 夜雨聆风
夜雨聆风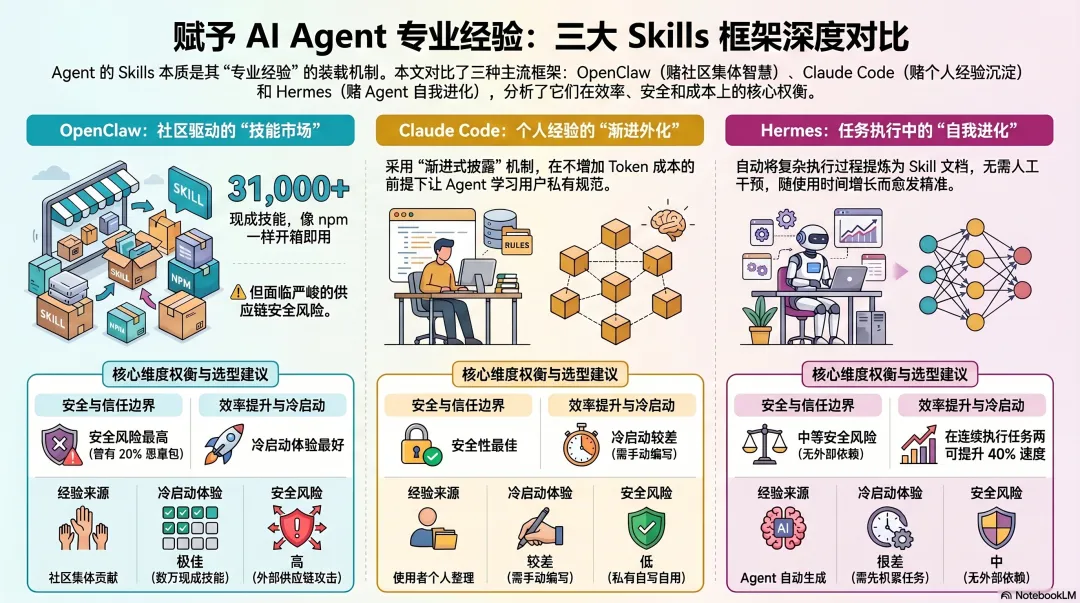
系列:AI Agent 架构设计(七):Skills 系统设计
目标:理解 Skills 的本质,以及三个框架在"经验从哪来"这个问题上的根本分歧
适合:对 Agent 底层设计感兴趣,想真正理解"为什么这样设计"的读者
预计阅读:15 分钟
Skills 的本质:Agent 的专业经验
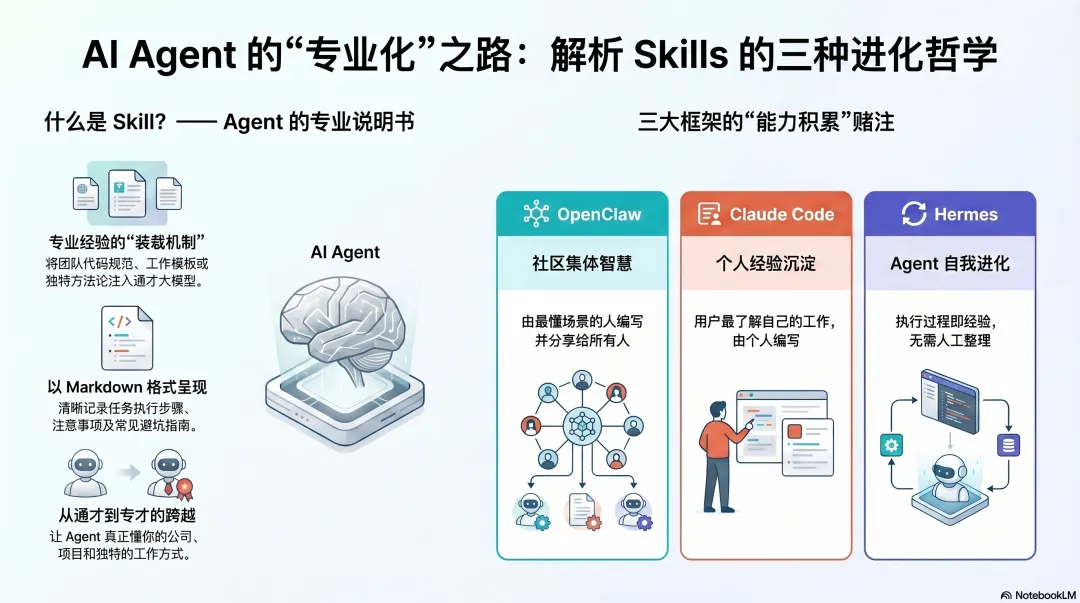
语言模型是通才。它懂很多,但不懂你的公司、你的项目、你的工作方式。
你想让 Agent 按你团队的代码规范写代码,按你的模板写周报,用你摸索出来的方法处理某类任务——这些都需要把你的专业经验"装进"Agent。
Skills 就是这个装载机制。
一个 Skill 的格式很简单:一个 Markdown 文件,写清楚这件事该怎么做、注意什么、常见坑在哪里。Agent 需要时加载进来,按照这份说明书工作。
但这里藏着一个关键问题:
这份说明书,应该从哪里来?
这不是一个技术问题,而是一个关于"Agent 应该如何积累专业能力"的根本判断。三个框架赌的是三件完全不同的事:
- OpenClaw 赌社区集体智慧
——让最懂每个场景的人写出最好的 Skill,分享给所有人 - Claude Code 赌个人经验沉淀
——你最了解自己的工作,你写的 Skill 最准确 - Hermes 赌 Agent 能自我进化
——执行过程本身就是最好的经验来源,为什么要人来整理
这三种赌注,决定了三个框架在 Skills 生态上的一切设计选择。
OpenClaw:赌社区集体智慧
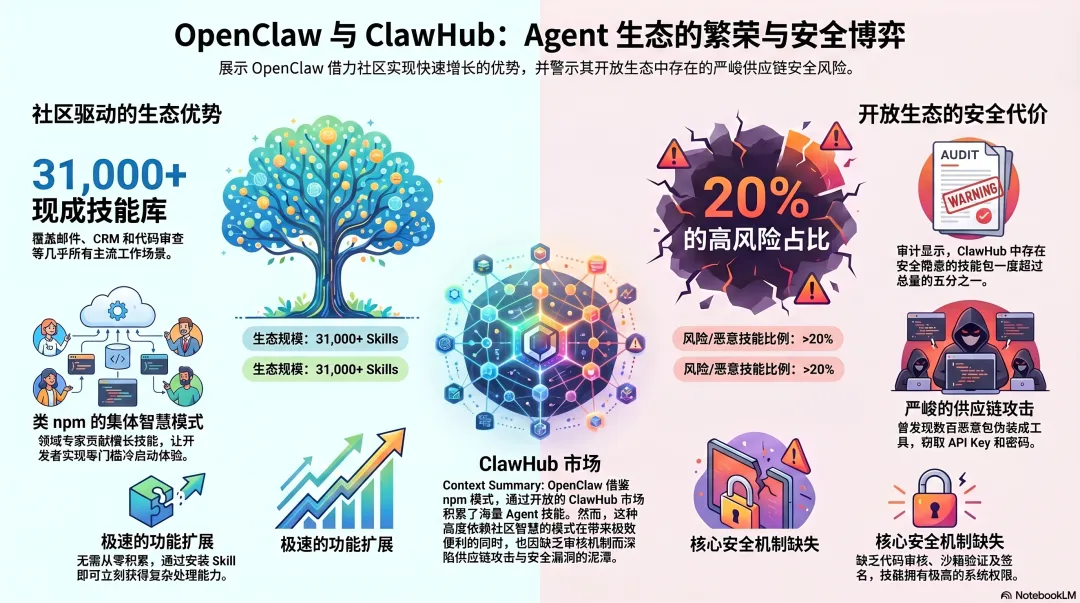
ClawHub:Agent 界的 npm
OpenClaw 的 Skills 来自 ClawHub——一个开放的技能市场。任何人发布,任何人安装。
规模已经相当大:超过 31,000 个 Skills,覆盖邮件处理、CRM 管理、代码审查、数据分析……你能想到的工作场景,基本都有现成的 Skill 可以安装。
这个逻辑和 npm 一样:让社区里最懂某个场景的人来写这个场景的 Skill。 懂 GitHub 的工程师写 GitHub Skill,懂 Notion 的产品经理写 Notion Skill,每个人贡献自己最擅长的部分,所有人从中受益。
冷启动体验是三个框架里最好的——装上 OpenClaw,立刻有数万个 Skills 可用,不需要自己从零积累。
社区赌注的代价:供应链攻击
开放生态有开放生态的代价。
2026 年 1 月,安全研究人员发现 ClawHub 上出现了大规模恶意 Skill——341 个伪装成正常工具的恶意包,植入了键盘记录器和信息窃取木马,专门针对 OAuth Token、API Key 和浏览器密码。后续审计发现恶意或有安全隐患的 Skill 一度超过总量的 20%。
这不是小问题。安装一个 ClawHub Skill,本质上是在你的机器上执行陌生人写的代码,而这段代码拥有和 OpenClaw 本身完全相同的系统权限。
ClawHub 没有强制性的代码审核:任何人只要有一个超过一周的 GitHub 账号就可以发布,没有代码签名,没有沙箱验证,没有安全扫描。
当你把"经验来源"交给开放社区,你同时也把"信任边界"交了出去。 这是赌社区智慧必须付出的代价,也是 OpenClaw 在企业环境里始终面临的核心安全挑战。
Claude Code:赌个人经验沉淀
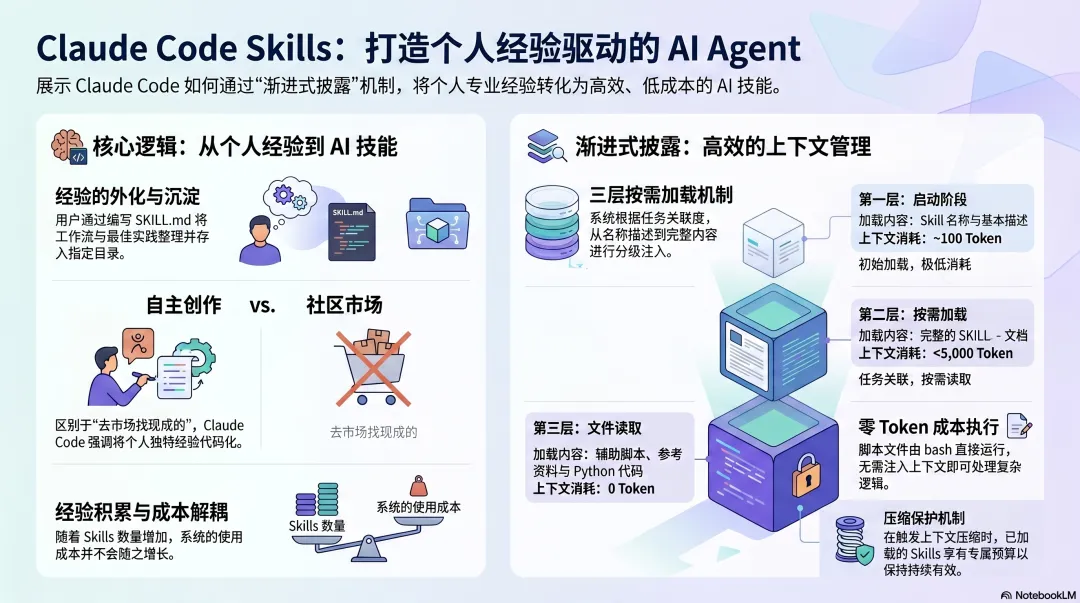
Skills 的来源:你自己写
Claude Code 的 Skills 主要由使用者自己创作——你把自己的工作流程、规范、最佳实践整理成 SKILL.md,放进 .claude/skills/ 目录,Agent 自动发现并加载。
Anthropic 提供了一批官方 Skills(PDF 处理、文档编辑等),社区也有大量开源 Skill 库,但核心逻辑是:Skills 是你的专业经验的外化,你写什么,Agent 就学什么。
这和 OpenClaw 的社区市场形成对比。OpenClaw 是"去市场找现成的",Claude Code 更强调"把自己的经验整理出来"。
代价是门槛:你需要花时间写,需要懂得怎么写好一份 Skill,对非技术用户不够友好。
渐进式披露:经验越多,成本越低
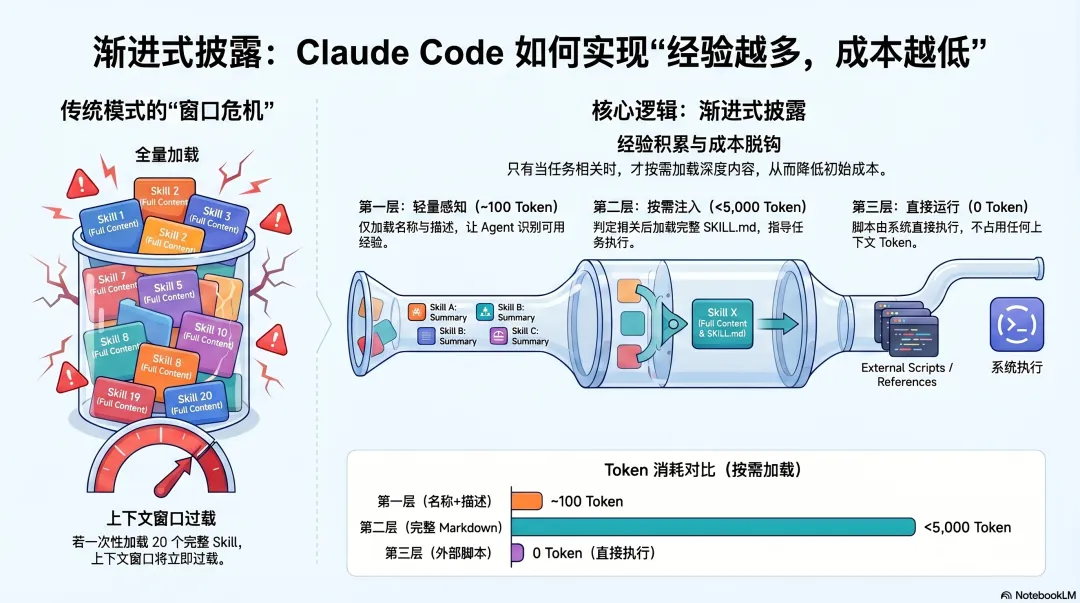
Claude Code 解决了一个实际难题:如果你写了 20 个 Skills,每次 Session 都把所有 Skills 的完整内容塞进上下文,窗口立刻就满了。
解法是渐进式披露(Progressive Disclosure)——Skills 的加载分三层:
第一层(启动时,~100 Token)每个 Skill 只加载名称 + 描述Agent 知道"有哪些经验可用" ↓ 判断当前任务相关第二层(按需加载,<5,000 Token)完整 SKILL.md 内容加载Agent 按照说明执行任务 ↓ 执行时按需引用第三层(文件系统直接读取,0 Token)辅助文件、参考资料、可执行脚本不注入上下文,直接运行
第三层有一个值得关注的设计:scripts/ 里的代码不注入上下文,Claude 直接用 bash 执行。 这意味着一个 Skill 可以附带几千行 Python 代码,却对 Token 成本没有任何影响——LLM 根本不用"读"这些代码,直接跑。
所以 Claude Code 的 Skill 内容实际上几乎无上限:完整的 API 文档、几百行的处理脚本、大量的参考模板,全部可以打包进一个 Skill,Agent 只在真正需要时才加载,其他时候对上下文成本没有影响。
这解决了一个核心矛盾:你积累的个人经验越多,Skills 越丰富,使用成本却不随之增长。
Compaction 后 Skills 的持续性
上下文满了会触发 Compaction(压缩)。Claude Code 对此有专门保护:压缩时,当前已加载的 Skills 会重新附加到压缩后的上下文,每个 Skill 保留前 5,000 Token,所有 Skills 共享 25,000 Token 的预算。
Skills 里的规则和约束在整个任务周期内持续有效——你花时间写进 Skill 的经验,不会因为会话变长而消失。
Hermes Agent:赌 Agent 能自我进化
颠覆前提:经验为什么要人来写
OpenClaw 和 Claude Code 有一个共同假设:Skills 由人来写。
Hermes Agent 挑战了这个假设:如果 Agent 执行任务的过程本身就是最好的经验来源,为什么还需要人来整理?
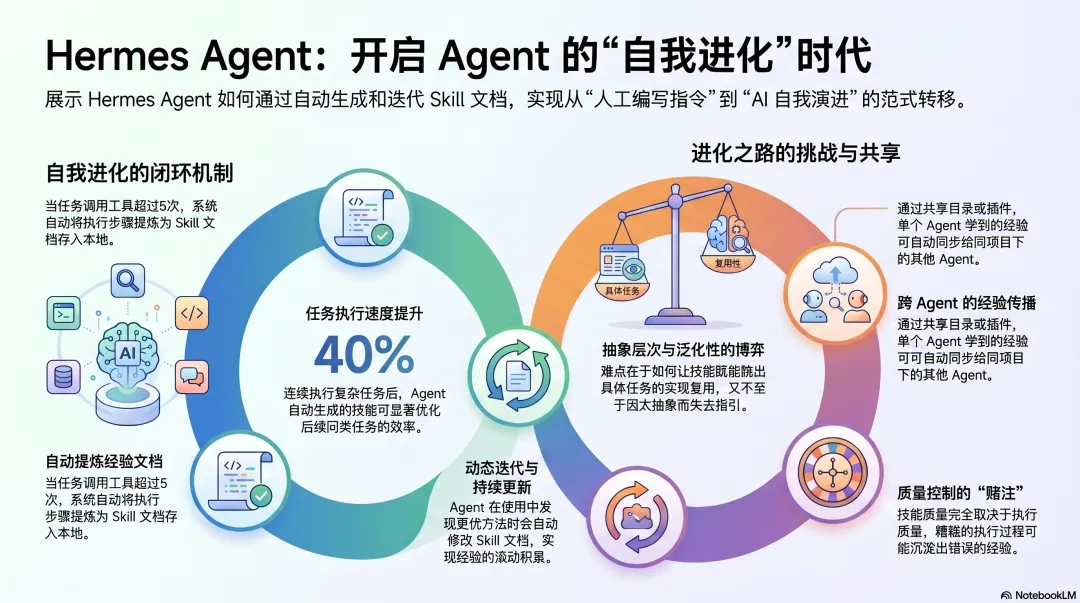
Hermes Agent 的做法:当 Agent 完成一个复杂任务(通常是 5 次以上工具调用),系统自动把这次执行过程提炼成一份 Skill 文档——步骤、工具选择、遇到的问题、解决方法——写进 ~/.hermes/skills/。
下次遇到类似任务,自动加载这份 Skill,不用从头摸索。
更关键的是:Skill 在使用中自我更新。 Agent 发现更好的方法,自动修改 Skill 文档。经验在积累,方法在迭代。
有用户测试:装好 Hermes,连续执行几个复杂任务,两小时内 Agent 自动生成了三份 Skill,再跑类似任务的速度提升 40%。全程没有人工干预。
这个赌注难在哪里?
Agent 自动生成 Skill 的难点不是技术,是判断。
什么任务值得生成 Skill? Hermes 用"5 次以上工具调用"作为启发式规则。简单直接,但不精确——有些两步任务其实很值得沉淀,有些十步任务每次情况都不同,生成的 Skill 泛化性很差。
抽象的层次在哪里? 做了一件具体的事,怎么提炼成下次可以复用的通用方法?太具体,下次遇到稍微不同的任务就用不上;太抽象,执行时没有足够的操作指引。
质量谁来把关? Hermes 目前没有内置的 Skill 质量评估机制,质量完全取决于生成时那次任务的执行质量。好的执行生成好的 Skill,糟糕的执行可能沉淀出错误的"经验"。
这是 Hermes 这个赌注最大的风险:自我进化的前提,是每次执行都足够好。
Skills 的共享:跨 Agent 的经验传播
Hermes 的 Skills 默认是单个 Agent 私有的。但放进共享目录 ~/.hermes/skills/ 的 Skills,同一台机器上的所有 Agent 都能读取。
PLUR 社区插件更进一步——对一个 Agent 的纠正会自动传播给同项目的其他 Agent。一个 Agent 学到的,其他 Agent 也学到了。
三种赌注,三种取舍
没有哪种赌注是绝对正确的。
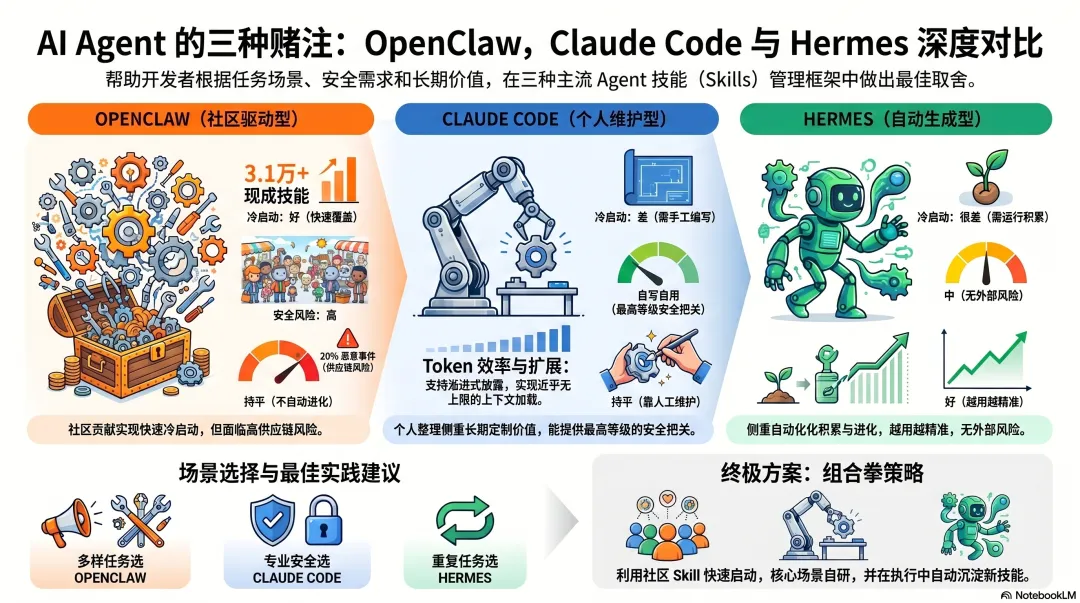
你的任务类型多样,需要快速覆盖各种场景 → OpenClaw 的社区生态是最快的路径,但要认真审查每一个安装的 Skill。
你有特定的专业场景,对质量和安全要求高 → 自己写 SKILL.md,Claude Code 的渐进式披露让你可以写得很详细而不担心成本。
你的任务类型固定且重复,愿意让 Agent 慢慢学 → Hermes,时间越长,积累越多,执行越准。
最成熟的做法是组合:用社区 Skills 快速启动,用自己写的 Skills 覆盖核心场景,让 Agent 在使用中自动沉淀新 Skills。Skills 的格式已经走向开放标准(agentskills.io),三个框架之间的 Skills 可以互相复用——这让跨框架组合成为可能。
系列:AI Agent 架构设计(七):Skills 系统设计
目标:理解 Skills 的本质,以及三个框架在"经验从哪来"这个问题上的根本分歧
适合:对 Agent 底层设计感兴趣,想真正理解"为什么这样设计"的读者
预计阅读:15 分钟
系列:AI Agent 架构设计(七):Skills 系统设计
目标:理解 Skills 的本质,以及三个框架在"经验从哪来"这个问题上的根本分歧
适合:对 Agent 底层设计感兴趣,想真正理解"为什么这样设计"的读者
预计阅读:15 分钟
Skills 的本质:Agent 的专业经验
语言模型是通才。它懂很多,但不懂你的公司、你的项目、你的工作方式。
你想让 Agent 按你团队的代码规范写代码,按你的模板写周报,用你摸索出来的方法处理某类任务——这些都需要把你的专业经验"装进"Agent。
Skills 就是这个装载机制。
一个 Skill 的格式很简单:一个 Markdown 文件,写清楚这件事该怎么做、注意什么、常见坑在哪里。Agent 需要时加载进来,按照这份说明书工作。
但这里藏着一个关键问题:
这份说明书,应该从哪里来?
这不是一个技术问题,而是一个关于"Agent 应该如何积累专业能力"的根本判断。三个框架赌的是三件完全不同的事:
- OpenClaw 赌社区集体智慧
——让最懂每个场景的人写出最好的 Skill,分享给所有人 - Claude Code 赌个人经验沉淀
——你最了解自己的工作,你写的 Skill 最准确 - Hermes 赌 Agent 能自我进化
——执行过程本身就是最好的经验来源,为什么要人来整理
这三种赌注,决定了三个框架在 Skills 生态上的一切设计选择。
OpenClaw:赌社区集体智慧
ClawHub:Agent 界的 npm
OpenClaw 的 Skills 来自 ClawHub——一个开放的技能市场。任何人发布,任何人安装。
规模已经相当大:超过 31,000 个 Skills,覆盖邮件处理、CRM 管理、代码审查、数据分析……你能想到的工作场景,基本都有现成的 Skill 可以安装。
这个逻辑和 npm 一样:让社区里最懂某个场景的人来写这个场景的 Skill。 懂 GitHub 的工程师写 GitHub Skill,懂 Notion 的产品经理写 Notion Skill,每个人贡献自己最擅长的部分,所有人从中受益。
冷启动体验是三个框架里最好的——装上 OpenClaw,立刻有数万个 Skills 可用,不需要自己从零积累。
社区赌注的代价:供应链攻击
开放生态有开放生态的代价。
2026 年 1 月,安全研究人员发现 ClawHub 上出现了大规模恶意 Skill——341 个伪装成正常工具的恶意包,植入了键盘记录器和信息窃取木马,专门针对 OAuth Token、API Key 和浏览器密码。后续审计发现恶意或有安全隐患的 Skill 一度超过总量的 20%。
这不是小问题。安装一个 ClawHub Skill,本质上是在你的机器上执行陌生人写的代码,而这段代码拥有和 OpenClaw 本身完全相同的系统权限。
ClawHub 没有强制性的代码审核:任何人只要有一个超过一周的 GitHub 账号就可以发布,没有代码签名,没有沙箱验证,没有安全扫描。
当你把"经验来源"交给开放社区,你同时也把"信任边界"交了出去。 这是赌社区智慧必须付出的代价,也是 OpenClaw 在企业环境里始终面临的核心安全挑战。
Claude Code:赌个人经验沉淀
Skills 的来源:你自己写
Claude Code 的 Skills 主要由使用者自己创作——你把自己的工作流程、规范、最佳实践整理成 SKILL.md,放进 .claude/skills/ 目录,Agent 自动发现并加载。
Anthropic 提供了一批官方 Skills(PDF 处理、文档编辑等),社区也有大量开源 Skill 库,但核心逻辑是:Skills 是你的专业经验的外化,你写什么,Agent 就学什么。
这和 OpenClaw 的社区市场形成对比。OpenClaw 是"去市场找现成的",Claude Code 更强调"把自己的经验整理出来"。
代价是门槛:你需要花时间写,需要懂得怎么写好一份 Skill,对非技术用户不够友好。
渐进式披露:经验越多,成本越低
Claude Code 解决了一个实际难题:如果你写了 20 个 Skills,每次 Session 都把所有 Skills 的完整内容塞进上下文,窗口立刻就满了。
解法是渐进式披露(Progressive Disclosure)——Skills 的加载分三层:
第一层(启动时,~100 Token)每个 Skill 只加载名称 + 描述Agent 知道"有哪些经验可用"↓ 判断当前任务相关第二层(按需加载,<5,000 Token)完整 SKILL.md 内容加载Agent 按照说明执行任务↓ 执行时按需引用第三层(文件系统直接读取,0 Token)辅助文件、参考资料、可执行脚本不注入上下文,直接运行
第三层有一个值得关注的设计:scripts/ 里的代码不注入上下文,Claude 直接用 bash 执行。 这意味着一个 Skill 可以附带几千行 Python 代码,却对 Token 成本没有任何影响——LLM 根本不用"读"这些代码,直接跑。
所以 Claude Code 的 Skill 内容实际上几乎无上限:完整的 API 文档、几百行的处理脚本、大量的参考模板,全部可以打包进一个 Skill,Agent 只在真正需要时才加载,其他时候对上下文成本没有影响。
这解决了一个核心矛盾:你积累的个人经验越多,Skills 越丰富,使用成本却不随之增长。
Compaction 后 Skills 的持续性
上下文满了会触发 Compaction(压缩)。Claude Code 对此有专门保护:压缩时,当前已加载的 Skills 会重新附加到压缩后的上下文,每个 Skill 保留前 5,000 Token,所有 Skills 共享 25,000 Token 的预算。
Skills 里的规则和约束在整个任务周期内持续有效——你花时间写进 Skill 的经验,不会因为会话变长而消失。
Hermes Agent:赌 Agent 能自我进化
颠覆前提:经验为什么要人来写
OpenClaw 和 Claude Code 有一个共同假设:Skills 由人来写。
Hermes Agent 挑战了这个假设:如果 Agent 执行任务的过程本身就是最好的经验来源,为什么还需要人来整理?
Hermes Agent 的做法:当 Agent 完成一个复杂任务(通常是 5 次以上工具调用),系统自动把这次执行过程提炼成一份 Skill 文档——步骤、工具选择、遇到的问题、解决方法——写进 ~/.hermes/skills/。
下次遇到类似任务,自动加载这份 Skill,不用从头摸索。
更关键的是:Skill 在使用中自我更新。 Agent 发现更好的方法,自动修改 Skill 文档。经验在积累,方法在迭代。
有用户测试:装好 Hermes,连续执行几个复杂任务,两小时内 Agent 自动生成了三份 Skill,再跑类似任务的速度提升 40%。全程没有人工干预。
这个赌注难在哪里?
Agent 自动生成 Skill 的难点不是技术,是判断。
什么任务值得生成 Skill? Hermes 用"5 次以上工具调用"作为启发式规则。简单直接,但不精确——有些两步任务其实很值得沉淀,有些十步任务每次情况都不同,生成的 Skill 泛化性很差。
抽象的层次在哪里? 做了一件具体的事,怎么提炼成下次可以复用的通用方法?太具体,下次遇到稍微不同的任务就用不上;太抽象,执行时没有足够的操作指引。
质量谁来把关? Hermes 目前没有内置的 Skill 质量评估机制,质量完全取决于生成时那次任务的执行质量。好的执行生成好的 Skill,糟糕的执行可能沉淀出错误的"经验"。
这是 Hermes 这个赌注最大的风险:自我进化的前提,是每次执行都足够好。
Skills 的共享:跨 Agent 的经验传播
Hermes 的 Skills 默认是单个 Agent 私有的。但放进共享目录 ~/.hermes/skills/ 的 Skills,同一台机器上的所有 Agent 都能读取。
PLUR 社区插件更进一步——对一个 Agent 的纠正会自动传播给同项目的其他 Agent。一个 Agent 学到的,其他 Agent 也学到了。
三种赌注,三种取舍
没有哪种赌注是绝对正确的。
你的任务类型多样,需要快速覆盖各种场景 → OpenClaw 的社区生态是最快的路径,但要认真审查每一个安装的 Skill。
你有特定的专业场景,对质量和安全要求高 → 自己写 SKILL.md,Claude Code 的渐进式披露让你可以写得很详细而不担心成本。
你的任务类型固定且重复,愿意让 Agent 慢慢学 → Hermes,时间越长,积累越多,执行越准。
最成熟的做法是组合:用社区 Skills 快速启动,用自己写的 Skills 覆盖核心场景,让 Agent 在使用中自动沉淀新 Skills。Skills 的格式已经走向开放标准(agentskills.io),三个框架之间的 Skills 可以互相复用——这让跨框架组合成为可能。
