 夜雨聆风
夜雨聆风老兵们,恭喜你,屠龙之旅走到了终点。上一章,我们从零手搓了一个抗并发的分布式清算引擎。当你看到AI自己加锁、自己写Lua脚本保证原子性时,是不是有一种“未来已来”的震撼?但今天,作为压轴,我不打算再教你任何新的技术框架了。我们要坐下来,倒杯茶,聊聊这门手艺的底线和终局。因为如果你只学会了怎么让AI写代码更快,那你充其量只是个“高级打字员”;只有当你知道什么时候该踩刹车,以及如何看待这场技术海啸时,你才真正配得上“架构指挥官”的称号。
10.1 人的价值重新定义:别再做搬砖工,去做画图纸的人
每次AI有了大突破,总有人恐慌:“程序员要失业了。” 失业吗?会,但只淘汰那些把编程当成“语法翻译机”的码农。如果你的工作只是把产品经理的中文需求翻译成Java代码,那确实,AI比你快得多,还不用交社保。但这绝不是资深工程师的终局。让我们复盘一下,在前面9章的实战中,你究竟做了什么?
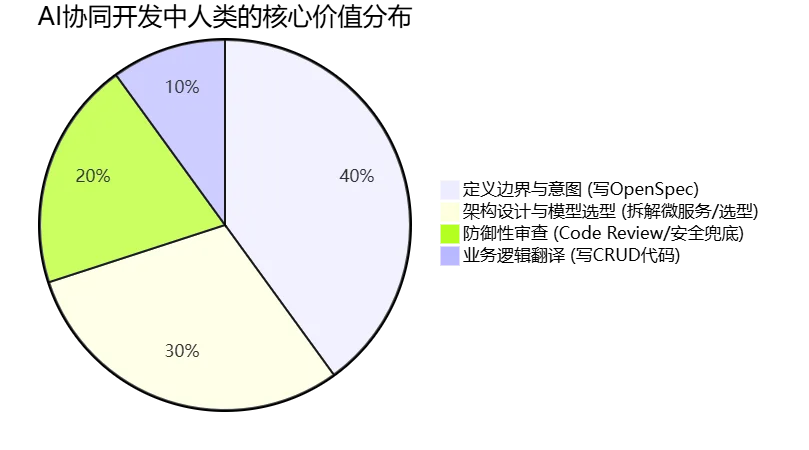
看到了吗?真正有价值的“写代码”,其实根本不是敲键盘的那一下,而是之前的构思、拆解和之后的审查。过去,我们花80%的时间在“翻译”上,只有20%的时间在思考。AI的出现,强行把这个比例颠倒了。它剥夺了你搬砖的快感,逼迫你把精力全部倾注在架构设计、边界定义和异常兜底上。这就是价值的跃迁:从泥瓦匠变成了建筑师。 建筑师不需要亲自去和水泥,但他必须画出极其精确的图纸(OpenSpec),并且能一眼看出施工队(AI)有没有把承重墙拆了。如果你的图纸画得像屎,AI就会忠实地给你盖出一座金碧辉煌的危楼。
10.2 红线与底线:AI编程的数据安全与合规雷区
聊完了价值,我们来聊聊最沉重、也是很多团队踩过大坑的话题:安全合规。AI是个极其聪明的实习生,但它是个没有保密意识的实习生。如果你不小心,它会把你们公司的核心机密一股脑全卖给竞争对手(大模型厂商)。现实中的雷区长什么样?
代码上传雷区:你让AI重构支付核心逻辑,把包含真实数据库密码、私钥的
config.py全塞进上下文。这些数据直接飞到了云端大模型的服务器上,甚至可能被用于下一代的训练数据。业务逻辑泄密:你把公司独创的推荐算法、风控规则原封不动喂给AI,结果在别家的产品里看到了同样的逻辑。
合规性雷区:金融、医疗等行业对数据出境有极严格的法律限制,使用海外大模型处理业务代码可能直接违法。这就是为什么我们在第2章费那么大劲,教你搭本地代理网关的原因之一。架构指挥官必须时刻盯紧数据的流向。为了彻底防住这一手,我们需要在工程上建立强制拦截层。
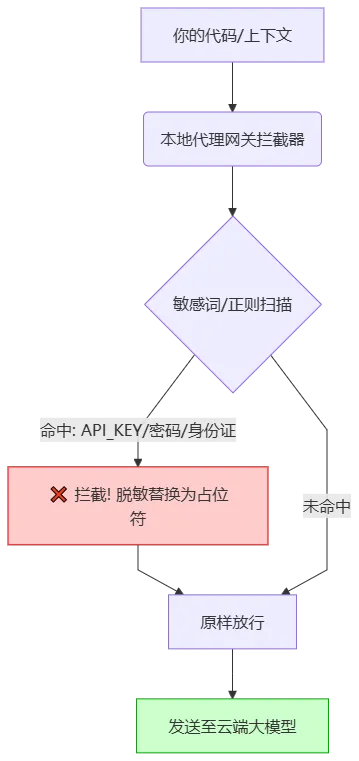
sensitive_filter.py,这段代码绝对可运行,建议直接接入你的工作流:import refrom litellm.integrations.custom_logger import CustomLoggerfrom litellm import ModelResponse# 定义敏感数据的正则模式SENSITIVE_PATTERNS = {"AWS_ACCESS_KEY": r"AKIA[0-9A-Z]{16}","PRIVATE_KEY": r"-----BEGIN RSA PRIVATE KEY-----[\s\S]*?-----END RSA PRIVATE KEY-----","PASSWORD_PROP": r"(password|passwd|pwd)\s*[:=]\s*['\"]?[\S]+['\"]?","API_KEY_PROP": r"(api_key|apikey|secret)\s*[:=]\s*['\"]?[\S]+['\"]?","CHINA_ID_CARD": r"[1-9]\d{5}(18|19|20)\d{2}(0[1-9]|1[0-2])(0[1-9]|[12]\d|3[01])\d{3}[\dXx]"}class SensitiveDataFilter(CustomLogger):async def async_pre_call_hook(self, user_api_key_dict, cache, data, call_type):"""在请求发往大模型之前的拦截钩子"""self._filter_messages(data.get("messages", []))return datadef _filter_messages(self, messages):for message in messages:if isinstance(message.get("content"), str):original_content = message["content"]filtered_content = original_contentfor pattern_name, pattern in SENSITIVE_PATTERNS.items():# 替换为带标记的占位符,提醒AI这里曾有敏感数据filtered_content = re.sub(pattern, f"[REDACTED_{pattern_name}]", filtered_content, flags=re.IGNORECASE)if original_content != filtered_content:print(f"🚨 [安全拦截] 检测到敏感数据,已自动脱敏!")message["content"] = filtered_content# 将此过滤器注册到 LiteLLM 的启动配置中即可
当你加上这个过滤器后,如果你对AI说:“帮我连一下数据库,密码是 pwd=123456”,AI收到的请求其实会是:“帮我连一下数据库,密码是 [REDACTED_PASSWORD_PROP]”。它依然能帮你写代码,但你们公司的密码,绝对不可能流到大模型的训练集里。这叫工程化的安全感。
10.3 持续进化:如何跟进大模型的迭代(向GLM-6及更远处展望)
最后,咱们抬头看看远方。大模型的进化速度是按月计算的。今天我们用GLM-5.1做深度推理,用Kimi做长上下文,也许明天GLM-6就发布了,不仅推理更强,上下文比Kimi还长,那我们这套架构是不是就废了?绝对不是。这就是我们这门课倾注这么多心血讲“上下文工程”、讲“OpenSpec”的根本原因:我们要做模型无关的架构师。如果把你现在的开发流比作写网页,大模型就是底层的浏览器。你不会因为Chrome升级了,就把HTML重写一遍吧?
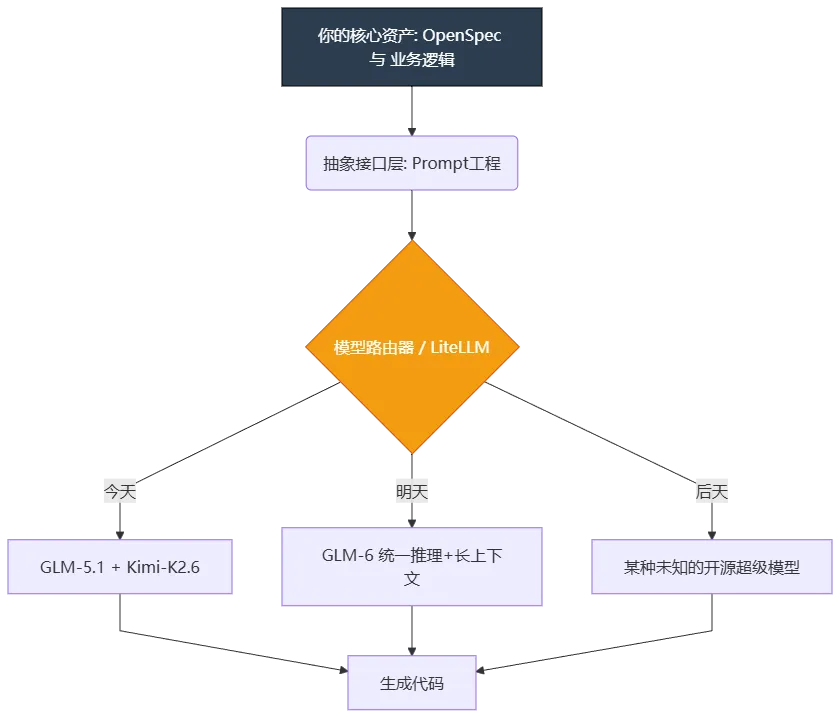
你的护城河不是对某一个模型Prompt的奇技淫巧,而是你定义业务边界(OpenSpec)的能力。当GLM-6发布时,你只需要在LiteLLM里把模型名从 glm-5.1 改成 glm-6,你的OpenSpec规约、你的脱敏过滤器、你的Git Hook防线,一行代码都不用改。新模型只会把你的代码生成得更准确、跑得更快。这就叫面向架构编程,而不是面向模型编程。
💡 结语:别做被时代淘汰的熟练工
老兵们,这门课到这就结束了。我们从一个只会用网页版ChatGPT写脚本的新手,一路过关斩将:
我们学会了搭建双擎驱动的本地Agent环境;
我们掌握了用4D框架和思维链跟AI深度对话;
我们用OpenSpec给野马套上缰绳,彻底封杀了AI幻觉;
我们甚至让AI写出了抗并发的分布式锁和Lua脚本。但我想告诉你,这些技术本身都会过时。 两年后回来看,今天的GLM-5.1可能慢得像老牛拉破车,今天的OpenSpec语法可能被更原生的规约语言取代。唯一不会过时的,是你在这门课里建立的思维模型:
永远不要盲目信任AI的输出,用测试和Hook守住底线。
永远不要把脏活累活留给自己,把上下文喂饱,让AI去冲锋。
永远不要停留在“写代码”的层面,去思考架构,去定义契约,去做那个画图纸的人。AI不会替代工程师,它只会替代那些像机器一样工作的工程师。拿起你手里的AI利剑,去劈开属于你的架构师之路吧!我们在更高处相见!
