 夜雨聆风
夜雨聆风全网最全的AI科研工具介绍推荐
想认真做 AI 研究,最怕的不是你不够努力,而是工具链太散。
你今天在 arXiv 刷论文,明天在 Google Scholar 追引用,后天又在群里问“这个会什么时候截稿”。真正拖慢 AI 科研进度的,很多时候不是研究本身,而是信息、阅读、实验、写作、投稿这些环节压根没串成一条顺手的链。
我越来越相信,AI 科研效率不是靠某一个“神奇工具”突然翻倍,而是先把整条研究工作流搭起来。你得知道去哪里看前沿趋势,去哪里找 AI 论文,怎么快速判断值不值得读,怎么把实验留下证据,最后怎么把东西写出来、投出去。
这篇我不打算做“工具名称大拼盘”。我更想按真实的 AI 科研链路来梳理。无论你是在校做 AI 相关课题、准备保研考博、刚入组读硕博,还是已经工作但需要持续追踪某个 AI 方向,这一套都值得你挨个试一遍。
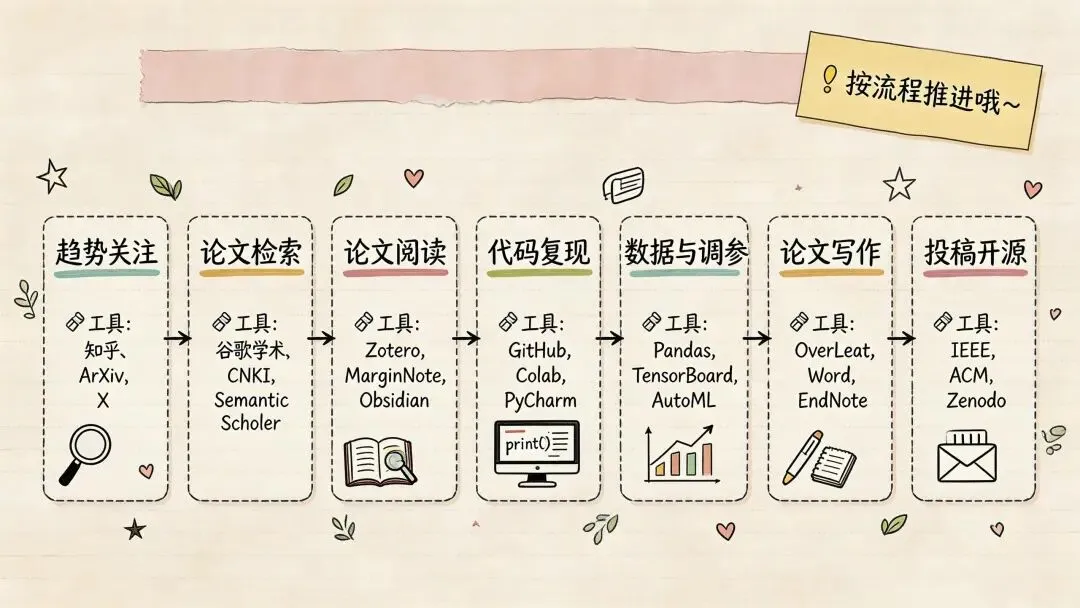
先定一条主线
先给我的判断。
深度用熟 8 个核心工具,价值远大于浅尝 50 个“收藏夹工具”。
AI 科研工具不是越多越好。你真正需要的是一条稳定链路:
• 趋势关注:别错过方向变化 • 论文检索:别在找文献这一步卡住 • 阅读管理:别让论文下了就吃灰 • 编码实验:别让实验结果无法复现 • 写作投稿:别把最后 20% 的收尾拖成最大阻塞
如果你现在时间不多,只想先抄一套最低可用配置,我会建议你先装这几个:
• 趋势: irreader+Paper Digest• 检索: dblp+Semantic Scholar• 代码: Papers With Code• 管理: Zotero或Mendeley• 精读: Kimi Chat+CopyTranslator• 写作: Overleaf或VSCode + LaTeX Workshop
先把这套跑顺,再去加别的。
趋势怎么追
做研究最怕“后知后觉”。
尤其是 AI 方向,顶会、实验室主页、个人博客、arXiv 预印本都在同时更新。你如果只靠手动刷网页,迟早会漏掉真正关键的突破。
irreader:把“没有 RSS 的网站”也变成可追踪信号
• 地址: https://irreader.fatecore.com/• 解决什么问题:很多高校实验室主页、研究者个人主页、行业博客根本没有官方 RSS,普通阅读器订不了 • 核心能力:自定义 RSS 生成,直接对目标网页做元素拾取,把更新内容转成专属订阅源 • 适合场景:盯顶会动态页、盯某位老师主页、盯实验室新闻、盯技术博客
我现在主力用的 RSS 阅读器就是它,已经把 Feedly、Inoreader 这类工具替下来了。原因很简单,科研追踪最稀缺的能力不是“读 RSS”,而是“给没有 RSS 的站点造 RSS”。 这一点它做得特别实用。
更关键的是,它对国内用户很友好。大部分功能不需要额外折腾网络环境,拿来就能用。
Paper Digest:把海量 arXiv 更新先压缩成一份可读清单
• 地址: https://www.paperdigest.org/• 解决什么问题: arXiv每天更新太多,人工刷一遍成本很高• 核心能力:按领域邮件推送最新论文,并给每篇配一句 AI 摘要 • 适合场景:每天 10 分钟扫一眼,先决定今天该点开哪几篇
它特别适合做“第一层过滤”。你不需要一上来就把 PDF 全下下来。先看摘要、看标签、看有没有顶会论文的集中整理,再决定往下走。
arXiv-sanity:刷 arXiv 的效率版入口
• 地址: https://arxiv-sanity-lite.com/• 仓库: karpathy/arxiv-sanity-lite• 解决什么问题:原生 arXiv的检索和浏览效率,说实话不高• 核心能力:摘要直接展开、评论、收藏、推荐、个人文献库 • 适合场景:按研究方向日刷新论文,快速判断哪些值得进入精读队列
平时刷 arXiv 更常走这个入口,而不是原站。浏览成本差得很明显。原生 arXiv 更像一个论文仓库,arXiv-sanity 才更像一个研究人员真的会每天打开的工作台。
Semantic Sanity:让推荐系统替你缩小范围
• 地址: https://s2-sanity.apps.allenai.org/• 解决什么问题:研究方向越细,关键词搜索越不够用 • 核心能力:先喂 3 到 5 篇种子论文,再基于你的偏好持续推荐相关预印本 • 适合场景:你已经有初始方向,但还没稳定形成自己的跟踪列表
这个工具特别适合刚进组、刚切方向的时候。你未必知道完整关键词,但你知道“我想看和这几篇像的东西”。那它就有用了。
论文去哪里找
很多人找论文的路径其实过于单一,默认只用 Google Scholar。这当然能用,但不够快,也不够干净。
我的建议是,把论文检索拆成三个任务:找论文本身、追引用关系、找代码实现。不同任务,入口不一样。
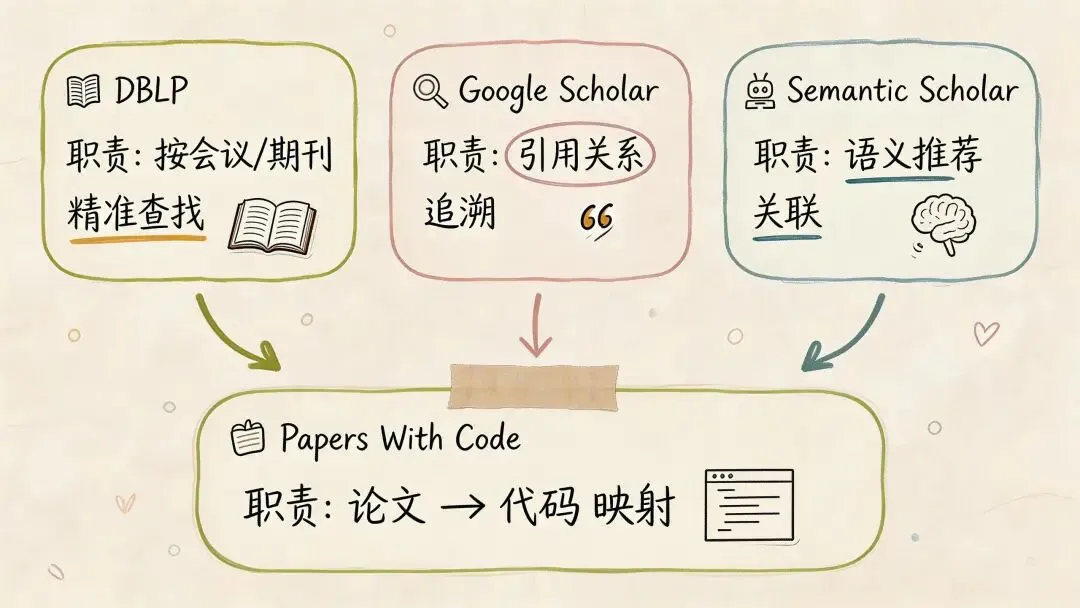
dblp:算机论文检索的干净主入口
• 地址: https://dblp.org/• 解决什么问题:你需要按会议、期刊、作者精确找到论文,不想被杂乱结果打断 • 核心能力:覆盖计算机领域主流会议和期刊,支持按会议名、作者、标题、DOI 精确检索 • 适合场景:批量找 CVPR 2025、NeurIPS 2025的论文;查一个作者这些年完整发表记录;定位论文官方 PDF
我找 CS 论文 PDF 的第一站通常就是它。检索结果非常干净,几乎没有多余噪音。尤其是你要批量看某个会议整年的论文列表时,dblp 比 Google Scholar 省事太多。
Google Scholar:引用链路最强,但别拿它当唯一入口
• 地址: https://scholar.google.com/• 解决什么问题:你想知道一篇论文影响力怎样、后续谁在跟、它引用了谁 • 核心能力:被引、参考文献、相关论文、作者关注、关键词提醒 • 适合场景:顺着一篇经典论文向前追祖先,向后追分支
我更愿意把它理解成“引用关系图谱”,而不是“第一搜索框”。dblp 没覆盖到的特殊文献、跨学科结果、被引网络,这时候它就很强。
Semantic Scholar:当关键词已经不够用的时候
• 地址: https://www.semanticscholar.org/• 解决什么问题:你知道自己想找“类似工作”,但你未必知道该输什么词 • 核心能力:语义检索、TLDR、一句话结论、相关视频和代码补充 • 适合场景:快速扫领域代表性工作,找关键词没覆盖到的相关研究
它的 TLDR 很适合做第一轮判断。不是为了替你读论文,而是为了帮你先淘汰一批不值得点开的。
arXiv:前沿论文最原始的水位线
• 地址: https://arxiv.org/• 解决什么问题:正式发表之前,很多重要工作最早就出现在这里 • 核心能力:预印本首发 • 适合场景:追最新方向、追尚未定稿但已经值得关注的工作
如果你做的是变化很快的方向,不看 arXiv 基本等于放弃最早的信号源。
Papers With Code:论文和代码之间最关键的桥
• 地址: https://paperswithcode.com/• 解决什么问题:论文找到了,但官方实现、第三方实现、数据集、指标到底在哪 • 核心能力:论文和 GitHub 仓库、任务榜单、数据集、指标体系的映射 • 适合场景:找可复现实现、看某任务当前 SOTA、比较不同模型成绩
这基本是我找论文代码的首选入口。它最有价值的地方,不只是“给你一个仓库链接”,而是把任务、数据集、指标和实现放到同一条链上。
研究里最浪费时间的事之一,就是拿到一篇论文后,自己去猜它的官方代码到底在哪、评测口径是不是同一套。Papers With Code 在很大程度上把这件事标准化了。
labml Annotated Implementations:看懂经典论文代码的好地方
• 地址: labmlai/annotated_deep_learning_paper_implementations• 配套站点: https://nn.labml.ai/• 解决什么问题:很多论文代码能跑,但并不好读 • 核心能力:经典深度学习论文的 PyTorch 实现 + 逐行注释 • 适合场景:学习 Transformer、GAN、扩散模型、强化学习这类经典结构时,对照原理论文看实现
我对这个仓库的评价是:很适合学习“核心思路怎么落成代码”,但别把它当作完全从零、零依赖的原教旨复现。部分底层逻辑挂在它自家的包里,真要完整复现,你还是得把依赖链补齐。
论文怎么读
下载 PDF 只是开始。真正拉开效率差距的,是你能不能快速判断“这篇该浅读、深读,还是直接跳过”。
SCI-Hub:处理付费论文获取问题
• 地址: https://sci-hub.se/• 解决什么问题:部分论文有付费墙,学校权限也不一定全覆盖 • 核心能力:按标题、DOI、链接获取全文 • 适合场景:补老论文、补非开放获取文献
这类工具的争议和版权边界一直都在,合规问题你得自己判断清楚。如果学校图书馆、机构资源、作者主页已经能拿到,当然优先走正式渠道。
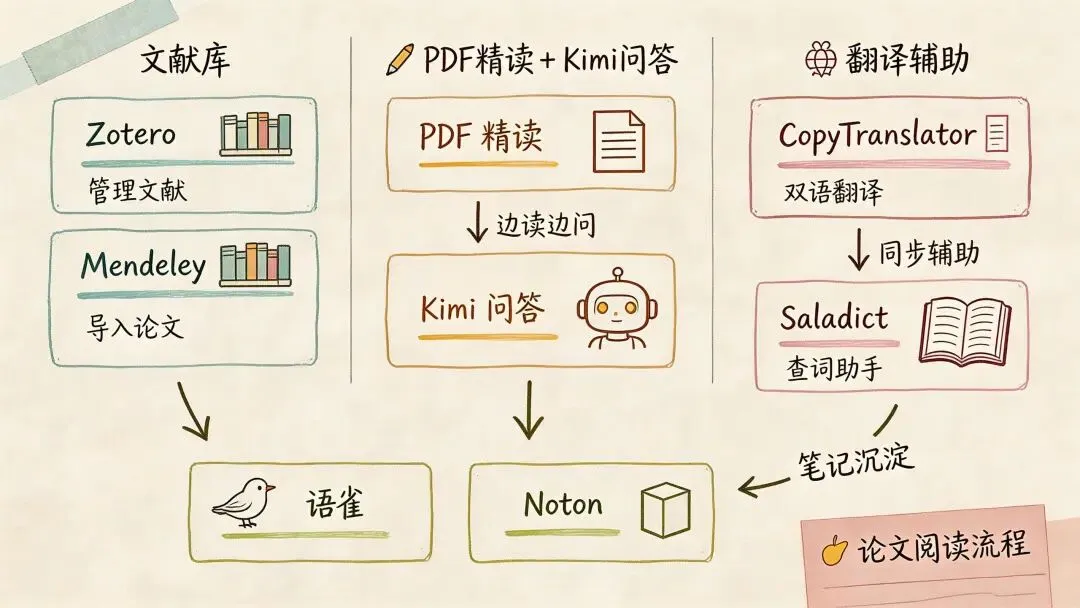
Zotero 和 Mendeley:别把文献管理做成“下载文件夹地狱”
先说结论。
如果你想要开源、插件多、可定制,选 Zotero。如果你想少折腾、跨端同步稳、直接上手,选 Mendeley。
Mendeley
• 地址: https://www.mendeley.com/• 适合谁:想快速建立稳定文献库的新手 • 核心能力:PDF 阅读、批注、高亮、多端同步、参考文献格式导出
我自己目前更常用的是它。原因不复杂,就是同步稳定,批注体验顺手,门槛低。你不需要在一开始就把文献管理玩成一套复杂系统,先保证资料不乱、标注能回来找,就够了。
Zotero
• 地址: https://www.zotero.org/• 适合谁:文献很多、需要插件、需要高度可定制的进阶用户 • 核心能力:浏览器一键抓题录、PDF 收录、插件生态丰富、适合和网盘同步联动
如果你已经开始追求“一个库里放所有文献、笔记、标签、批注、引用格式联动”,Zotero 的上限更高。
Kimi Chat:长文精读阶段非常省时间
• 地址: https://kimi.moonshot.cn/• 解决什么问题:长论文、长报告、长专著,光靠人工一次读完太慢 • 核心能力:上传整篇 PDF 做长上下文问答、总结方法、拆解实验设计、辅助回复审稿意见 • 适合场景:精读论文前先做结构理解;看方法部分、实验部分时定向追问
我现在做论文精读时很常配它一起用。它最大的价值不是“替我读”,而是把我原本来回翻 PDF 的动作,变成按问题驱动的精读过程。
比如我会直接问它:
• 这篇的核心贡献和上一代方法到底差在哪 • 实验里哪个消融最关键 • 如果我只复现最小闭环,需要保留哪些模块
这几个问题一问,读论文的路径就清晰很多。
Cool Papers:把刷论文和提问连起来
• 地址: https://papers.cool/• 仓库: bojone/cool-papers• 解决什么问题:你想边刷 arXiv边做 AI 问答,不想在多个工具间来回切• 核心能力: arXiv浏览 + AI 交互问答• 适合场景:先判断论文值不值得精读,再决定是否下载 PDF
CopyTranslator:桌面端读英文 PDF 的顺手工具
• 地址: CopyTranslator• 解决什么问题:读英文 PDF 时,复制一段、切翻译器、再切回来,这个切换特别伤节奏 • 核心能力:监听剪贴板、置顶窗口、断行修复、多翻译引擎 • 适合场景:桌面端精读英文论文、技术报告、专利
这是我桌面端翻译工具里用得最顺的一类。复制即翻译、自动修 PDF 断行,这两个点非常实用。读英文文献时,真正影响效率的往往不是翻译质量本身,而是你有没有被打断。
Saladict:浏览器环境里的划词翻译主力
• 地址: https://saladict.crimx.com/• 解决什么问题:在线看论文、看网页资料时,需要更灵活的划词翻译和词典组合 • 核心能力:划词翻译、全文翻译、PDF 划词、词典组合、自定义触发方式 • 适合场景:浏览器里看论文网页、博客、文档、在线 PDF
我在浏览器里更常用它。配置起来比纯翻译插件灵活得多,尤其适合长期阅读英文资料的人。
语雀和 Notion:笔记别追求一步到位,先追求能回看
语雀
• 地址: https://www.yuque.com/• 适合场景:轻量记录论文笔记、实验想法、阅读清单
Notion
• 地址: https://www.notion.so/• 适合场景:做结构化知识库、管理课题进度、多人协作
这两个我更建议按使用习惯选,不用争“谁更高级”。如果你只是要把阅读笔记沉淀下来,轻一点反而更容易坚持。
代码和实验
论文能读懂,只是第一步。研究里第二个大坑,是实验链路不规范,最后自己都复现不了自己。
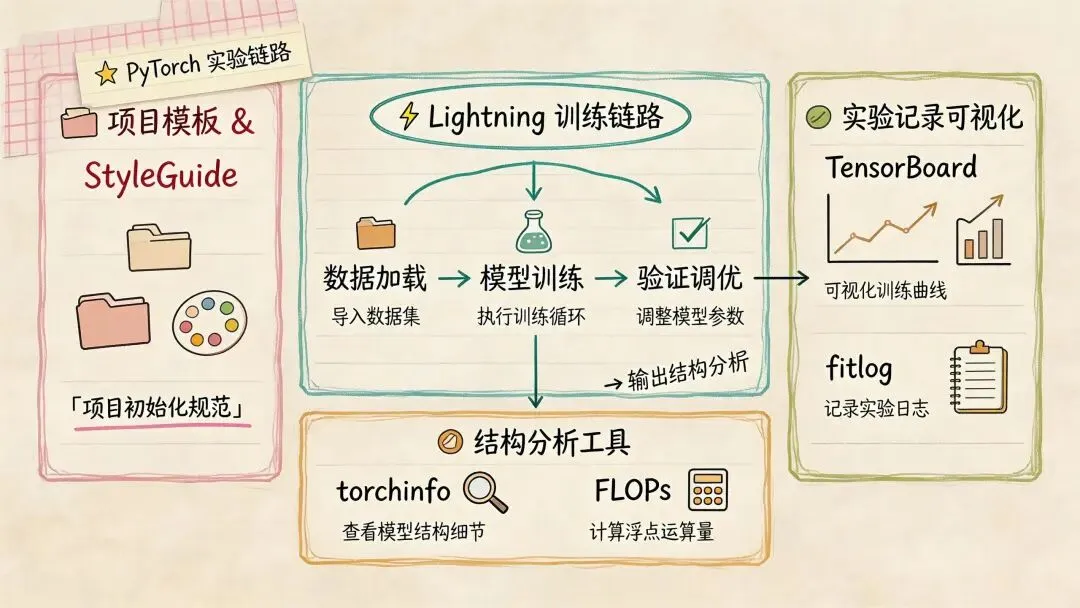
pytorch-lightning:把样板代码从主干逻辑里剥出去
• 地址: https://lightning.ai/docs/pytorch/stable/• 仓库: Lightning-AI/pytorch-lightning• 解决什么问题:训练、验证、日志、保存、分布式这些通用逻辑反复写,既耗时也容易乱 • 核心能力:训练流程标准化、分布式支持、日志与 checkpoint 统一管理 • 适合场景:中大型 PyTorch 项目、需要多人协作或长周期维护的实验
我对它的体感很明确:功能确实强,样板代码能少很多,但学习曲线也确实不低。新手别一上来就全套吃下去,先从最基础的训练模板开始,不然容易把问题从“代码太乱”变成“框架抽象看不懂”。
the-incredible-pytorch:PyTorch 生态导航图
• 地址: ritchieng/the-incredible-pytorch• 解决什么问题:PyTorch 生态太大,不知道该从哪里找教程、库、项目 • 核心能力:按主题聚合教程、项目、论文、视频、库 • 适合场景:切新方向时快速建一份资源地图
computervision-recipes:做 CV 项目时的高质量参考仓库
• 地址: microsoft/computervision-recipes• 解决什么问题:CV 任务很多,但高质量、成体系的参考实现并不多 • 核心能力:图像分类、检测、分割、多模态等任务的教程与最佳实践 • 适合场景:CV 方向快速启动 baseline、查工程组织方式
torchtracer:实验过程别只存一个“最终模型”
• 地址: neopython/torchtracer• 解决什么问题:实验多起来之后,超参数、日志、checkpoint、指标全散了 • 核心能力:记录实验配置、训练曲线、指标、结果回溯 • 适合场景:一个课题有多轮对比实验,需要之后回看“当时到底怎么跑的”
pytorch-styleguide 和项目模板:先把骨架搭对
• 风格指南: IgorSusmelj/pytorch-styleguide• 模板 1: moemen95/Pytorch-Project-Template• 模板 2: victoresque/pytorch-template
这些工具的价值不在“替你写模型”,而在于替你少踩项目结构的坑。尤其是实验刚开始的时候,目录怎么分、配置怎么管、训练和评估怎么拆,影响后面几个月的幸福程度。
torchinfo 和 FLOPs 工具:先把模型体量看清楚
torchinfo
• 地址: TylerYep/torchinfo• 解决什么问题:原生 print(model)信息太少• 核心能力:输出每层参数量、输出形状、内存占用、可训练参数
flops-counter.pytorch
• 地址: sovrasov/flops-counter.pytorch• 解决什么问题:不知道模型真实计算量多大 • 核心能力:统计整体 FLOPs 和逐层占比
我用它时的感受是,拿来评估 CNN 类模型很方便,但别指望它把所有结构都照顾到,像 RNN 相关层支持就不完整,可读性也比较一般。够用,但没到优雅。
TensorBoard、Visdom、Convolution Visualizer:把结构和训练过程看见
• TensorBoard: https://pytorch.org/docs/stable/tensorboard.html• Visdom: fossasia/visdom• Convolution Visualizer: https://ezyang.github.io/convolution-visualizer/
TensorBoard 还是最稳的基础设施,loss、指标、特征图、结构图基本够用。Convolution Visualizer 这种小工具则特别适合排查卷积层参数,尤其是你网络里空洞卷积、步长、padding 比较绕的时候,手算很容易出错。
fitlog:实验记录的另一种路线
• 地址: fastnlp/fitlog• 解决什么问题:需要一个框架无关的实验记录系统 • 核心能力:记录超参数、日志、指标、代码版本,支持 Web 可视化
如果你更在意“跨项目、跨框架统一管理实验记录”,可以关注它。
数据和调参
方向定了,代码搭了,接下来常见的卡点就两个:数据集去哪找,超参数怎么调。
Google Dataset Search 和 Bifrost:先把公开数据集地图打开
Google Dataset Search
• 地址: https://datasetsearch.research.google.com/• 适合场景:跨学科、跨模态搜公开数据集
Bifrost Data Search
• 地址: https://dataset.bifrost.ai/• 适合场景:计算机视觉任务找数据集,按任务类型筛选
如果你做的是 CV,后者更垂直;如果你做的是更泛的数据问题,前者覆盖面更广。
gdown:下载大文件别再靠浏览器赌运气
• 地址: wkentaro/gdown• 解决什么问题:Google Drive 上的大型数据集、权重文件经常下载失败,或者断了就得重来 • 核心能力:命令行下载、断点续传、文件夹下载 • 适合场景:拉公开数据集、拉 checkpoint、拉补充材料
这类工具看起来不起眼,但你真开始跑实验就知道,能稳定把数据拉下来,本身就是科研基础设施的一部分。
Featuretools:结构化数据的自动特征工程
• 地址: https://featuretools.alteryx.com/en/stable/• 解决什么问题:手工做特征工程很慢,尤其是关系型和时序型数据 • 核心能力:自动生成聚合特征、时间特征、关系特征 • 适合场景:结构化数据建模、传统机器学习基线
Optuna:超参数优化里的高性价比选手
• 地址: https://optuna.org/• 仓库: optuna/optuna• 解决什么问题:网格搜索和随机搜索都太笨 • 核心能力:贝叶斯优化、并行优化、早停、可视化分析 • 适合场景:已有基础训练脚本,想以较低侵入成本接入自动调参
如果你问我“超参优化从哪个工具开始学”,我一般会先说它。接入成本不高,收益又足够明显。
NNI、Hyperopt、BoTorch、Auto-PyTorch:更进阶的自动化路线
• NNI: microsoft/nni• Hyperopt: hyperopt/hyperopt• BoTorch: https://botorch.org/• Auto-PyTorch: automl/Auto-PyTorch
这一组更适合已经有明确自动化需求的人。比如分布式调参、架构搜索、自动建基线,这些场景它们的优势会更明显。
论文怎么写
研究做到最后,论文写不出来,前面一半努力都会被稀释。
很多人把“写论文”理解成“会写英文”。其实不够。你需要同时处理模板、协作、语言、公式、表格、图片这几条链。
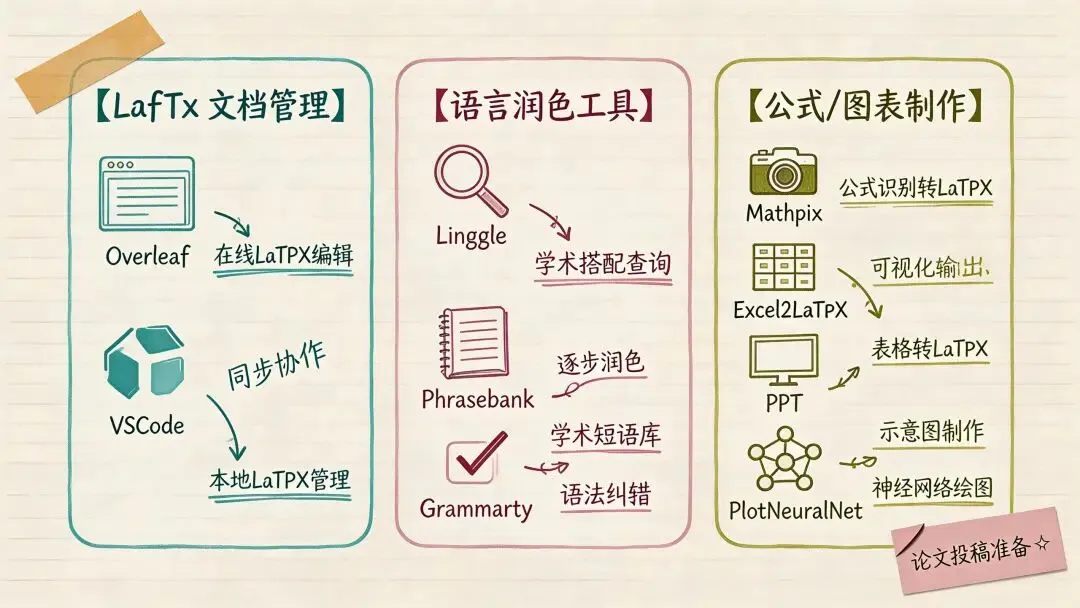
Overleaf:多人写论文时基本还是第一选择
• 地址: https://www.overleaf.com/• 模板库: https://www.overleaf.com/templates• 解决什么问题:本地 LaTeX 环境复杂、协作混乱、模板老出格式问题 • 核心能力:在线编辑、自动编译、多人协作、版本回溯、模板库 • 适合场景:团队联合写论文、快速套顶会模板
这基本还是我绝大多数时候的首选编辑器。尤其是多人协作,体验确实省心。唯一现实问题是网络环境,你如果处在不稳定链路里,体验会明显打折。
VSCode + LaTeX Workshop:单人长线写作更稳
• 工具组合: VSCode+LaTeX Workshop• 解决什么问题:你想离线写、自己掌控环境,不想依赖在线服务 • 适合场景:单人长周期论文、学位论文、本地 Git 管理
这套更像“工程化写作环境”。对单人项目尤其合适。
语言表达:Linggle、COCA、BNC、Thesaurus、ESODA、Words and Phrases
• Linggle: https://linggle.com/• COCA: https://corpus.byu.edu/coca/• BNC: https://corpus.byu.edu/bnc/• Thesaurus: https://www.thesaurus.com/• ESODA: https://www.esoda.org/• Words and Phrases: https://www.wordandphrase.info/
这一组不是让你“写得像母语者炫技”,而是帮你解决一个很实际的问题:你脑子里的中文意思是对的,但英文搭配不自然。
Linggle 和语料库工具特别适合查“这个说法学术论文里到底常不常用”。这比盲目让 AI 改写更稳,因为你看到的是真实语料。
Academic Phrasebank:不知道怎么起句时,直接查模板
• 地址: https://www.phrasebank.manchester.ac.uk/• 解决什么问题:引言、方法、结果、讨论这些段落,不知道学术表达怎么起笔 • 核心能力:按章节提供标准学术句式 • 适合场景:英文写作刚起步,或者某个章节总写得别扭
Grammarly 和 Nounplus:语法检查,但要有边界感
• Grammarly: https://www.grammarly.com/• Nounplus: https://www.nounplus.net/
这类工具能帮你改语法、标点、句型,但别把未发表核心内容一股脑丢进在线系统里。敏感稿件、匿名审稿阶段的内容,数据边界要自己守住。
公式和表格:Mathpix、MyScript、Detexify、Excel2LaTeX
• Mathpix: https://mathpix.com/• MyScript Webdemo: https://webdemo.myscript.com/• Detexify: https://detexify.kirelabs.org/classify.html• Excel2LaTeX: https://ctan.org/pkg/excel2latex
这几个都属于“省琐碎体力”的工具。公式截图转 LaTeX、手写符号识别、Excel 表格转 LaTeX,本质上都是把低价值重复劳动压掉。
配图和示意图:PPT、OmniGraffle、PlotNeuralNet 这条线最实用
• OmniGraffle: https://www.omnigroup.com/omnigraffle• PlotNeuralNet: HarisIqbal88/PlotNeuralNet• Paper-Picture-Writing-Code: MachineLP/Paper-Picture-Writing-Code• academic-drawing: MLNLP-World/academic-drawing• awesome-latex-drawing: xinychen/awesome-latex-drawing• IguanaTex: https://www.jonathanleroux.org/software/iguanatex/
如果你问我学术示意图最顺手的工具是什么,我反而会说 PPT。不是因为它最专业,而是因为上手成本低、自由度高、导出也够用。很多人一开始就冲复杂绘图软件,结果图没画出来,时间先烧没了。
科研写作真正该优化的,不是“工具看起来多专业”,而是“你能不能稳定把图、公式、表格高质量产出来”。
投稿和开源
论文不是写完就结束。最后这一步,最容易因为细节翻车。
ccf-deadlines、AI Deadlines、会伴:别错过截稿时间
• ccf-deadlines: https://ccfddl.github.io/• 仓库: ccfddl/ccf-deadlines• AI Deadlines: https://aideadlin.es/• Conference List: https://conferencelist.info/• 会伴: https://www.myhuiban.com/
国内做计算机研究,ccf-deadlines 真的很实用。按方向、按等级筛会议,看起来非常直接。你如果本来就有投会计划,最好把这一类网站和自己的日历绑起来,而不是靠脑子记。
盲审匿名分享:Dropbox、OSF、Figshare
• Dropbox: https://www.dropbox.com/• Open Science Framework: https://osf.io/• Figshare: https://figshare.com/
盲审阶段如果需要匿名分享代码、补充材料、数据,不建议临时为了某篇论文新建一堆奇怪账号。用成熟平台做匿名链接更省心,也更接近学术流程规范。
arXiv 提交:先清理,再上传
• 流程指南: https://zhuanlan.zhihu.com/p/405036265• 清理工具: google-research/arxiv-latex-cleaner• Overleaf 提交教程: https://zhuanlan.zhihu.com/p/506558001
很多人第一次投 arXiv,卡的不是论文内容,而是源码包结构、冗余文件、图片大小这些杂事。arxiv-latex-cleaner 很值,它不是炫技工具,就是一个能替你少踩坑的清理工。
代码开源:ReproducibilityChecklist 和 pigar
• Reproducibility Checklist: PapersWithCode/ReproducibilityChecklist• pigar: damnever/pigar
开源代码最怕两件事:环境配不起来,说明文档写不明白。
前者可以用 pigar 扫依赖,后者可以先照着可复现性清单补文件。你别小看这一步,很多论文代码不是方法不行,而是别人根本没法顺利跑起来。
还有几类小工具
这一类不一定每天都用,但碰到特定场景时很顶。
Google Patents:查技术专利
• 地址: https://patents.google.com/• 适合场景:做产业相关研究、查技术路线、看专利引用链
番茄・人生、Rainyscope、LofiGirl:给深度工作留一个环境
• Rainyscope: https://rainyscope.com/• LofiGirl: https://www.youtube.com/c/LofiGirl
这类工具当然不会直接提升你的模型指标,但它们会影响你能不能把两小时完整留给读论文、写代码、写论文。研究很多时候拼的不是某一个晚上爆发,而是你有没有稳定进入深度工作的条件。
最后给你一套抄作业版
如果你今天就想把自己的 AI 科研工具箱搭起来,我建议按这个顺序:
1. 用 irreader或Paper Digest建趋势输入源2. 用 dblp、Google Scholar、Semantic Scholar建论文检索路径3. 用 Papers With Code和代码仓库补复现入口4. 用 Mendeley或Zotero建文献库5. 用 Kimi Chat、CopyTranslator、Saladict提高精读效率6. 用 pytorch-lightning、TensorBoard、Optuna把实验链路搭稳7. 用 Overleaf、Mathpix、Academic Phrasebank把写作链路补齐8. 用 ccf-deadlines、arxiv-latex-cleaner、pigar处理投稿和开源收尾
你不需要一周之内把所有工具都学完。
但你最好尽快把自己的 AI 研究流程,从“靠搜索和记忆临时拼装”,升级成“一条能重复跑通的固定链路”。
真正能拉开差距的,从来不是你收藏了多少工具,而是你有没有把工具变成方法,把方法变成习惯。
如果你现在还没开始搭,我建议先从最朴素的一步做起:今天晚上就把论文追踪、文献管理、精读辅助这三件事先串起来。后面的复利,会比你想得更大。
