当前时间: 1970-01-01 08:00:00
分类:办公文件
评论(0)
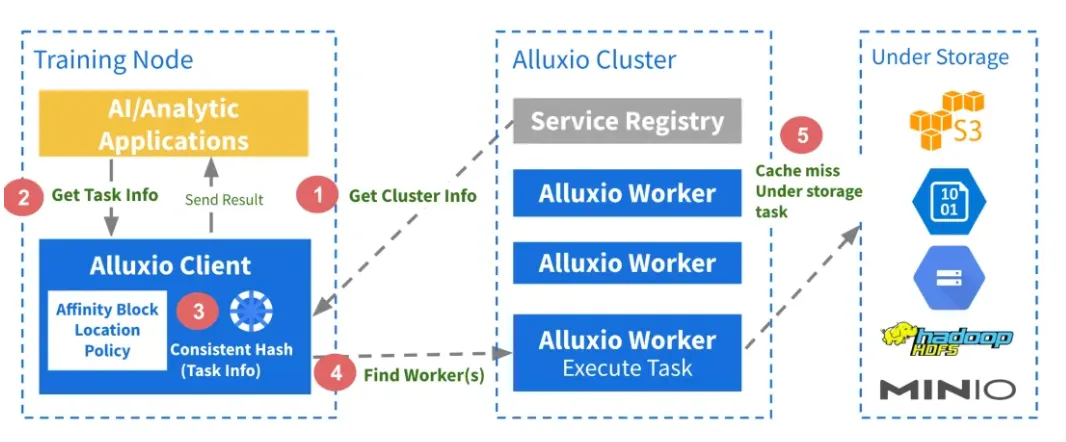
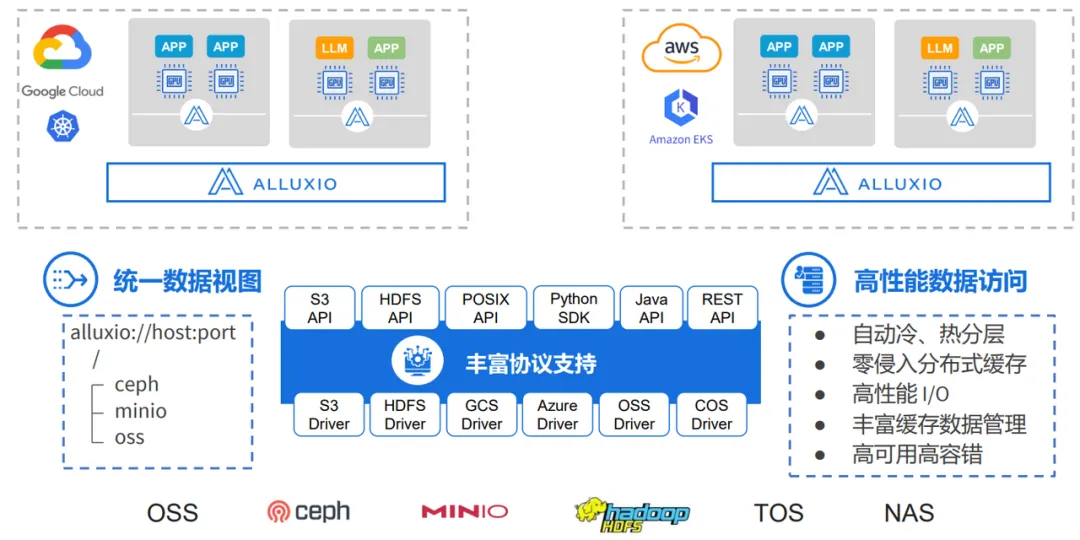
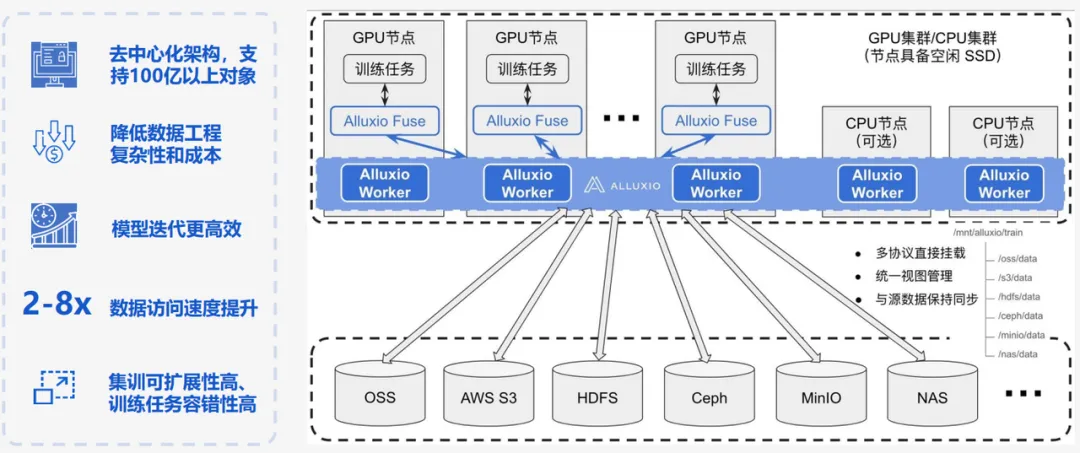
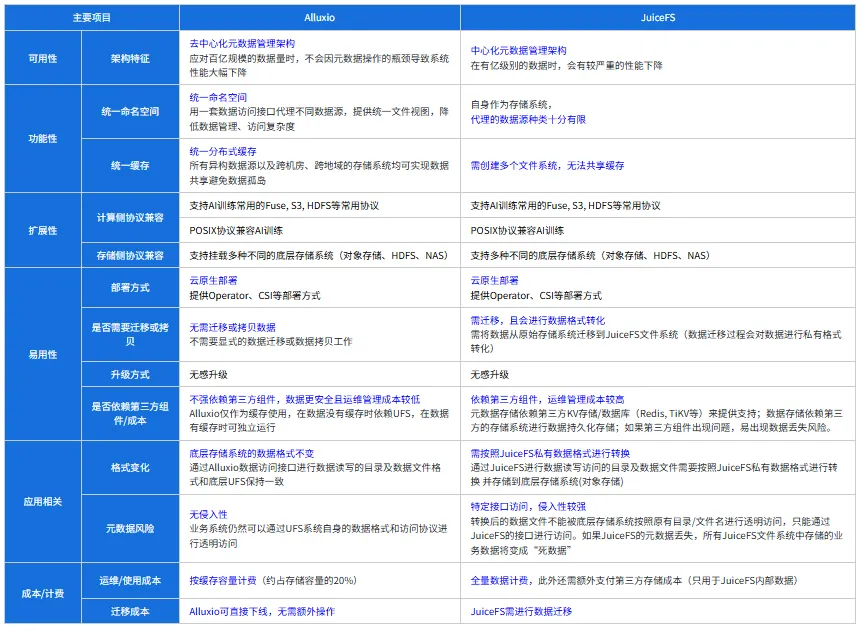
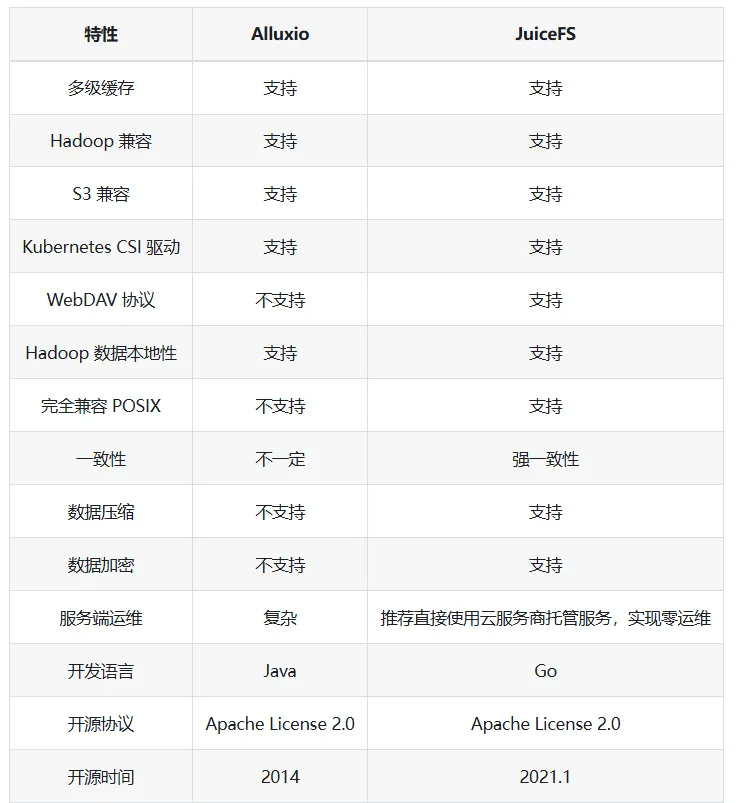
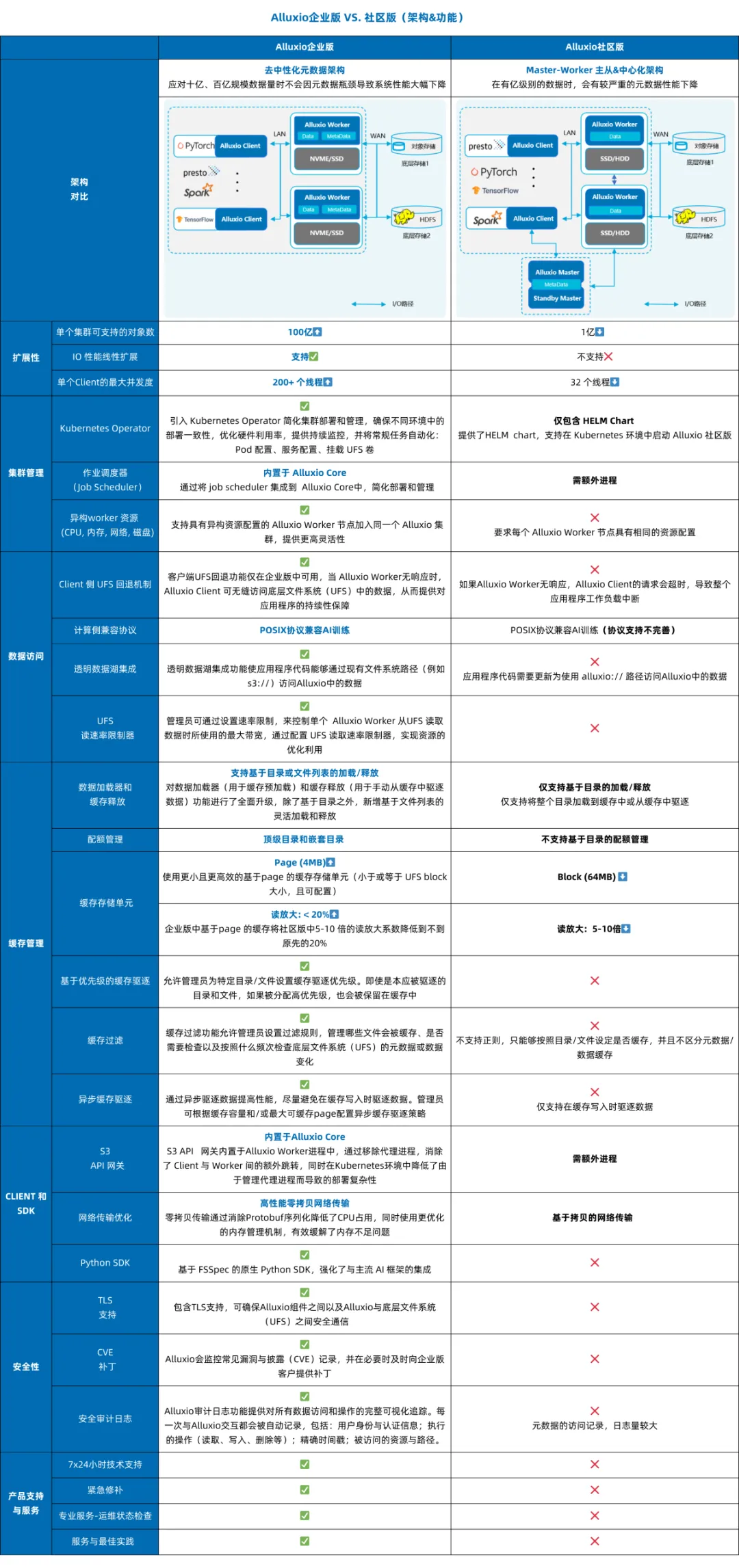
PS:AI时代,越来越木有动力总结,分享知识了,因为感觉好像价值不大? 前言 本文介绍了AI 存储选型过程中对于Alluxio的一些了解,中间间或有一些juicefs的内容,鉴于本人水平 有限, 可能有错误或者疏漏的地方,请指正。本文仅供AI存储选型过程中参考。 Alluxio架构 Alluxo Cluster √ 服务注册组件(Service Registry)负责服务发现并维护worker列表; √ W orker 是最重要的组件,它缓存共享同一个键(key)的元数据和数据,键通常是文件的路径。 √ Scheduler 处理所有异步作业,例如分布式数据加载; Under Storage √多云:S3, Ceph, HDFS等 Alluxo Client √ 客户端在应用程序内部运行 ,并通过一致性哈希算法来确定要访问哪个worker; Alluxio 核心技术亮点 多协议支持(poxis,hdfs,s3,restful,sdk) Alluxio 其他核心特性 关于这些特性的具体内容可以查看后续的版本演进相关章节 Alluxio 不支持的一些特性 Alluxio 企业版 VS. Juicefs云服务版 用户在存算分离的数据平台和 AI 训练加速场景中经常会比较 Alluxio 和 JuiceFS 两个产品。这里我只是分别列出两家各自官方自己提供的对比,仅供参考。 Alluxio 企业版 VS. 开源版 在性能 & 功能 & 稳定性等多方面开源版本与企业版 本对比均有巨大差距 如下有企业版本 VS. 开源对比 Alluxio用户案例 用户案例 - Alluxio官网 | 分布式超大规模数据编排系统 Alluxio Enterprise AI 3.7 当下,AI/ML 工作负载(如 PyTorch、TensorFlow)依赖 Amazon S3(或兼容 S3 的存储)来实现可扩展数据访问,但面临着吞吐量和延迟挑战。Alluxio Enterprise AI 通过在 GPU 旁部署 Alluxio 缓存,提供兼容 S3 接口的高性 能数据访问,实现个位数毫秒级延迟,同时保持高吞吐量,从而弥合这一差距。 降低云访问成本: 在 GPU 节点旁缓存数据,可减少高达 70% 的出口流量和 API 调用费用 个位数毫秒延迟:Alluxio相较 Stand ard AWS S3延迟最高降低45倍,相较 AWS S3 Express One Zone最高降低5倍 高吞吐量:在100Gbps网络下提供高达11.5G iB/s(98.7 Gbps)吞吐量,比同区域AWS S3读取吞吐量提升2倍 认证:支持基于 OIDC/OAut h 2.0 的认证(如 Okta、Cognito、Microsoft AD) 参考 启用身份验证 和 启用授权 了解如何启用和配置此功能。 有关如何启用该功能,请参见 无中断 FUSE 迁移 。 Alluxio Enterprise AI 3.6 该版本在模型分发、checkpoint 写入优化及多租户支持方面实现突破性创新。此次升级将帮助企业 显著缩短AI模型部署周期、减少训练时间,并确保在多云环境中的数据无缝访问。 Alluxio Enterprise AI 3.6 利用 Alluxio 分布式缓存加速模型分发工作负载。凭借服务器本地缓存与内存池优化,通过在每个区域部署 Alluxio 缓存,模型文件仅需从模型仓库复制一次到该区域的 Alluxio 缓存,推理服务器即可直接从 Alluxio 缓存中读取模型,而无需每台服务器都去模型仓库做模型拉取,基准测试表明,将一个模型文件同时分发至同一个节点上的多个 GPU 时,Alluxio AI 加速平台实现了 32 GiB/s 的吞吐量, 超出当前 11.6 GiB/s 网络带宽上限 20 GiB/s。 基于早前推出的 CACHE_ONLY 写入模式,3.6 版本新增 ASYNC 异步写入模式。在 100 Gbps 网络环境下,该模式写入吞吐量可达 9GB/s,将显著缩短模型训练过程中的 checkpoint 写入时间。通过先写入 Alluxio 缓存而非直接写入底层文件系统,该模式可避免网络与存储瓶颈。使用 ASYNC 异步写入模式时,c heckpoint 文件将异步写入底层文件系统,进一步提升训练性能。 Alluxio 3.6 引入了功能全面的基于 WebUI 的管理控制台,以提升可观测性并简化管理流程。该控制台 可展示集群关键信息,包括缓存使用情况、coordinator 与 worker 节点状态、读写吞吐量与缓存命中率等关键指标。管理员还可通过图形界面直接管理挂载表、配置配额、设置优先级与 TTL (有效时间)策略、提交缓存任务及收集诊断信息,无需使用命令行工具。 本版本通过与 Open Policy Agent (OPA) 的无缝集成,实现了强大的多租户支持。管理员现在可以通过单 一安全的 Alluxio 缓存,为多个团队定义细粒度的基于角色的访问控制。 Alluxio Enterprise AI 3.6 新增支持多可用区架构下的数据访问故障转移,确保高可用性并提升数据访问弹性。 新增的虚拟路径功能允许 用户自定义数据资源的访问路径,创建抽象层以隐藏底层存储系统中的物理数据位置。 Alluxio Enterprise AI 3.5 该版本凭借仅缓存写入模式(Cache Only Write Mode)、高级缓存管理策略以及Python的深度集成等创新功能,大幅加速AI模型训练并简化基础设施运维,助力企业高效处理海量数据集、优化AI工作负载性能。 Alluxio 索引服务(index service) —— 该项新的缓存服务针对存储数亿级文件及子目录的超大规模目录结构,显著提升目录列表操作性能。通过从缓存中直接提供目录列表详情,相比查询底层文件系统(UF S),可提供3至5倍的速度提升,有效保障海量元数据场景下的系统可扩展性。 全新缓存模式加速AI训练Checkpoint —— Alluxio 的仅缓存写入模式将AI模型训练过程中的 Checkpoint 文件等写操作数据直接写入Alluxio缓 存层,绕过低效的底层存储系统(UFS),消除I/O瓶颈,从而提升写性能。 高级缓存驱逐策略提供细粒度的缓存控制 —— TTL缓存驱逐策略: 管理员可为缓存数据设置有效时间(TTL),基于预设的策略自动驱逐低频访问数据,避免存储资源浪费; 基于优先级的缓存策略: 管理员可为关键数据集设置优先级,覆盖默认的LRU(最近最少使用)算法,确保高优先 级数据保留在缓存中。这一策略尤其适用于低延迟访问关键数据集的工作负载。 基于FSSpec的原生Python SDK强化了与主流AI框架的集成 —— Alluxio Python SDK现已基于FSSpec实现了与P yTorch、PyArrow及Ray等主流AI框架的深度集成。该集成通过提供统一的Python文件系统接口,使应用程序能够以标准化方式无缝对接各类存储后端。对于采用Python开发、特别是承载数据密集型工作负载及AI模型训练的应用而言,这一改进大幅简化了Alluxio Enterprise AI的技术对接流程,使其能够轻松实现本地与远端存储系统的快速、高频访问。 同时,新版本也也增加了以下关于Alluxio S3 API的关键优化: 支持HTTP持久连接(HTTP Keep-Alive)—— 通过复用单一TCP连接处理多个请求,减少每次请求新建连接的开销。针对4KB 大小的S3 ReadObject读取操作,该优化可减少约40%的请求延迟。 TLS加密传输 ——为Alluxio S3 API与Worker节点间通信提供TLS加密支持,确保数据传输安全。 分片上传(MPU)支持 —— Alluxio S3 API 现支持 将大文件拆分为多个分片并行上传,显著提升大文件上传吞吐量,同时简化上传流程。 UFS 读速率限制器—— 管理员可通过设置速率限制,来控制单个Alluxio Worker从UF S读取数据时所使用的最大带宽。通过配置UFS读取速率限制器,管理员可以在确保系统稳定的同时,实现资源的优化利用。Alluxio支持对包括S3、HDFS、GCS、OSS和COS在内的多种UFS类型进行速率限制。 支持异构Worker节点 —— Alluxio现支持具有异构资源配置(CPU、内存、磁盘和网络)的集群Worker节点 。该增强功能为管理员在配置集群时提供了更大的灵活性,可实现更好的资源分配。 Alluxio Enterprise AI 3.4 Alluxio Enterprise AI 3.2 3.2 版体现了 Alluxio 数据平台在充分利用GPU资源、提升I/O性能以及提供与HP C (高性能计算)存储相媲美的端到端性能方面的实力。 此外,还引入了全新的 Python 接口和更全面的缓存管理功能。这些功能可帮助企业充分利用其 AI 基础架构,确保最佳性能、高成本效益、灵活性和可管理性。 目前,AI 负载面临着诸多挑战,其中就包括数据访问速度与 GPU 计算速度之间的不匹配问题,导致 Ray、PyTorch 和 TensorFlow 等框架的数据加载速度较慢,继而导致 GPU 利用率不足。Alluxio Enterprise AI 3.2 可增强 I/O 性能并实现 97%以上的 GPU 利用率,因此能有效地应对这一挑战。此外,尽管HPC存储能提供良好的性能,但需要高昂的基础设施投入。Alluxio Enterprise AI 3.2 可利用现有数据湖,在无需额外HPC存储的情况下提供与之相当的性能。最后,管理计算和存储之间的复杂集成具有挑战性,Alluxio 新版本通过支持 POSIX、S3 和 Python 的 Python 式文件系统接口,大大简化了这一过程,不同团队都能轻松采用。 Alluxio Enterprise AI 包含以下重要功能: 随时随地利用 GPU资源, 实现高速访问和敏捷性 – 企业利用 Alluxio Enterprise AI 3.2可随时随地利用可用 GPU资源运行 AI 工作负载,是混合云和多云环境下的理想选择。Alluxio 智能缓存和数据管理功能使数据更靠近 GPU,即使数据在远端也能确保GPU的高效利用。统一命名空间简化了跨存储系统的数据访问,允许各类分布式环境 下的 AI 负载无缝运行,确保 AI 平台可扩展且不受数据位置限制。 性能与HPC存储相当 – MLPerf 基准测试显示,Alluxio Enterprise AI 3.2 可利用现有 数据湖资源,提供与HPC存储相当的性能。在BERT和3D U-Net等测试中,Alluxio在各类 A100 GPU配置上均能提供与HPC 存储相当的模型训练性能,这也证明 Alluxio 在实际生产环境中,无需额外的HPC存储设施即可满足可扩展性和效率需求。 更高的I/O性能和97%以上的GPU利用率 – Alluxio Enterprise AI 3.2增强了I/O性能,单个客户 端上可实现高达10GB/s的吞吐量和200K IOPS,并可扩展至数百个客户端。该性能表现使得单个节点上的 8 个 A100 GPU 达到完全饱和,在大语言模型训练的基准测试中实现超过 97% 的 GPU 利用率。新的 checkpoint 读/写支持优化训练推荐引擎和大语言模型,从而避免 GPU 资源的闲置。 适用于 Python 应用的新文件系统 API – 3.2 版引入了 Alluxio Python FileSystem API(FSSpec 实现),可与 Python 应用进行无缝集成。这一功能增强了 Alluxio 在 Python 生态系统中的互操作性,允许 Ray 等框架轻松访问本地和远端存储系统。 高级缓存管理,提升效率和控制 – 3.2 版提供了高级缓存管理功能,帮助管理员实现对数据的精准控制。新的 RESTful API 有助于进行无缝的缓存管理,而智能缓存过滤器(cache filter)则通过选择性地缓存热数据优化了磁盘的使用。缓存释放( cache free ) 命 令提供了细粒度的控制,可提升缓存效率,降低成本,并增强数据管理的灵活性 参考文献 Alluxio Enterprise AI 3.6 加速模型分发、优化checkpoint写入并增强多租户支持 Alluxio Enterprise AI 3.5 发布:通过创新缓存模式、分布式缓存管理以及Python深度集成,全面提升AI模型训练性能 https://documentation.alluxio.io/ee-ai-cn/ai-3.4/release-notes Alluxio Enterprise A 3 d ocumentation.alluxio.io/ee-ai-c n /ai-3.4/release-notes All uxio Enterprise AI 3.2 新版本发布 Alluxio DORA:新一代Alluxio架构 Alluxio v.s. JuiceFS - Alluxio官网 JuiceFS 对比 Alluxio | JuiceFS Document Center
上一篇曾谨言《量子力学教程》第三版PDF电子版+学习辅导与习题全解+笔记+课后习题答案
下一篇《五四青年节手抄报模板》电子版可打印,中小学生学习五四运动精神A3A4〈附电子版下载〉
基本
文件
流程
错误
SQL
调试
请求信息 : 2026-05-09 06:36:49 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/586195.html 运行时间 : 0.158322s [ 吞吐率:6.32req/s ] 内存消耗:4,675.97kb 文件加载:145 缓存信息 : 0 reads,0 writes 会话信息 : SESSION_ID=7dba72ef63afb11fd2f1934fafc399a7
CONNECT:[ UseTime:0.000419s ] mysql:host=127.0.0.1;port=3306;dbname=wenku;charset=utf8mb4 SHOW FULL COLUMNS FROM `fenlei` [ RunTime:0.000584s ] SELECT * FROM `fenlei` WHERE `fid` = 0 [ RunTime:0.000271s ] SELECT * FROM `fenlei` WHERE `fid` = 63 [ RunTime:0.003070s ] SHOW FULL COLUMNS FROM `set` [ RunTime:0.000553s ] SELECT * FROM `set` [ RunTime:0.000281s ] SHOW FULL COLUMNS FROM `article` [ RunTime:0.000552s ] SELECT * FROM `article` WHERE `id` = 586195 LIMIT 1 [ RunTime:0.003310s ] UPDATE `article` SET `lasttime` = 1778279809 WHERE `id` = 586195 [ RunTime:0.009763s ] SELECT * FROM `fenlei` WHERE `id` = 64 LIMIT 1 [ RunTime:0.001159s ] SELECT * FROM `article` WHERE `id` < 586195 ORDER BY `id` DESC LIMIT 1 [ RunTime:0.000617s ] SELECT * FROM `article` WHERE `id` > 586195 ORDER BY `id` ASC LIMIT 1 [ RunTime:0.004718s ] SELECT * FROM `article` WHERE `id` < 586195 ORDER BY `id` DESC LIMIT 10 [ RunTime:0.002845s ] SELECT * FROM `article` WHERE `id` < 586195 ORDER BY `id` DESC LIMIT 10,10 [ RunTime:0.013891s ] SELECT * FROM `article` WHERE `id` < 586195 ORDER BY `id` DESC LIMIT 20,10 [ RunTime:0.002861s ]
0.160157s
 夜雨聆风
夜雨聆风