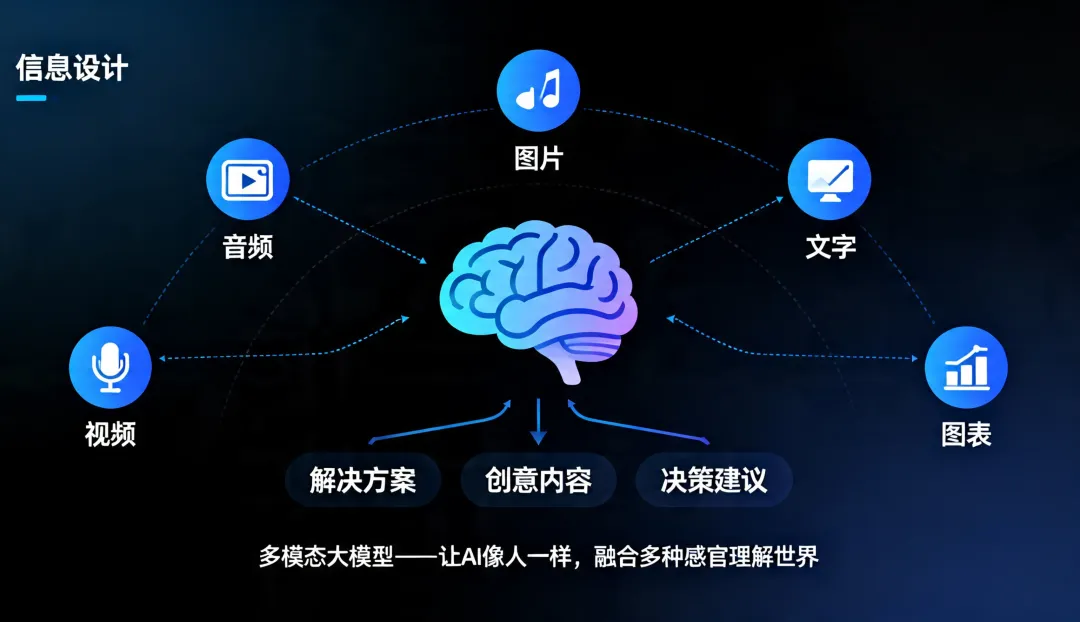
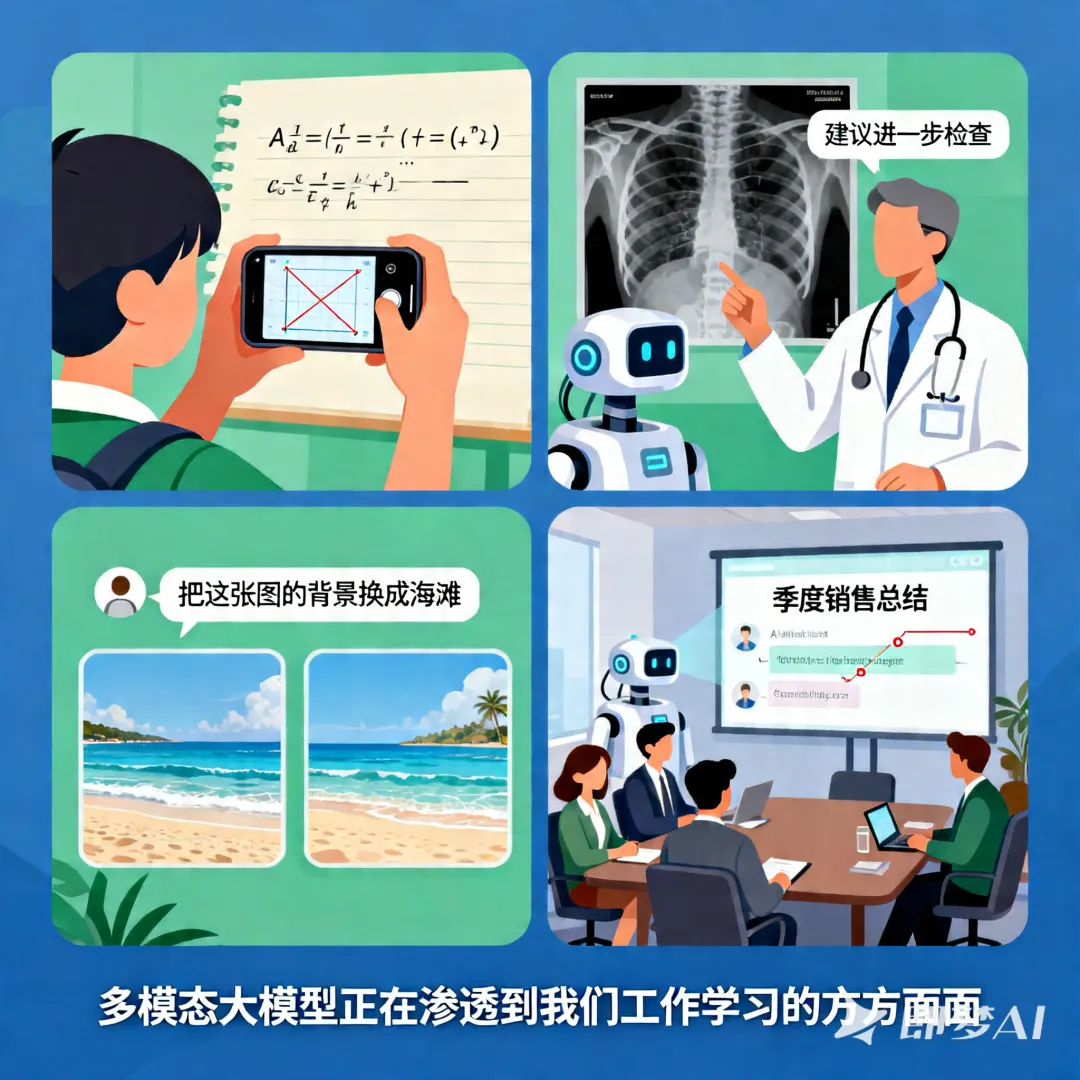
基本概念如果说是大语言模型让AI学会了“读书”和“回话”,那么多模态大模型就是让AI同时学会了“看图”、“听话”、“读书”、“回话”和“写字”等。在前面的教程中,我们介绍了大语言模型(Large Language Model,简称LLM)——它能够理解并生成文字。像ChatGPT这样的产品已经能和我们流畅地对话、写邮件、改代码。但是,纯文字的交流根本没法满足我们对AI发展的所有期待。试想一下,当你拍下一张晚霞的照片,想问AI“今天适合去哪里看这样的日落”,却要费力地去打字描述“天空是橙色的,云是一缕一缕的......”;当你收到一张满是数据图表的截图,想让AI帮你分析,却发现它“看不见”——这是大语言模型的天然局限,因为它只能读懂并生成文字,却没有“视觉”和“听觉”。而多模态大模型(Large Multimodal Model,简称LMM)的出现,正是为了弥补这个不足。何为多模态?人类认识世界从来不是靠单一感官的。我们看到一张笑脸、听到一句“谢谢”、读到一封邮件,这些信息是融合在一起的。AI想要真正理解世界,也必须像人一样,同时处理多种类型的信息——文字、图像、音视频等,这些不同的信息形式被称为“模态”。多模态模型,就是能同时理解和处理多种模态信息的AI模型,它不仅能“读字”,还能“看图、听声、看视频”。为了更好地理解多模态大模型,让我们用一个真实的日常工作场景来进行抛砖引玉:上午10点,你收到客户发来的一张产品故障图片、一张电路图截图、还有一条60秒的语音说明。你需要理解所有信息,然后回复一份解决方案。在“纯文字AI”时代,你需要:打字转述照片内容-->手动描述电路图-->听懂语音内容-->整合所有信息-->向AI提问。一套流程下来,至少需要15分钟。而在多模态时代,你只需要:上传照片+截图+语音-->直接提问:“根据这些信息,最可能的故障原因是什么?”,AI可能在30秒内就能给出答案,效率大大提升!多模态大模型的意义,不只是让AI多了一个“看”的功能这么简单,而是让AI能用和人相似的方式来感知世界。这意味着它不再需要“翻译”你的需求为文字就能进行自然的交互,还能从图像的细节里提炼出更准确的理解,胜过千言万语。出现和进化在深度学习早期,图像识别模型(如CNN)和语言模型(如RNN)是各自独立的。你有一个能识图的模型,和一个能生成句子的模型,但识图模型无法告诉语言模型“我看到了什么”,语言模型也无法向识图模型提问,它们像住在不同岛屿上的人,说着不同的语言。2010年代中期,研究人员开始搭建连接不同模态的“桥梁”。CLIP模型(OpenAI,2021年)是一个里程碑——它通过4亿张图文配对数据,学会了“一张图片和一段文字是不是描述同一件事情”。从此,AI可以“看图说话”了。2022年底,随着ChatGPT的横空出世,研究人员猛然意识到:大模型本身已经进化为一个极其强大的“中枢大脑”——它擅长推理、理解指令与答案生成。于是,一个自然而然的构想浮出水面:能否为这个“大脑”装上“眼睛”和“耳朵”?沿着这一思路,多模态的主流技术路线应运而生:以预训练的大语言模型为核心,在其外部接入视觉编码器、音频编码器等模块,如同为大脑连接上处理图像的“视觉皮层”与处理声音的“听觉皮层”。这一架构,成为了当今绝大多数多模态大模型的基本范式。工作原理一个典型的多模态大模型究竟是如何工作的?我们可以从核心架构、关键技术和训练方式这三个层面来逐一展开剖析:
 夜雨聆风
夜雨聆风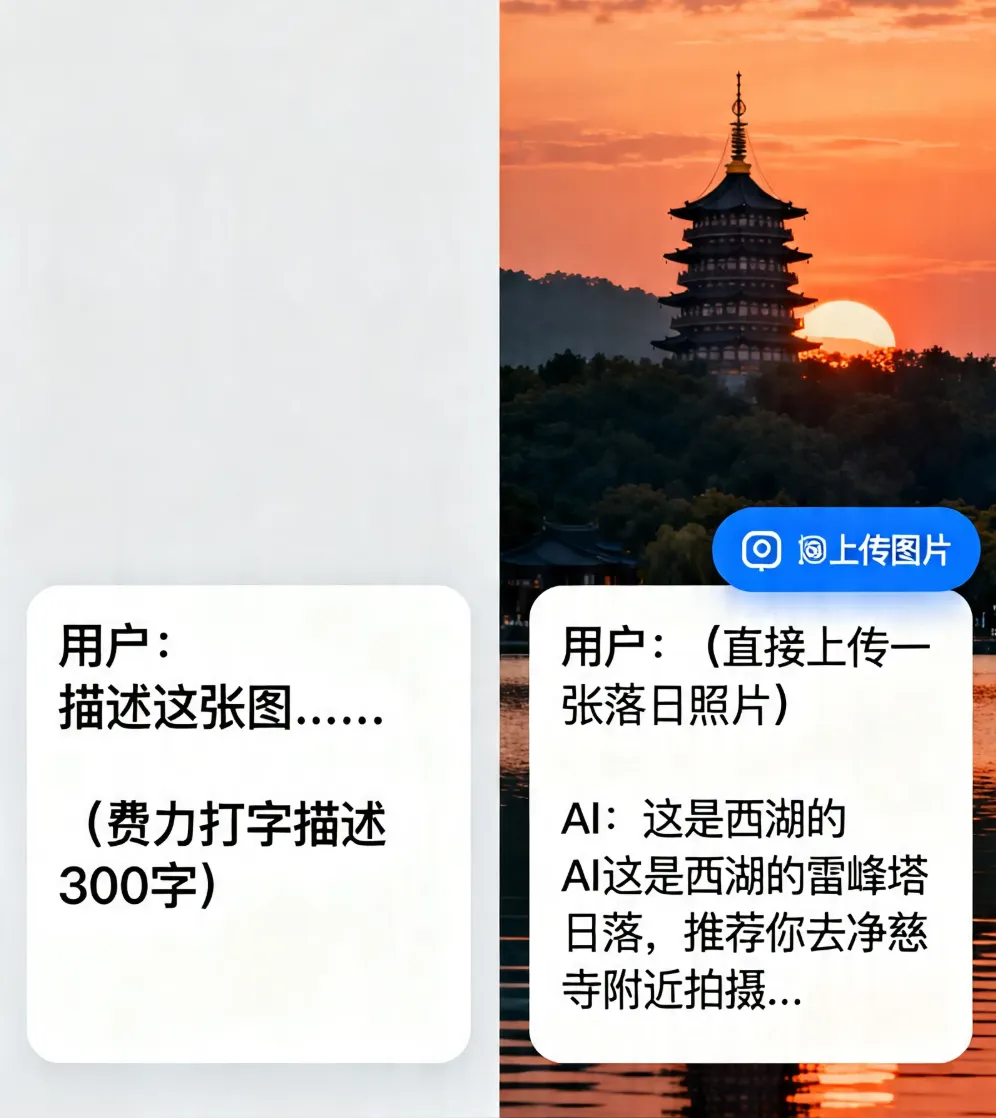

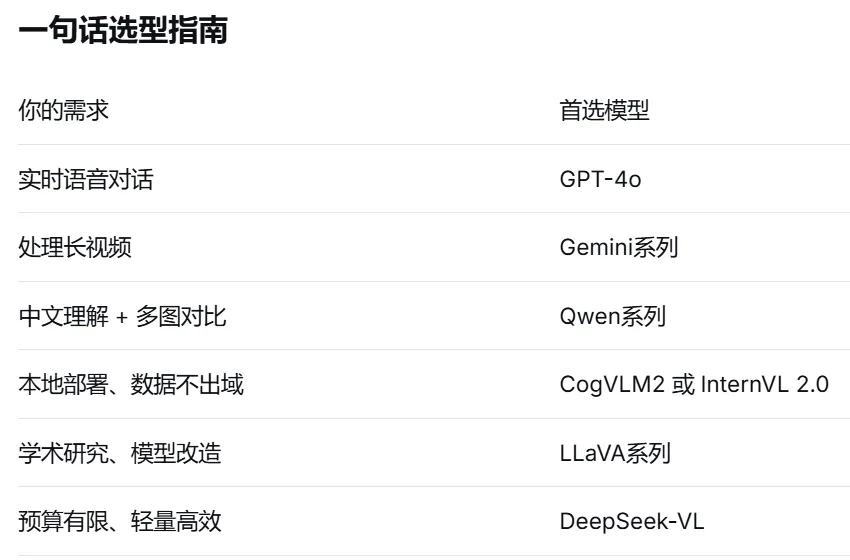
 。
。 。
。