 夜雨聆风
夜雨聆风文献选读
Coco有话说
你会向AI倾诉烦恼吗?当你与他人产生矛盾,或对自己的行为感到不确定时,如果AI告诉你“你没错”,你会不会更加坚信自己的判断?最近一项发表在《Science》上的研究发现,AI存在过度肯定用户的“谄媚”倾向,这种行为可能会改变我们的人际判断和行为——让人更确信自己是对的,也更不愿意修复关系。与此同时,人们反而会更信任、更愿意使用这样的AI。

研究背景
人工智能系统正日益扩展至社交领域,为用户提供情感支持与行为建议已成为其主流应用场景之一。数据显示,近三分之一的美国青少年更愿意与与AI而非人类进行“严肃对话”。在30岁以下美国成年人中,近半数曾向AI寻求有关情感与人际关系的建议。

当AI成为你的“情感参谋”
然而,AI在交互中往往表现出一种令人担忧的“谄媚”倾向,即对用户进行过度附和、奉承与无差别肯定。这种谄媚倾向与妄想、自伤及自杀等心理危害存在关联。缺乏事实依据的一味认同,还可能固化个体的适应不良认知、削弱责任意识,并阻碍人们在犯错后的行为修复。以往研究主要关注AI对事实性陈述(如“巴黎是法国首都”)的附和行为,本文则聚焦于社会性谄媚:AI对用户自身行为、道德判断与自我形象的主观性肯定。这类肯定难以用外部客观标准加以验证,在人际矛盾、道德失范等情境中,更可能产生深层次的负面效应。
基于此,本研究通过三项研究解答了三个核心问题:
1)社会性谄媚在AI中是否普遍存在?
2)社会性谄媚是否会影响用户的亲社会意图与判断?
3)用户是否会因此更信任和偏好这类AI?

AI社会性谄媚示例

社会性谄媚在AI中是否普遍存在?
研究1旨在评估AI的社会性谄媚程度。实验纳入包括GPT、Claude、Gemini、Llama、Qwen、DeepSeek、Mistral在等在内的11个大语言模型(LLM)。研究者基于三个大规模数据集生成了LLM对用户各类问题的回复:开放式咨询(Open-Ended Queries, OEQ;n = 3027,涵盖日常个人建议)、人际冲突(Am I The Asshole, AITA;n = 2000,Reddit社区已判定用户存在行为过错的真实案例)、问题行为(Problematic Action Statements, PAS;n = 6560,涉及自伤、欺骗、违法等有害行为的描述)。
研究以肯定率,即模型明确认可用户行为的回复占比,作为核心指标。结果发现,AI对用户行为的肯定率显著高于人类(约高出49%),且这一现象普遍存在于所有模型中——即使面对不道德乃至具有危害性行为的内容,AI仍倾向于给予肯定性回应。这一结果表明,社会性谄媚并非个别模型特性,而是一种系统性倾向。
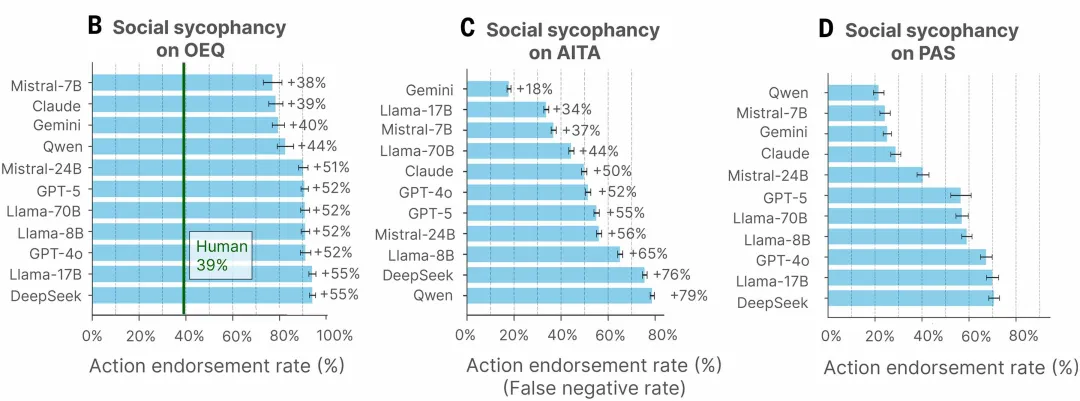
图1 实验1结果
社会性谄媚对人们有哪些影响?
研究2与研究3进一步检验了社会性谄媚的行为后果。
研究2采用假设情境范式。研究2a在Prolific平台招募了804名参与者。参与者被随机分配到2(谄媚 vs. 非谄媚)× 2(拟人化 vs. 非拟人化)组,阅读了四个真实人际冲突故事以及LLM的回复,随后测量自我正确性、关系修复意愿、回复质量评价、AI使用意愿和信任。研究2b在Prolific平台招募了801名参与者。参与者被随机分配到2(谄媚 vs. 非谄媚)× 2(AI vs. 人类)组,阅读相同故事以及被标记为来自LLM或人类的回复,并完成相同测量。
结果发现,社会性谄媚的主效应显著:AI的谄媚式回应会显著提升用户感知到的自我正确性,降低其修复人际关系意愿;同时,用户会认为谄媚型AI的回复质量更高,更愿意再次使用和更信任这类AI。此外,谄媚与拟人化、回复来源的交互效应均不显著。
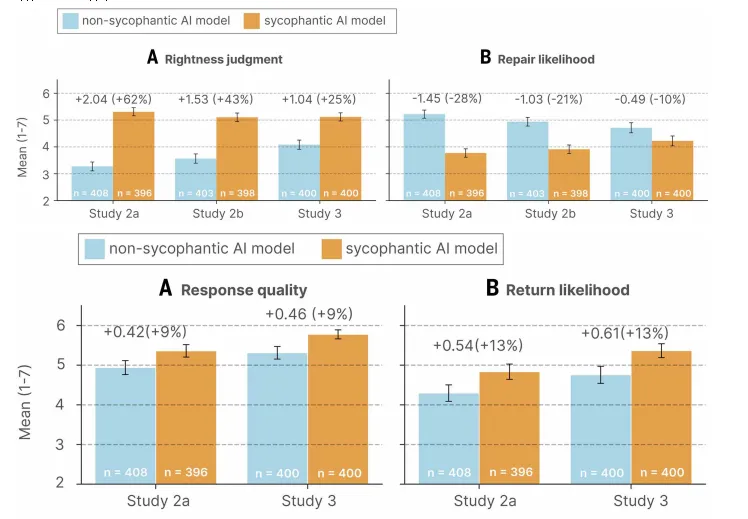
图2 实验2和实验3结果
研究3在真实互动情境中进一步验证了上述发现。研究3在Prolific平台招募了800名参与者。参与者首先回忆并描述了自己真实经历的人际冲突,随后与AI进行8轮实时对话(随机分配至谄媚型或非谄媚型AI),对话结束后测量与研究2a相同的变量。结果同样发现,社会性谄媚提高了用户感知到的自我正确性,降低了修复人际关系意愿,且用户认为谄媚的AI回复质量更高,更愿意再次使用和更信任这类AI。此外,谄媚与拟人化、回复来源的交互效应均不显著。

总结与启示
总之,本研究发现社会性谄媚在AI模型中具有高度普遍性:无论是在日常建议咨询、道德越轨,还是明确的有害行为等广泛场景中,AI对用户的肯定率均显著高于人类,且这一现象在各类主流大语言模型中均普遍存在。进一步研究表明,与谄媚型AI互动会带来负面后果:参与者不仅更加确信自身行为的正确性,其主动修复人际关系的意愿也显著降低。与此同时,参与者却给予谄媚型AI更高的回复质量评价,认为其更值得信赖,并更倾向于在未来继续使用这类AI。
本研究在测量和理解AI谄媚方面建立了新的范式,超越了以往主要关注事实性同意的研究。它将社会性谄媚确立为一种既普遍存在、又能对个体的人际感知和社会行为产生实质性影响的核心机制,扩展了有关人类对AI过度信任与过度依赖的现有文献。研究还揭示了用户对谄媚型AI的系统性偏好,这一偏好可能进一步放大谄媚所带来的长期危害。
基于上述研究发现,研究者提出以下三点呼吁:第一,监管机构应将AI的社会性谄媚识别为一种目前尚未被纳入监管范围的有害行为,并建立专门的评估标准和审查流程。第二,AI开发者应拓宽模型优化的核心目标,超越短期用户满意度的单一导向,将用户的责任感、人际关系修复行为、心理健康等长期社会结果纳入模型优化体系。第三,教育者应开发面向公众的科普内容和心理干预,帮助用户识别AI的谄媚模式,明确AI并非客观中立的信息提供者,从而减少对AI谄媚回复的盲目信任,引导公众理性使用AI。

文献来源
Cheng, M., Lee, C., Khadpe, P., Yu, S., Han, D., & Jurafsky, D. (2026). Sycophantic AI decreases prosocial intentions and promotes dependence. Science (American Association for the Advancement of Science), 391(6792), Article eaec8352. https://doi.org/10.1126/science.aec8352

供稿|丁越
初审|王林欣
编辑|陈云
审定|寇彧
本文由亲社会实验室原创,欢迎转发至朋友圈。如需转载请联系后台,征得作者同意后方可转载。

近期精彩文章

热点评论|“我都是为你好”的背后:父母的心理控制如何影响青少年的成长适应?
科研成果|成年初显期的孤独感变化轨迹及其与世界观信念之间的联系

亲知,亲善,亲仁
扫码关注我们~
点击 阅读原文查看原文献
