 夜雨聆风
夜雨聆风安装插件并导入工作流:在ComfyUI管理器中搜索 VoxCPM TTS 并安装。进入
\custom_nodes\ComfyUI-VoxCPM\example_workflows\,将VoxCPM-example.json拖入界面,立即 Ctrl+S 保存。下载模型文件:从国内镜像
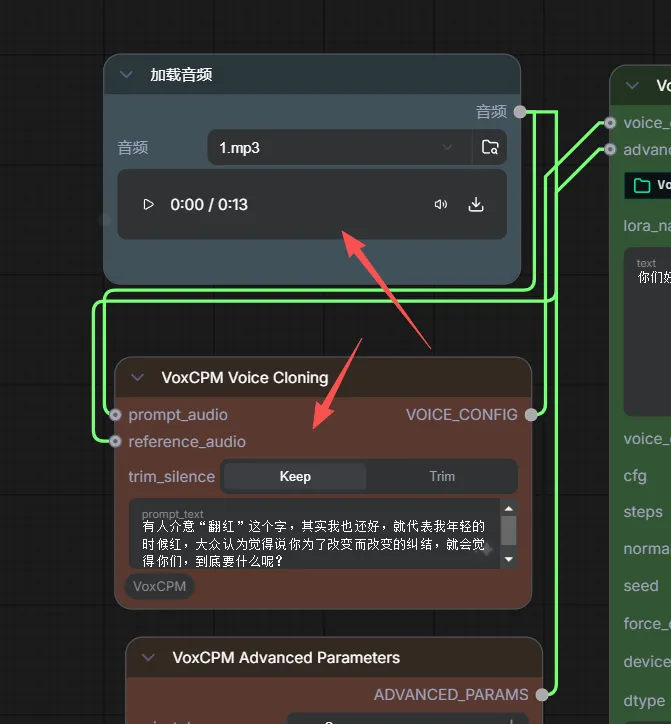
https://hf-mirror.com/openbmb/VoxCPM2/tree/main下载 VoxCPM2 全部文件。放入\models\TTS\VoxCPM\VoxCPM2(没有则手动新建)-。首次使用节点时会自动下载模型,自动下载失败才手动操作。配置工作流节点:加载音频处选中你的录音(约10秒),VoxCPM Voice Cloning 的
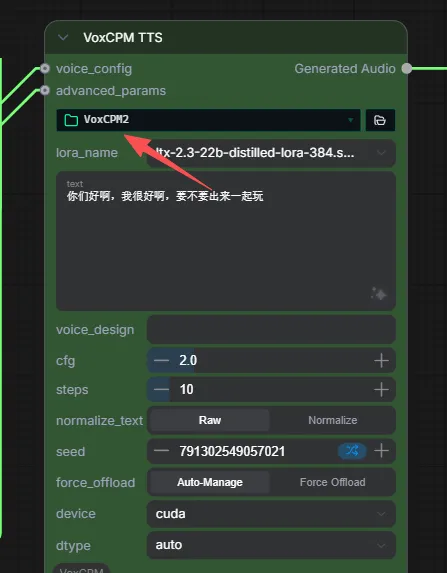
model选VoxCPM2,lora_name先选none,transcript处填充音频的内容以辅助模型对齐-。text 处输入想要克隆生成说的文本。保存音频节点默认每次运行自动保存到\output\audio。运行并验证:点击 Queue Prompt 运行,听一下效果。成功克隆后,你就能为后续的 视频截取 ➔ 人声分离 ➔ 声音克隆 高阶操作打下基础啦!
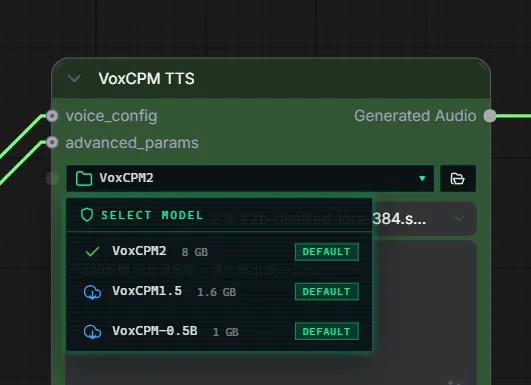
把他里面的示例拖进来工作流在comfyui这个路径\custom_nodes\ComfyUI-VoxCPM\example_workflows\VoxCPM-example.json 保存下 你会看到他这个位置要选模型的
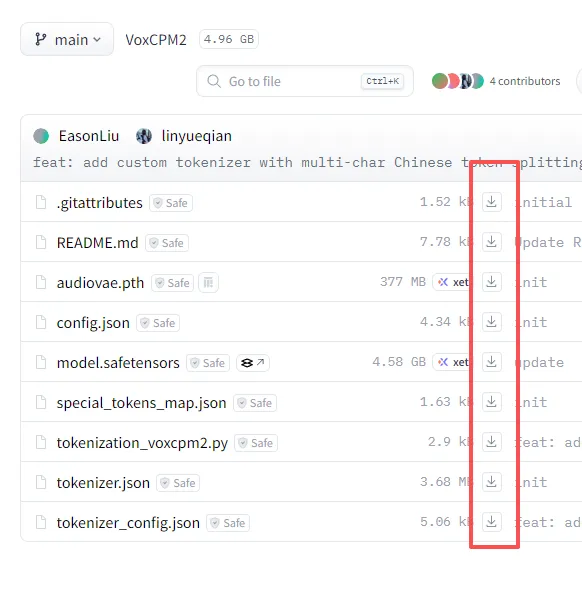
我是直接下voxcpm2 ,因为没多大,路径在这里 https://hf-mirror.com/openbmb/VoxCPM2/tree/main
| VoxCPM2 | 约 8 GB-- | ||
| VoxCPM-1.5 | 约 1.6 GB- | 显存<12GB 时可使用该版本。 | |
| VoxCPM-0.5B | 约 1 GB |
你要是没git,就一个一个下下来,放进models的这个文件里 \models\TTS\VoxCPM\VoxCPM2 你看到没有的文件名你就自己新建个
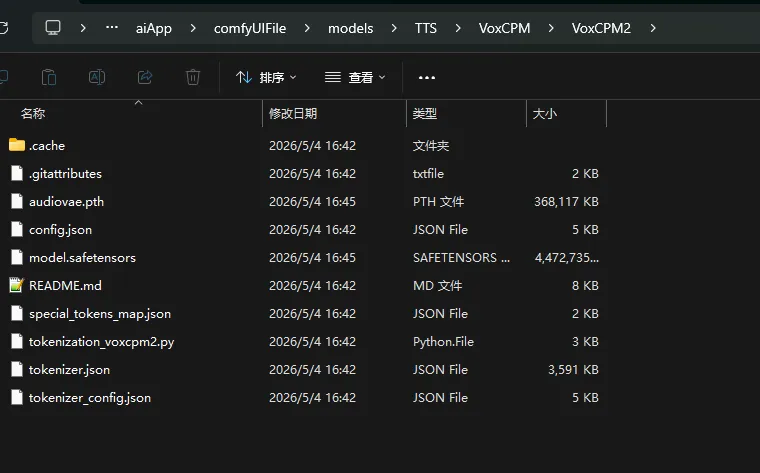
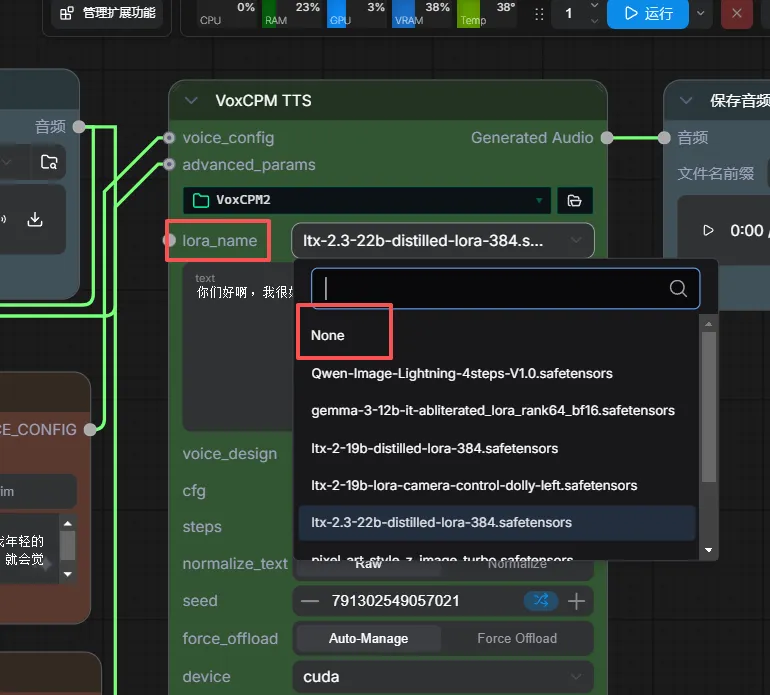
好,你保存下工作流,然后重启comfyui 说下具体操作 你自己录一个说话的音频放进去。 为了我们流程先跑通demo 你就随便说几句话,10秒钟 然后下图这个加载音频选中进去你录的音频 VoxCPM Voice Cloning 这个选修是填你音频里面说了什么,他要核对
模型选VoxCPM2 lora_name你直接先none就好了 下面text文本是你要用克隆的声音说些啥
雪狼之夜ps:既然都看到这行了,不如给个3连,亲~~~
☟
