 夜雨聆风
夜雨聆风智猩猩AI整理

论文标题:
SCALING AGENTS VIA CONTINUAL PRE-TRAINING 论文链接: https://arxiv.org/abs/2509.13310 GitHub仓库地址:
https://github.com/Alibaba-NLP/DeepResearch?utm_source=chatgpt.com
01
方法
这篇工作的核心观点很鲜明:今天很多 Agent 不够强,不只是后训练不够好,更重要的是底座模型本身没有被真正训练成“会做 Agent”的模型。 通用 foundation model 虽然具备不错的语言能力,但缺乏多步规划、动作决策、工具调用和动态环境适应这类 agentic inductive bias。因此,直接在通用模型上开展 Agent 后训练,往往会使模型在同一阶段同时承担能力习得与行为对齐两项目标,从而产生内在的优化冲突。
为了解决这个问题,研究团队把训练流程改造成了:
预训练 → Agentic CPT → 后训练
如图2所示,其中Agentic CPT 仍然采用标准的 next-token prediction,不改变语言模型的基本训练范式,但会让模型在大规模 agentic 数据上持续学习。整个过程分为两阶段:
第一阶段: 约200B tokens、32K 上下文,重点学习规划、工具调用和基础推理。第二阶段: 约100B tokens、128K 上下文,进一步增强长上下文下的复杂规划与信息整合能力。

在具体实现上,研究团队提出了两类关键的数据构造机制:FAS 和 HAS。
(1)FAS:先让模型学会“面向任务地思考”
First-order Action Synthesis(FAS)。它的出发点是:如果只是把静态网页、知识库、百科数据直接喂给模型,模型学到的仍然主要是“知识表达”,而不是“任务驱动的问题空间”。
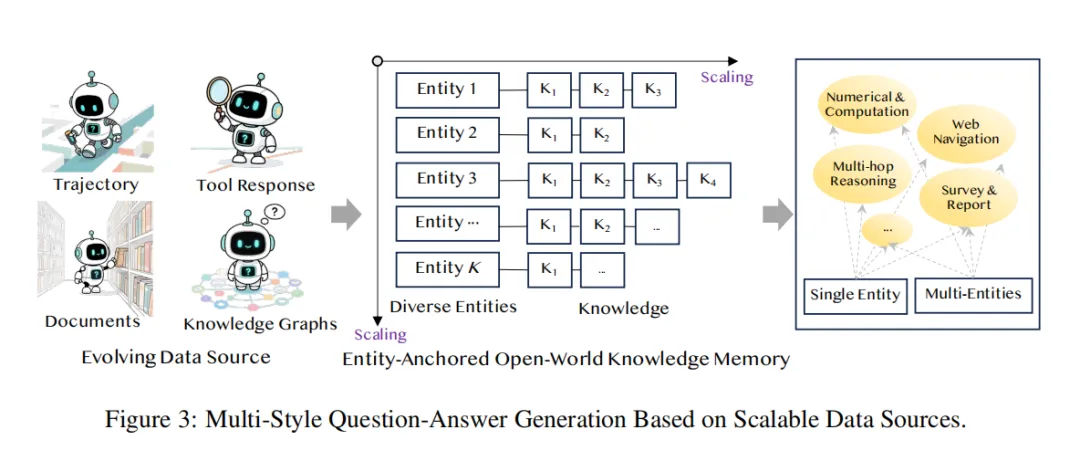
因此研究团队先把静态知识源改造成一种以实体为中心的开放世界记忆,再围绕这些实体自动生成多种复杂问题,如图3所示,让模型学会从“知识文本”走向“任务理解”。在此基础上,FAS 又分成两部分:
(i)Planning Action Synthesis:重点学习复杂任务的首步分析与动作预测;(ii)Reasoning Action Synthesis:重点学习在拿到足够信息后,如何完成多步信息整合与答案生成。
FAS 训练的不是简单问答,而是更接近真实 Agent 工作流中的 planning 与 reasoning 过程。
(2)HAS:把“失败轨迹”也变成训练资源
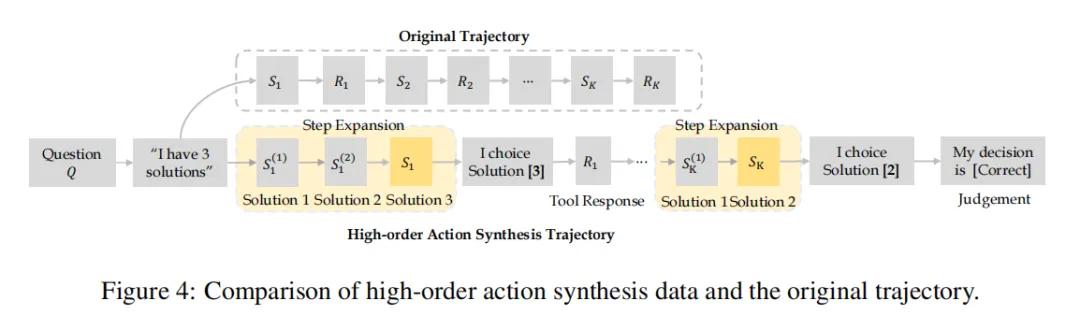
Higher-order Action Synthesis(HAS)。它的关键洞察在于:传统后训练往往只利用最终保留下来的高质量轨迹,而没有充分挖掘被丢弃轨迹、次优轨迹及其中间步骤所蕴含的监督信号。
为此研究团队设计了两步机制。
第一步是 Step-level Scaling。它会围绕轨迹中的某一步,生成多个替代性的 thought + action候选,让原本单一路径的行为过程,扩展成一个局部决策空间。
第二步是 Contrastive Decision-Action Synthesis。它进一步把这些候选改写成“多选决策 + 真实反馈 + 正误判断”的训练样本,让模型学习的不再只是模仿某一条轨迹,而是真正学习如何在多个可能动作之间做出更优选择。
这一步很重要,因为它意味着:Agent 训练不再只依赖“成功示范”,而是可以从更广泛的真实轨迹中提炼决策能力。
02
实验设置及结果分析
实验方面,研究团队构建了约 300B tokens 的 Agentic CPT 数据,来源包括高质量网页文本、历史工具调用记录、Wikipedia 以及后训练中被丢弃的轨迹。Stage 1 重点包含 planning、reasoning 与 HAS 数据,同时混入数学、代码、长链推理等通用数据以缓解遗忘;Stage 2 则进一步加入 64K–128K 长上下文数据,并对早期数据进行回放,以保持分布稳定。研究团队还采用 13-gram 去重与 URL 级过滤,尽量避免 benchmark 污染。
评测覆盖了 10 个基准,既包含 BrowseComp-en、BrowseComp-zh、GAIA、xbench-DeepSearch、WebWalkerQA 等通用网页搜索任务,也包含 DeepResearch Bench、SEAL-0、Frames、HLE、Academic Browse 等更贴近 deep research 场景的复杂任务。
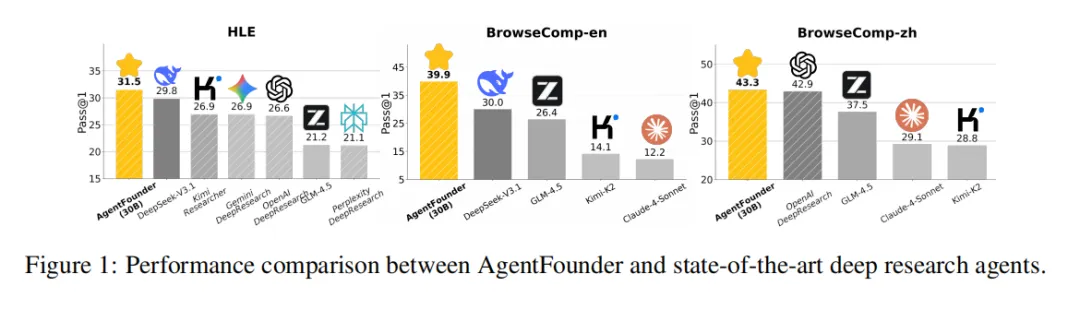
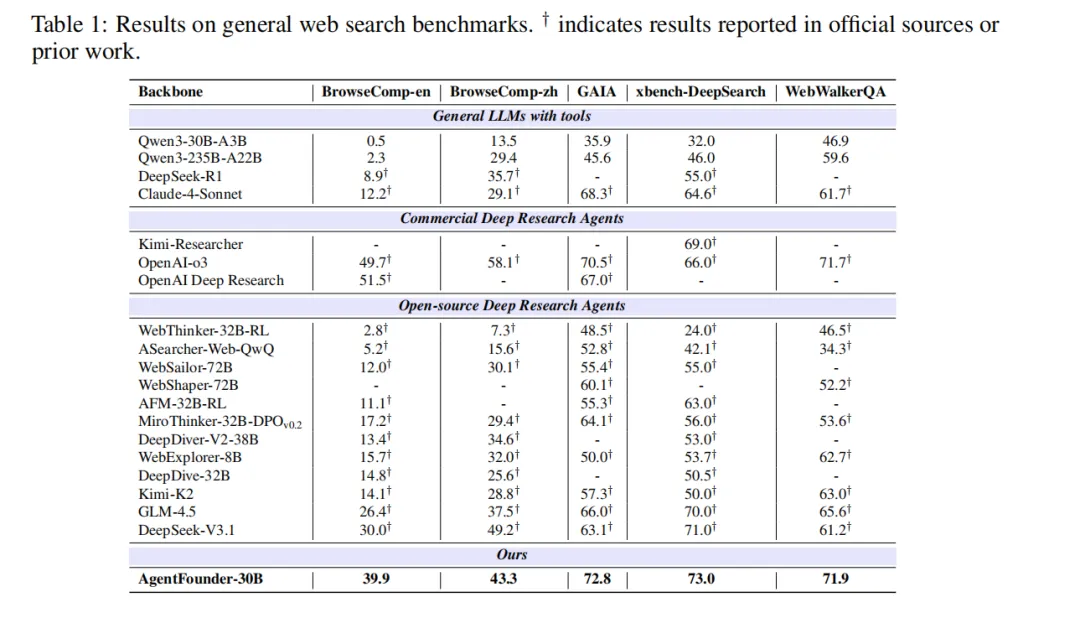
结果上,AgentFounder-30B 展现出很强的竞争力,如表1所示。在通用网页搜索任务中,它在 BrowseComp-en 上达到 39.9%,在 BrowseComp-zh 上达到 43.3%,在 GAIA 上达到 72.8%,在 xbench-DeepSearch 上达到 73.0%。在场景化 deep research 任务中,它进一步取得 DeepResearch Bench 47.9、Frames 89.6、SEAL-0 43.9、Academic Browse 75.3、HLE 31.5 的成绩,其中 HLE 突破 30 分尤其值得关注,这意味着它已经具备相当强的高难度综合研究能力。
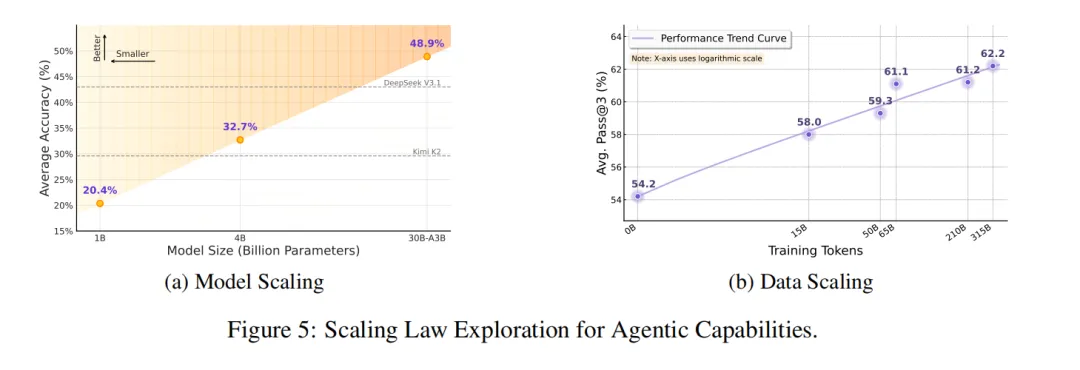
更重要的是,论文证明 Agentic CPT 不只是“刷榜有效”,还显著提升了 base model 对不同后训练数据与策略的适配性。研究团队在三种不同 SFT 设置下比较了 AgentFounder-30B-Base 与 Qwen3-30B-A3B-Base,结果显示前者平均分别提升 5.75%、6.13%、6.45%。同时,在论文的 50B token 消融设置下,两阶段训练优于单阶段训练,FAS 与 HAS 也表现出明显互补性;随着模型规模和数据规模继续增加,性能也持续提升,呈现出稳定的 scaling 趋势,如图5所示。
03
总结
这篇论文不只是做出了一个更强的开源 agent,更在于明确提出:Agent 能力不应只在后训练阶段被动补齐,而应在持续预训练阶段被系统构建。Agentic CPT 让 agent foundation model 这条路线变得更清晰,也为后续 deep research agent 的训练范式提供了新的方向。
END
✦
✦
入群申请
✦

智猩猩矩阵号各专所长,点击名片关注
