 夜雨聆风
夜雨聆风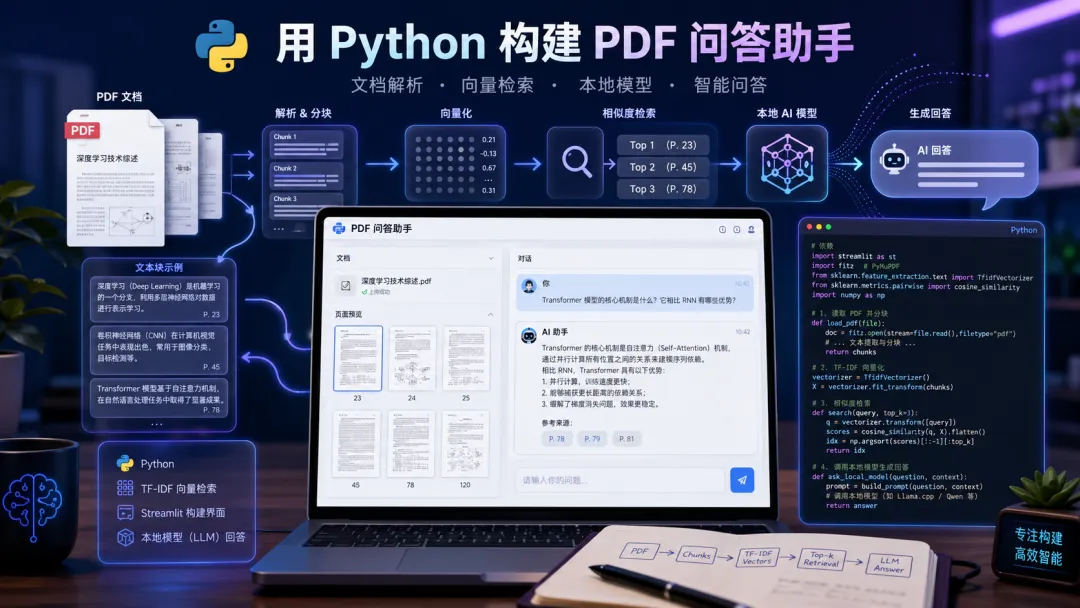
有段时间我经常遇到一个问题:手里有一份几十页甚至上百页的 PDF,想找一个具体信息,只能一页页翻。
如果是论文,还能用关键词搜一搜;如果是产品文档、合同、财报、说明书,关键词不一定知道怎么搜。比如我想问:
这个文档里有没有提到风险控制?
作者最后的结论是什么?
这份材料里和成本有关的内容有哪些?
这种问题用传统搜索不太舒服,因为我不是在找一个词,而是在找一段意思。
所以我做了一个小工具:上传 PDF 后,直接向它提问。它会先在 PDF 里找最相关的内容,再根据这些内容回答问题。
这篇文章不只讲思路,也会把完整代码放出来。照着做,基本就能跑起来。
这个版本我故意没有一上来用向量数据库、LangChain 或一堆框架。第一版先把核心流程跑通:PDF 解析、文本切块、相似度检索、调用本地大模型回答。后面再升级 Embedding、RAG、向量数据库会更顺。
我们先看最终效果。
上传一个 PDF,输入问题:
这个文档主要讲了什么?
程序会返回类似这样的结果:
根据文档内容,这份资料主要围绕……展开。文档前半部分介绍了……后半部分重点讨论了……整体来看,它的核心结论是……
下面还会列出它参考了 PDF 的哪些页,方便回去核对原文。
这个 PDF 问答助手是怎么工作的
这个小工具的流程其实不复杂。
第一步,读取 PDF 里的文字。
第二步,把整篇文档切成很多小段。因为 PDF 可能很长,不能一整篇直接塞给模型。
第三步,把用户的问题和每个小段做相似度计算,找出最相关的几段。
第四步,把问题和相关原文一起交给大模型,让它只根据这些内容回答。
这个思路就是一个最小版的文档问答系统。
严格来说,它还不是完整版 RAG。因为这里的检索部分我先用了 sklearn 里的 TF-IDF 和余弦相似度,而不是 Embedding 向量检索。这样做有一个好处:依赖少,容易理解,而且对第一版项目非常友好。scikit-learn 的 TfidfVectorizer 可以把文本转成 TF-IDF 特征,cosine_similarity 可以计算向量之间的余弦相似度。
大模型这块,我用的是 Ollama。它可以在本地跑模型,并提供本地 HTTP API。Ollama 的 chat 接口地址是 /api/chat,可以通过 POST 请求发送消息,stream 设置成 false 时可以一次性拿到完整回复。
PDF 解析用 PyMuPDF。PyMuPDF 的 Page.get_text 可以从 PDF 页面中提取文本,不过官方文档也提醒过,PDF 文本的原始顺序不一定等于我们肉眼看到的阅读顺序,所以代码里我会使用 sort=True,让它尽量按从左上到右下的顺序取文本。
界面用 Streamlit。它的好处是不用写前端,几个组件就能做出一个可交互的小网页。这里主要用到文件上传和文本输入组件。
先准备环境
我用的是 Python 3.10。如果你是 Python 3.9 或 3.11,大概率也没问题。
新建一个项目文件夹:
pdf_qa_assistant
进入文件夹:
cd pdf_qa_assistant
创建虚拟环境:
python -m venv .venv
macOS 或 Linux 激活:
source .venv/bin/activate
Windows 激活:
.venv\Scripts\activate
然后新建一个 requirements.txt:
streamlit
pymupdf
scikit-learn
numpy
requests
安装依赖:
pip install -r requirements.txt
接下来准备本地大模型。
先安装 Ollama,然后拉一个模型。这里我用 qwen2.5:7b 举例:
ollama pull qwen2.5:7b
如果你的电脑配置一般,可以先用小一点的模型:
ollama pull qwen2.5:3b
启动模型测试一下:
ollama run qwen2.5:7b
如果它能正常对话,说明本地模型已经准备好了。
项目结构
这个项目非常简单,只有两个文件:
pdf_qa_assistant
├── app.py
└── requirements.txt
下面是完整的 app.py。
完整代码
import re
import requests
import numpy as np
import streamlit as st
import fitz
from dataclasses import dataclass
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
@dataclass
classTextChunk:
text: str
page_start: int
page_end: int
chunk_id: int
defclean_text(text: str) -> str:
text = text.replace("\x00", "")
text = re.sub(r"[ \t]+", " ", text)
text = re.sub(r"\n{3,}", "\n\n", text)
return text.strip()
defextract_text_from_pdf(pdf_bytes: bytes) -> list[tuple[int, str]]:
doc = fitz.open(stream=pdf_bytes, filetype="pdf")
pages = []
for page_index in range(len(doc)):
page = doc[page_index]
text = page.get_text("text", sort=True)
text = clean_text(text)
if text:
pages.append((page_index + 1, text))
doc.close()
return pages
defsplit_text_by_pages(
pages: list[tuple[int, str]],
max_chars: int = 900,
overlap: int = 150
) -> list[TextChunk]:
chunks = []
chunk_id = 0
for page_number, page_text in pages:
text = page_text.strip()
ifnot text:
continue
start = 0
text_length = len(text)
while start < text_length:
end = start + max_chars
chunk_text = text[start:end].strip()
if chunk_text:
chunks.append(
TextChunk(
text=chunk_text,
page_start=page_number,
page_end=page_number,
chunk_id=chunk_id
)
)
chunk_id += 1
if end >= text_length:
break
start = max(0, end - overlap)
return chunks
defbuild_tfidf_index(chunks: list[TextChunk]):
texts = [chunk.text for chunk in chunks]
vectorizer = TfidfVectorizer(
analyzer="char",
ngram_range=(2, 4),
max_features=80000
)
matrix = vectorizer.fit_transform(texts)
return vectorizer, matrix
defretrieve_relevant_chunks(
question: str,
chunks: list[TextChunk],
vectorizer: TfidfVectorizer,
matrix,
top_k: int = 5
) -> list[tuple[TextChunk, float]]:
question_vec = vectorizer.transform([question])
scores = cosine_similarity(question_vec, matrix).ravel()
top_indices = np.argsort(scores)[::-1][:top_k]
results = []
for index in top_indices:
score = float(scores[index])
if score > 0:
results.append((chunks[index], score))
return results
defbuild_prompt(question: str, retrieved_chunks: list[tuple[TextChunk, float]]) -> str:
context_parts = []
for i, (chunk, score) in enumerate(retrieved_chunks, start=1):
context_parts.append(
f"资料片段 {i}\n"
f"页码:第 {chunk.page_start} 页\n"
f"相关度:{score:.4f}\n"
f"内容:\n{chunk.text}"
)
context = "\n\n".join(context_parts)
prompt = f"""
你现在是一个严谨的 PDF 阅读助手。
请只根据下面给出的资料片段回答问题。
如果资料片段里没有答案,请直接说:根据当前 PDF 内容,暂时找不到明确答案。
不要编造资料片段之外的信息。
回答时尽量具体,必要时可以列出要点。
如果不同片段之间有冲突,请提醒用户需要回到原文核对。
用户问题:
{question}
资料片段:
{context}
请开始回答:
""".strip()
return prompt
defask_ollama(
prompt: str,
model: str = "qwen2.5:7b",
host: str = "http://localhost:11434"
) -> str:
url = f"{host.rstrip('/')}/api/chat"
payload = {
"model": model,
"stream": False,
"messages": [
{
"role": "system",
"content": "你是一个谨慎、准确的中文文档问答助手。"
},
{
"role": "user",
"content": prompt
}
]
}
try:
response = requests.post(url, json=payload, timeout=180)
response.raise_for_status()
data = response.json()
return data["message"]["content"].strip()
except requests.exceptions.ConnectionError:
return (
"没有连接到 Ollama。请确认你已经安装并启动 Ollama,"
"并且本地地址 http://localhost:11434 可以访问。"
)
except requests.exceptions.Timeout:
return"模型响应超时。可以换一个更小的模型,或者减少检索片段数量。"
except Exception as e:
returnf"调用 Ollama 时出错:{e}"
defprocess_pdf(uploaded_file):
pdf_bytes = uploaded_file.getvalue()
pages = extract_text_from_pdf(pdf_bytes)
ifnot pages:
returnNone, "没有从 PDF 中提取到文字。它可能是扫描版 PDF,需要先做 OCR。"
chunks = split_text_by_pages(pages)
ifnot chunks:
returnNone, "PDF 文字太少,无法建立索引。"
vectorizer, matrix = build_tfidf_index(chunks)
result = {
"file_name": uploaded_file.name,
"pages": pages,
"chunks": chunks,
"vectorizer": vectorizer,
"matrix": matrix
}
return result, None
defmain():
st.set_page_config(
page_title="PDF 问答助手",
page_icon="📄",
layout="wide"
)
st.title("PDF 问答助手")
st.caption("上传一份 PDF,然后直接向它提问。")
with st.sidebar:
st.header("设置")
model_name = st.text_input(
"Ollama 模型名",
value="qwen2.5:7b",
help="如果电脑配置一般,可以换成 qwen2.5:3b"
)
ollama_host = st.text_input(
"Ollama 地址",
value="http://localhost:11434"
)
top_k = st.slider(
"参考片段数量",
min_value=2,
max_value=8,
value=5
)
st.markdown("---")
st.write("运行前请确认:")
st.code("ollama pull qwen2.5:7b")
st.code("ollama run qwen2.5:7b")
uploaded_file = st.file_uploader(
"上传 PDF 文件",
type=["pdf"]
)
if uploaded_file isNone:
st.info("先上传一份 PDF。")
return
file_key = f"{uploaded_file.name}-{uploaded_file.size}"
if st.session_state.get("file_key") != file_key:
with st.spinner("正在读取 PDF 并建立索引..."):
pdf_data, error = process_pdf(uploaded_file)
if error:
st.error(error)
return
st.session_state["file_key"] = file_key
st.session_state["pdf_data"] = pdf_data
pdf_data = st.session_state["pdf_data"]
st.success(
f"已读取:{pdf_data['file_name']},"
f"共 {len(pdf_data['pages'])} 页,"
f"切分为 {len(pdf_data['chunks'])} 个片段。"
)
question = st.text_input(
"请输入你的问题",
placeholder="比如:这份文档的核心结论是什么?"
)
ask_button = st.button("开始提问")
if ask_button:
ifnot question.strip():
st.warning("请先输入一个问题。")
return
with st.spinner("正在检索相关内容..."):
retrieved_chunks = retrieve_relevant_chunks(
question=question,
chunks=pdf_data["chunks"],
vectorizer=pdf_data["vectorizer"],
matrix=pdf_data["matrix"],
top_k=top_k
)
ifnot retrieved_chunks:
st.warning("没有找到相关内容。可以换一种问法试试。")
return
prompt = build_prompt(question, retrieved_chunks)
with st.spinner("正在让模型生成回答..."):
answer = ask_ollama(
prompt=prompt,
model=model_name,
host=ollama_host
)
st.subheader("回答")
st.write(answer)
st.subheader("参考片段")
for i, (chunk, score) in enumerate(retrieved_chunks, start=1):
with st.expander(
f"片段 {i}|第 {chunk.page_start} 页|相关度 {score:.4f}"
):
st.write(chunk.text)
if __name__ == "__main__":
main()
运行项目
在项目目录下运行:
streamlit run app.py
浏览器会自动打开一个页面。
如果没有自动打开,可以手动访问终端里显示的地址,通常是:
http://localhost:8501
页面打开后,上传 PDF,输入问题,就可以开始问了。
代码是怎么工作的
先看 PDF 解析部分。
defextract_text_from_pdf(pdf_bytes: bytes) -> list[tuple[int, str]]:
doc = fitz.open(stream=pdf_bytes, filetype="pdf")
pages = []
for page_index in range(len(doc)):
page = doc[page_index]
text = page.get_text("text", sort=True)
text = clean_text(text)
if text:
pages.append((page_index + 1, text))
doc.close()
return pages
这里用 fitz.open 打开 PDF。uploaded_file.getvalue() 拿到的是 PDF 的二进制内容,所以 fitz.open 里用了 stream=pdf_bytes。
每一页通过 page.get_text("text", sort=True) 提取文字。sort=True 不是万能的,但它能让提取结果更接近正常阅读顺序。
有些 PDF 提取不到文字,常见原因是它本质上是一张张扫描图片。这个版本暂时不处理 OCR。如果你上传的是扫描版合同、扫描版教材,程序可能会提示没有提取到文字。这个问题后面可以用 OCR 解决。
接下来是文本切块。
defsplit_text_by_pages(
pages: list[tuple[int, str]],
max_chars: int = 900,
overlap: int = 150
) -> list[TextChunk]:
为什么要切块?
因为 PDF 可能很长。如果把整份 PDF 一次性塞给模型,成本高,速度慢,还容易超过上下文限制。更好的做法是先找出相关段落,再把少量相关内容交给模型。
max_chars=900 表示每个片段最多 900 个字符。
overlap=150 表示相邻片段之间保留 150 个字符的重叠。
这个重叠很重要。假设一个关键句子刚好被切在两个片段之间,如果没有重叠,检索时可能丢信息。有一点重叠,回答会稳一些。
再看索引部分。
vectorizer = TfidfVectorizer(
analyzer="char",
ngram_range=(2, 4),
max_features=80000
)
这里没有用默认的英文单词切分,而是用了 char 级别的 2 到 4 字符片段。
原因很简单:中文不像英文那样天然用空格分词。如果直接按单词切分,效果会很差。char ngram 虽然不高级,但很实用,尤其适合做一个轻量版中文文档搜索。
比如一句话里有人工智能风控系统,char ngram 会拆出人工、工智、智能、风控、系统、人工智、智能风控之类的特征。这样用户问智能风控相关内容时,就更容易匹配到对应片段。
检索部分是这几行:
question_vec = vectorizer.transform([question])
scores = cosine_similarity(question_vec, matrix).ravel()
top_indices = np.argsort(scores)[::-1][:top_k]
用户的问题会被转成同样的 TF-IDF 向量。
然后用 cosine_similarity 计算这个问题和所有 PDF 片段之间的相似度。
分数越高,说明这个片段越可能和问题相关。
最后取分数最高的 top_k 个片段,交给大模型。
为什么不直接把 PDF 全部发给大模型
很多人第一次做文档问答,容易想到一个简单办法:直接把 PDF 全文复制给模型,然后让模型回答。
如果 PDF 只有一两页,这当然可以。
但只要文档稍微长一点,就会遇到几个问题。
第一,输入太长,模型处理慢。
第二,成本高。如果用云端 API,长文档会消耗更多 token。
第三,回答不稳定。模型看到的信息太多,反而可能抓不住重点。
第四,不方便追溯。模型回答了一个结论,但你不知道它参考了 PDF 的哪一页。
所以更好的方式是:先检索,再回答。
也就是这条链路:
用户问题 -> 找相关片段 -> 把片段交给模型 -> 生成答案
这也是很多知识库问答系统的基础思路。
提示词怎么写
这个项目里,提示词比想象中重要。
如果直接把片段和问题丢给模型,它可能会发挥过头。它会根据自己的知识补充内容,看起来回答得很完整,但不一定来自 PDF。
所以我在 build_prompt 里加了几个约束:
请只根据下面给出的资料片段回答问题。
如果资料片段里没有答案,请直接说:根据当前 PDF 内容,暂时找不到明确答案。
不要编造资料片段之外的信息。
这几句话的作用是限制模型胡说。
当然,它不能百分百杜绝幻觉,但会明显好一些。
做文档问答时,我个人比较喜欢让模型保持克制。宁愿它说找不到,也不要它编一个看起来很像真的答案。
这个版本有哪些不足
这个小工具已经能用,但它只是第一版。
它的不足也很明显。
第一,检索还不是语义检索。
现在用的是 TF-IDF。它更偏关键词匹配。如果用户问法和文档表达差异很大,可能找不到最合适的片段。
比如文档里写的是营收增长,用户问的是收入变多,这种情况下 TF-IDF 不一定能很好匹配。
后面可以换成 Embedding。Embedding 可以把文本变成语义向量,表达相近但字面不同的内容,也更容易被找出来。
第二,没有 OCR。
如果 PDF 是扫描版图片,这个版本提取不到文字。要解决这个问题,需要加 OCR,比如用 Tesseract、PaddleOCR 或云端 OCR 服务。
第三,没有做表格解析。
很多 PDF 里的核心信息在表格里。PyMuPDF 可以取出页面文本,但复杂表格的结构不一定能保留。后面如果要认真做财报、合同、论文表格分析,就要单独处理表格。
第四,没有历史对话。
现在每次提问都是独立的。如果想做成真正的聊天式 PDF 助手,可以把历史问题和回答放到 session_state 里,再一起传给模型。
第五,没有持久化索引。
现在每次上传 PDF 都会重新建立索引。如果文档很多,后面应该把索引保存到本地,比如保存成 pickle 文件,或者进一步换成向量数据库。
可以怎么改进
如果你想继续升级这个项目,我建议按这个顺序来。
第一步,把 TF-IDF 换成 Embedding。
比如用 sentence-transformers 做本地向量化,或者调用大模型服务商的 embedding API。
第二步,引入向量数据库。
小项目可以用 FAISS,大一点可以用 Chroma、Milvus、Qdrant。
第三步,增加多 PDF 支持。
让用户上传多份文档,然后跨文档提问。
第四步,加入页码跳转。
现在只能显示页码和片段。更进一步,可以把原 PDF 页面渲染出来,点击参考片段时直接跳到对应页。
第五步,加入回答质量评估。
比如检查回答有没有引用原文,回答是否遗漏关键信息,模型是否说了资料中没有的内容。
这样一步步做下去,就会从一个小工具,慢慢变成一个真正可用的知识库问答系统。
我对这个项目的理解
做完这个 PDF 问答助手之后,我最大的感受是:很多 AI 应用看起来神奇,拆开之后并没有那么玄。
它不是把 PDF 扔给模型,然后模型突然什么都懂了。
更真实的流程是:
先把资料整理好。
再把资料切成合适的小块。
然后用检索方法找到和问题相关的部分。
最后让模型基于这些部分组织答案。
大模型负责的是理解和表达,但前面的数据处理、检索、约束和工程细节,决定了这个工具到底好不好用。
所以,做 AI 应用开发,不是只会调一个 API 就够了。Python 基础、文本处理、机器学习、工程化思维,都会派上用场。
这个项目虽然小,但它已经包含了文档问答系统最核心的几个环节。
如果你也想入门 AI 应用开发,我不建议一开始就啃一堆框架。先用 Python 把一个最小可用版本写出来。等你知道每一步为什么存在,再去学 LangChain、向量数据库、Agent,理解会快很多。
