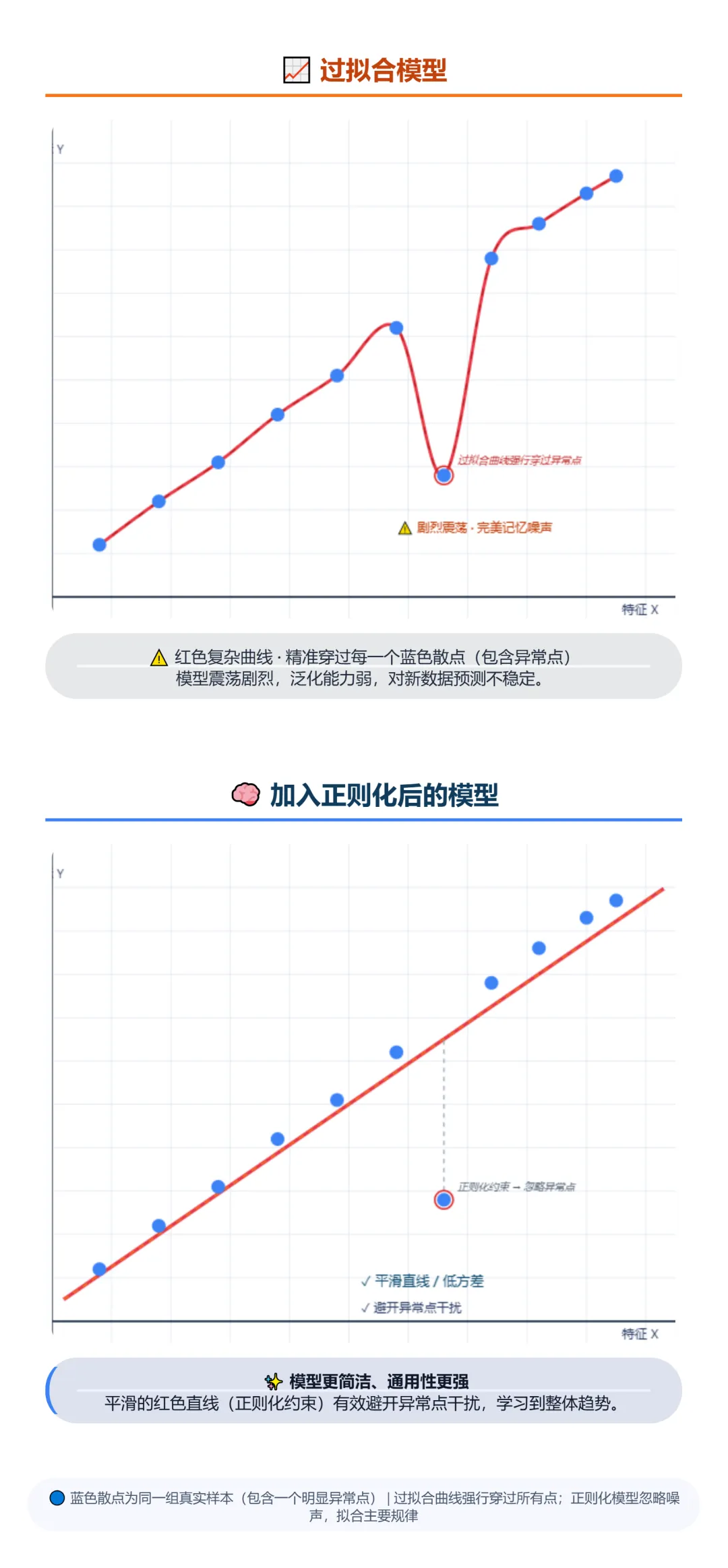
训练线性回归模型时,很容易出现一个问题:模型为了完美贴合训练数据,会过度学习数据中的细节,甚至把实验中的噪声、偶然误差也当成规律学进去,导致模型在新的未知数据上预测效果极差 —— 这就是过拟合,简单说就是模型 “学太细,钻了牛角尖”。
而正则化就是解决过拟合的重要手段,它的核心思路是在损失函数中加入一个惩罚项,通过限制权重系数的大小,约束模型的复杂度,让模型更具通用性,避免过度拟合。
线性回归中最常用的有两种正则化方式,各有侧重:
L2 正则化(Ridge 回归 / 岭回归):在损失函数中加入权重 w 的平方和作为惩罚项,会让权重尽可能小且平滑,避免某个特征对预测结果的影响过于突出,让模型更稳健。
L1 正则化(Lasso 回归 / 套索回归):在损失函数中加入权重 w 的绝对值之和作为惩罚项,会让一些对预测结果影响极小的特征权重直接变为 0,相当于自动剔除无用特征,实现特征选择,最终生成更简洁的稀疏模型。
四、评价指标:如何衡量回归模型的好坏?
我们用线性回归训练出一个预测模型后,怎么判断它的预测准不准、能不能用在实际医疗场景中?这就需要专门的评价指标来量化,线性回归最常用的有三个核心指标,相辅相成:
均方误差 (MSE)
预测值与真实值差平方的平均值,越小误差越低。
均方根误差 (RMSE)
MSE的平方根,与原始数据单位一致,更直观。
决定系数 (R²)
取值范围0~1,越接近1模型解释能力越强。
五、医疗应用案例:线性回归如何帮我们 “估算” 健康指标?
线性回归最擅长的就是连续值预测—— 比如预测血压、骨密度、血糖的具体数值,而医疗健康领域中,大量场景都需要这样的精准估算,因此线性回归也有了广泛的应用,真正做到了用算法助力临床和健康管理。
案例 A:骨密度(BMD)风险初筛发表在《Nature》子刊的一项研究中,研究者利用线性回归算法,仅通过年龄、性别、体重、腰围这些极易获取的基础指标,就构建了预测模型,能有效筛查老年人群的骨密度偏低风险。这一模型的价值在于,在去大医院做昂贵的 DXA 骨密度扫描之前,基层医疗机构就能用它快速初筛高风险人群,大幅降低筛查成本,提升老年骨健康筛查的普及率。
案例 B:维生素 D 缺乏概率预测在沙特阿拉伯等阳光充足但缺乏维生素 D 普遍检测的地区,沙特科学家利用线性回归模型,通过BMI、血压、血糖等常规体检指标,成功构建了男性维生素 D 缺乏的预测模型。研究还发现,BMI 是维生素 D 缺乏的最强预测因子,为临床维生素 D 缺乏的初筛提供了重要参考。
案例 C:血压变化趋势预判在日常健康管理场景中,我们可以收集用户的日常饮食、运动时长、睡眠质量、作息规律等数据,用线性回归模型构建个性化的血压预测模型,精准预判用户未来一段时间的血压变化趋势,一旦发现血压有异常升高的苗头,就能提前发出健康预警,让用户及时调整生活方式或就医干预。
骨密度风险初筛
年龄+性别+体重等基础指标,降低DXA筛查门槛
维生素D缺乏预测
BMI、血压、血糖,最强预测因子BMI
血压趋势预判
运动/睡眠/饮食数据预警异常波动
更多场景
血糖预测 · 体重变化测算 · 住院时长预估
强可解释性助力临床决策,连续值预测基石
易知AI · 用可解释的AI照亮医疗未来
