夜雨聆风
夜雨聆风凌晨三点,你早已进入梦乡,而你的GPU却正在疯狂运转。它不是在做无聊的挖矿,而是在正儿八经地搞科研——改代码、跑实验、调参数、记结果。第二天早上你揉着眼睛打开电脑,发现它已经帮你完成了83次实验,其中15次还真就把模型性能给提上去了。
这不是科幻片,这是Andrej Karpathy(就是那个OpenAI联创、前Tesla AI总监)最近在GitHub上开源的autoresearch项目。上线短短几天就狂揽近4万星标,Shopify CEO Tobi Lutke实测后惊呼:睡了一觉,模型质量提升了19%!
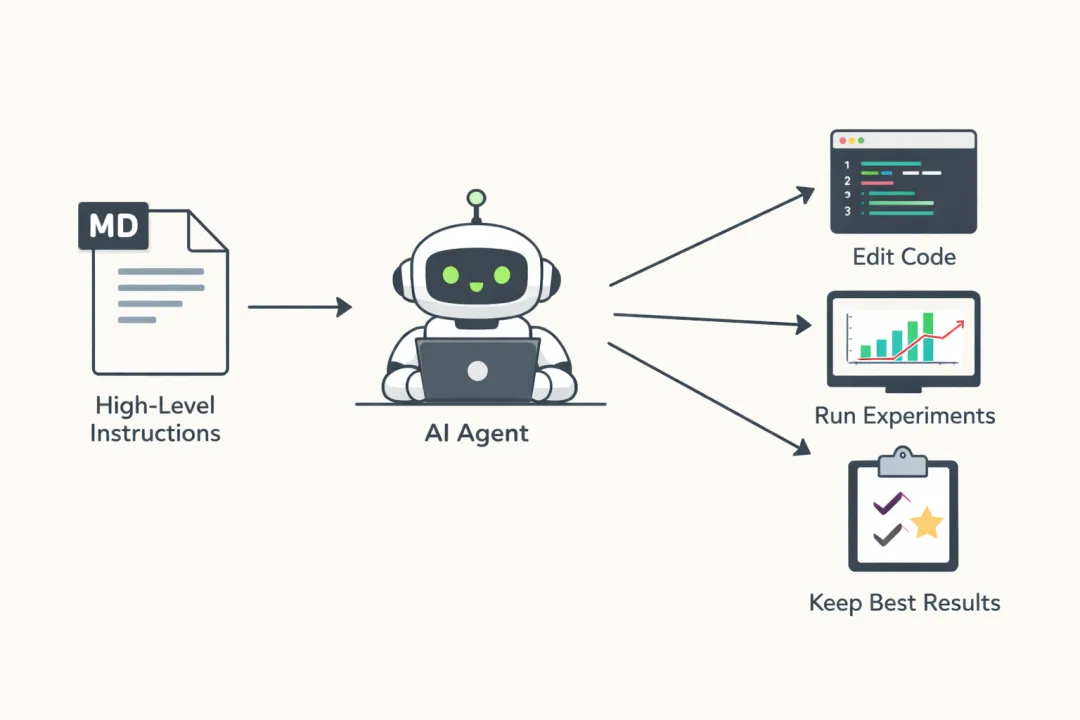
这玩意儿到底在搞什么?
简单说,autoresearch就是一个**"AI研究员的极简实验室"**。以前咱们炼丹调参,得自己改代码、盯日志、看曲线,折腾一晚上可能也就跑个三五组实验。现在好了,你把任务丢给AI Agent,它自己就会去改训练代码、跑5分钟实验、看验证损失降没降。降了就保留,没降就回滚,循环往复一整夜。
Karpathy把这个过程叫做**"后AGI时代的感觉"**——人类只需要设定研究方向,具体的脏活累活全交给AI。
整个项目就630行Python代码,核心逻辑简单到离谱:只给Agent一个文件train.py去改,固定5分钟训练时间,只看val_bpb(验证集bits per byte)这一个指标。越低越好,公平可比。
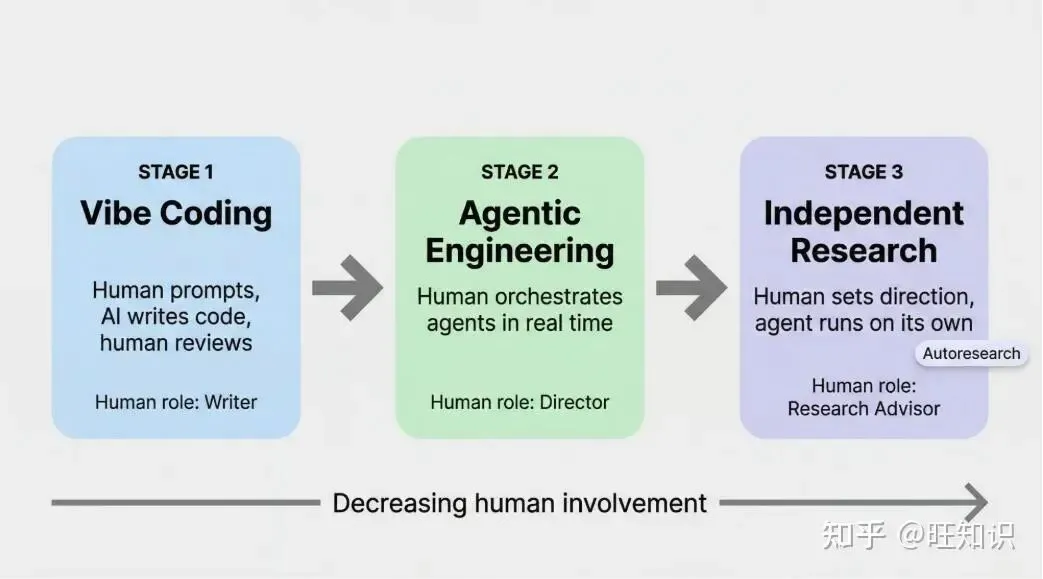
三个文件走天下:
prepare.py:准备数据和分词器,人类准备好后Agent不动它train.py:Agent的地盘,模型架构、优化器、学习率全在里面,随便改program.md:人类的指挥棒,你用自然语言写研究目标,Agent读这个文件知道要干啥
这张图就是Karpathy自己跑出来的结果。绿点是保留的改进,灰点是废弃的尝试。你可以清晰看到Agent一步步把验证损失从0.998压到了0.977,中间尝试了调整batch size、学习率 warmup、RoPE频率等各种 trick。
手把手教你搭起来
别看概念挺唬人,实际上手贼简单。你需要的就是一块NVIDIA显卡(H100效果最好,但RTX 4090也能玩)、Python 3.10+,还有uv这个超快的Python包管理器。
第一步:装uv
curl -LsSf https://astral.sh/uv/install.sh | sh
第二步:拉代码装依赖
git clone https://github.com/karpathy/autoresearch.git
cd autoresearch
uv sync
第三步:准备数据这一步会下载FineWeb数据集(一个去重过的网页文本数据集),然后训练一个BPE分词器。大概需要2分钟,一次性的,以后就不用管了。
uv run prepare.py
第四步:手动试跑一遍先确认环境没问题,手动跑一个基线实验:
uv run train.py
看到终端开始刷日志,loss在降,就说明准备好了。整个过程正好5分钟,喝口咖啡的功夫。
第五步:召唤AI Agent这是最有意思的部分。打开你的Claude Code、OpenAI Codex或者Cursor,记得把权限都关了(让它只能读写文件和执行训练命令,别给它开浏览器权限啥的)。
然后给它看这个prompt:
Hi have a look at program.md and let's kick off a new experiment! let's do the setup first.
接下来就不用管了。Agent会读取program.md里的指令,开始它的表演。它会自己打开train.py研究代码,提出改进假设(比如"把学习率从0.004调到0.008试试"),修改代码,跑5分钟,看结果。如果val_bpb降了,它就git commit保存;如果没降,就checkout回滚。
你完全可以去睡觉。第二天早上,git log里会有一串提交记录,告诉你昨晚Agent都做了啥尝试。运气好的话,你的模型已经悄悄变强了。
为什么固定5分钟?
这里有个特别反直觉的设计:不管你的GPU多强,每个实验只跑5分钟。
Karpathy解释说这样做有两个好处。一是公平比较——不管Agent把batch size改多小、模型改多深,大家都训5分钟,比的是单位时间内的效率。二是适配你的硬件——在H100上5分钟能跑的步数,和在小卡上不一样,这样Agent会自动为你当前的硬件找最优配置。
代价就是你没法跟别人比绝对指标,只能跟自己比。不过对于个人研究者来说,这反而是好事儿。
小卡也能玩吗?
官方说只测了H100,但社区早就适配了各种平台。有Mac版的fork(用MLX框架),有Windows+RTX版,甚至还有AMD显卡的版本。
如果你只有消费级显卡(比如4060/4070),可以这么调:
改 prepare.py里的MAX_SEQ_LEN,从默认的1024降到256甚至128把 vocab_size从8192降到4096或更小,甚至直接用256个byte-level token改 train.py里的DEPTH(模型深度),从默认8层降到4层用TinyStories数据集(简单的儿童故事)代替FineWeb,数据熵低很多,小模型也能出效果
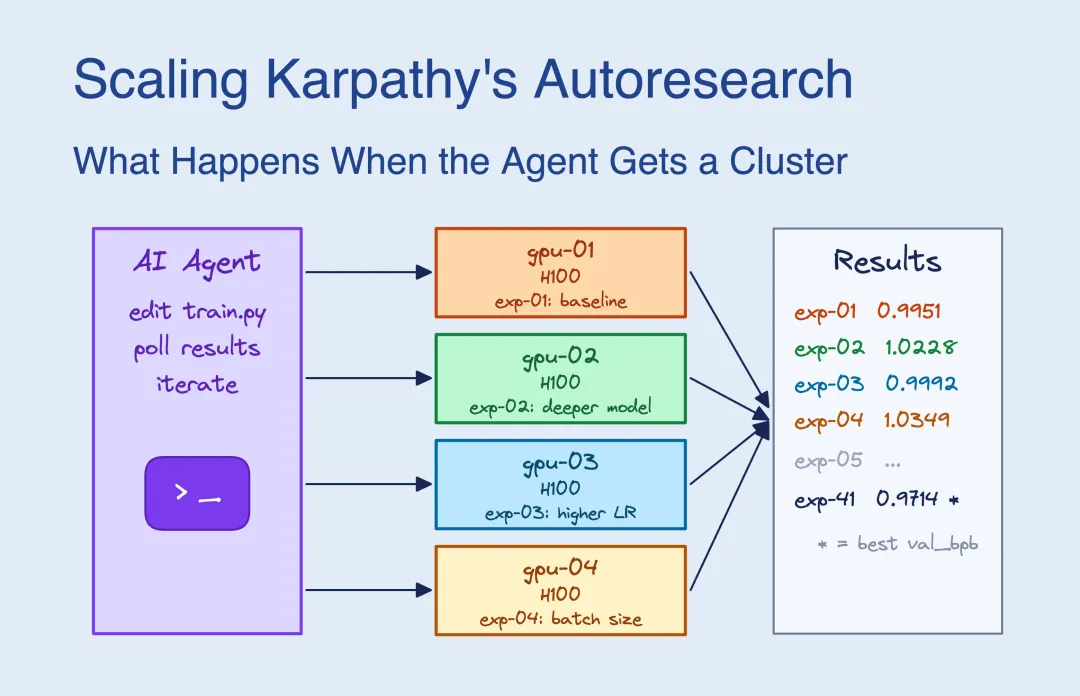
有人甚至把autoresearch扩展到了多卡集群上,让Agent同时跑多个实验,效率直接翻倍。
这到底意味着什么?
Karpathy在README开头写了一段挺科幻的引言(虽然标注了是2026年3月的虚构场景):
"曾几何时,前沿AI研究还得靠碳基大脑完成:大家吃饭、睡觉、摸鱼,偶尔再用声波互联开个叫'组会'的仪式同步一下进度。那个时代早已远去。如今,研究完全是自主AI Agent的天下...本仓库记录的,便是这一切的开端。"
说白了,autoresearch不只是一个工具,它展示了一种新的研究范式。以前是人写代码、人调参数,现在是人定方向、Agent执行。就像从手写汇编进化到高级语言,现在又要从手写代码进化到自然语言指令。
不过也别太激动,它现在还是个"周末玩具"。单卡实验的规模有限,Agent偶尔会犯蠢(比如改出个完全不能跑的代码),而且目前只支持语言模型训练。但对于学生、独立研究者、小团队来说,这简直是神兵利器——以前需要一个实验室干的事儿,现在一张卡就能跑起来。
而且想想看,这才630行代码啊。Karpathy又一次证明了,复杂的从来都不是代码量,而是想法本身。
如果你也想体验一下"人在睡觉,AI在干活"的感觉,不妨去试试。说不定第二天早上,你也能收获一个更好的模型,还有一整个晚上的实验日志等着你去翻阅。
GitHub地址:
https://github.com/karpathy/autoresearch
专注分享 GitHub知识,分享AI 资讯和AI搞米经验,分享AI Agent使用经验。

想领取完整版OpenClaw资料,围观朋友圈,一起交流AI的,可加我VX,备注“github"。