 夜雨聆风
夜雨聆风专注能源AI应用,关注MEVR·微源虚境。

电费单AI小工具复盘:为什么原生对话框能做,API工具却做不好?
1、工具已上线:完成比完美重要
上一篇,我们聊到了电费单AI小工具打造的一些过程,但还没讲完,这一部分我们继续。
不过还是要插一嘴,目前这个工具已经发布到网上了,基本上使用起来没问题,毕竟AI时代,完成比完美重要。
体验地址:
https://mevr.com.cn/tools/electricity-bill-demo.html
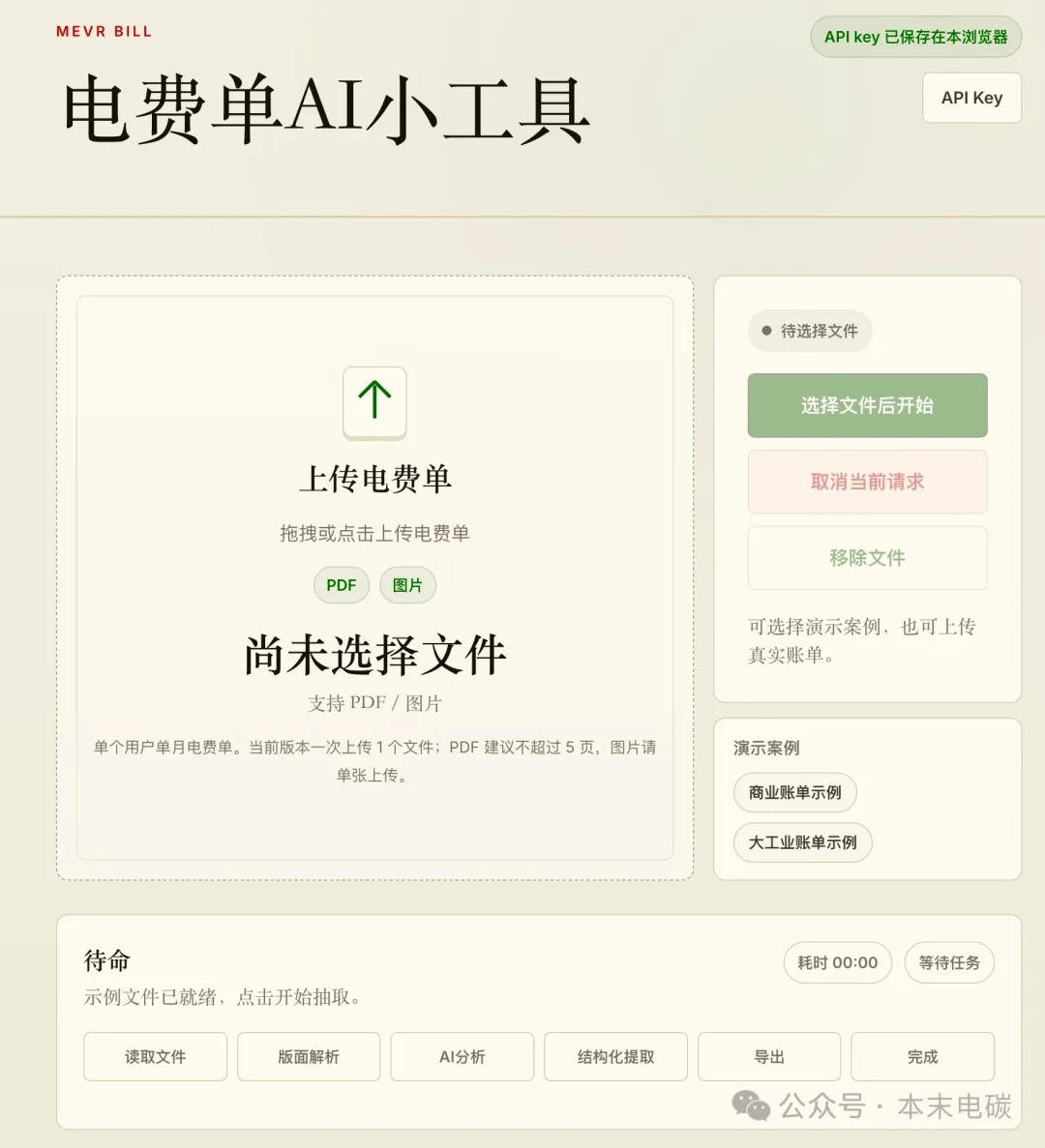
我们回到正题,上一期讲到,为什么电费单这种东西,你给一流的AI大模型处理,它是没问题的,但是你调用API,自己做工具,它就不行了呢?
咱也不是程序员啊,当然搞不懂工程原理,但最好的程序员不就在身边么?!问AI就行。
AI一下就回答清楚了:
原生对话框是一个已经被产品化、工程化、工具化的大模型系统;API只是一个能力接口。把接口接进自己的小工具,并不会自动继承原生产品里的全部工程能力。
清楚吧,简单吧,但你没做过,就是不知道,不知道就会做不好。
2、原生对话框和API工具,差在工程化
以“电费单AI小工具”为例进一步分析,我在原生对话框里上传电费单,模型往往能看懂,因为它背后通常已经有一整套产品能力:文件上传、图片识别、表格解析、上下文补全、对话式追问、代码分析、格式化输出、异常容错。
OpenAI官方对ChatGPT数据分析能力的描述里,也明确提到它可以分析上传文件、生成表格或图表,并建议用户提供清晰列名、说明计算和分组需求。文件上传能力本身也被设计用于文档、表格、图片等内容的综合分析。
但我自己调用API做工具时,情况会变成另一个问题。API并不能直接“把ChatGPT搬到你的工具里”,它更像是给你一台发动机。
发动机很强,但车架、方向盘、刹车、传动系统、仪表盘、维修机制,都要你自己搭。OpenAI的API文档也把文件输入、文本生成、结构化输出、函数调用等拆成不同能力,开发者需要自己组合。
Responses API可以处理文本和图像输入,也支持文件、工具和函数调用,但如何把这些能力组织成稳定产品,是开发者自己的工程工作。
所以,电费单这种看似简单的东西,真正难点不在于“模型认不认识电费单”,关键在于前后链路是否稳定。
再回到电费单本身,对于有相关工作经验的朋友来说,看电费单不是什么大问题,但实际上电费单本身很复杂,尤其是当你试图教会AI时。
不同省份、不同供电公司、不同用户类型,格式都可能不一样。居民电费、工商业电费、分时电价、基本电费、需量电费、力调电费、功率因数考核、峰平谷尖用电量、变压器容量、市场化交易电费、代理购电电费、政府性基金及附加,这些字段经常分散在不同位置。有些是表格,有些是小字,有些是截图,有些是PDF扫描件,有些字段名还不规范。
在原生对话框里,用户会天然“补充上下文”。比如你看到结果不对,会继续问:“这个基本电费是不是算错了?”“这里应该是峰段电量。”“你再看一下第二页。”对话框可以通过多轮交互修正理解。
可是做成工具以后,用户的期待会变成“一键上传,一次出结果”。这时候,系统不能依赖用户帮它修正,它必须自己完成识别、校验、追问、纠错、输出。
这就是产品和玩具的区别。
3、失败点在哪里:从Demo到产品的距离
调用API时,常见失败点大概有几类。
第一,输入质量没处理好。图片模糊、PDF多页、票据旋转、扫描阴影、表格断裂、字段位置不固定,都会影响模型理解。原生产品可能已经做了很多隐性处理,但我的小工具如果只是把图片直接丢给模型,效果会非常不稳定。
第二,提示词太像聊天,不像流程。你对模型说“帮我分析电费单”,在对话框里问题不大,因为人可以继续补充。但在工具里,这句话太宽泛。工具需要把任务拆成明确流程:先识别基础信息,再提取关键字段,再判断用户类型,再校验电费结构,再计算单价,再输出诊断结论。每一步都需要规则。
第三,输出没有结构约束。模型在聊天中可以自由发挥,但产品需要稳定字段。比如月份、户号、总电量、尖峰平谷电量、基本电费、力调电费、平均电价、异常项、优化建议,都应该有固定格式。OpenAI官方也提供了结构化输出能力,用来让模型输出匹配JSON Schema的结果,提高程序可解析性。
第四,缺少校验机制。电费单分析不能只靠“看起来合理”。比如总电量应该等于尖峰平谷电量加总,平均电价应该等于总电费除以总电量,需量电费应该和最大需量或容量计费方式对应,税费和基金附加要能解释。没有这些校验,模型即使提取出字段,也可能产生各种各样的幻觉。
第五,缺少领域知识库。电费单不是通用票据,它背后是电价政策、交易规则、用电类别、分时机制和地方规则。一个通用大模型能读懂表面文字,但要判断“贵在哪里”“是否异常”“怎么优化”,就需要把地区规则、行业经验和计算公式接进去。这里就从“AI识别工具”升级成“电费诊断系统”了。
所以我当时在开发日志中写道:偏专业技术一点的AI产品,不能只靠vibe coding。
vibe coding可以帮你快速搭一个Demo,让你看到“好像能跑”。但真正能用的产品,需要工程思维。工程思维的核心,是把一个模糊问题拆成稳定流程,把一次成功变成持续成功,把模型的聪明变成系统的可靠。
放到电费单AI小工具里,它至少需要四层结构。
第一层是文档处理层。解决图片、PDF、表格、扫描件、多页账单的输入问题。
第二层是信息抽取层。把电费单中的字段结构化,形成机器可读的数据。
第三层是规则校验层。用电量、电费、单价、分项费用之间要能互相验证。
第四层是业务诊断层。判断电费高在哪里,是否存在需量优化、分时优化、功率因数优化、储能配置、交易代理、负荷调整等机会。
这四层都做好以后,AI才真正从“会聊天”变成“能干活”。
4、能源AI产品真正的门槛
我关注的很多能源场景都有嵌入AI的机会,平时有空就尝试着vibe coding,比如政策库问答、微电网收益测算、项目可研生成、储能收益诊断、虚拟电厂资源调度。
但这些事情都不能只停留在“把资料丢给大模型”。真正有价值的地方,往往在于能不能把行业知识、数据结构、计算逻辑、输出模板、校验规则和用户场景封装成一个流程。
也就是说,AI产品的门槛不只在“模型是不是强”,还在“你有没有把专业问题工程化”。
原生对话框像一个非常聪明的顾问,你可以边问边改。API工具像一个自动化员工,你必须提前写清楚岗位职责、工作流程、交付标准、复核机制和异常处理方式。
所以,咱们这个电费单AI小工具的失败,其实是一次很有价值的产品认知升级。
它提醒我们:AI应用的核心壁垒,可能不在“我能不能调用大模型”,关键在于“我能不能把一个专业任务拆成可执行、可校验、可交付、可复用的系统”。
这也正好解释了为什么很多AI工具Demo很惊艳,真正上线就变得鸡肋。Demo只需要证明“有一次能做对”,产品需要保证“大多数情况下都能做对,做错了还能发现,发现了还能修正,修正后还能沉淀”。
最后再扩展一下,其实解决这个问题的方法有很多,以前的“套壳”产品特别多,其实背后还是其他大模型的对话框,相当于转接了一层。
现在我们有2个选择,一是agent,定好目标,它会自动拆解任务,高效完成。
二是skills,即技能,可以把每个环节的能力封装为可被调用的文件,重复且高效地使用,和agent配合更好。
这个之后再慢慢分享给大家吧。
