 夜雨聆风
夜雨聆风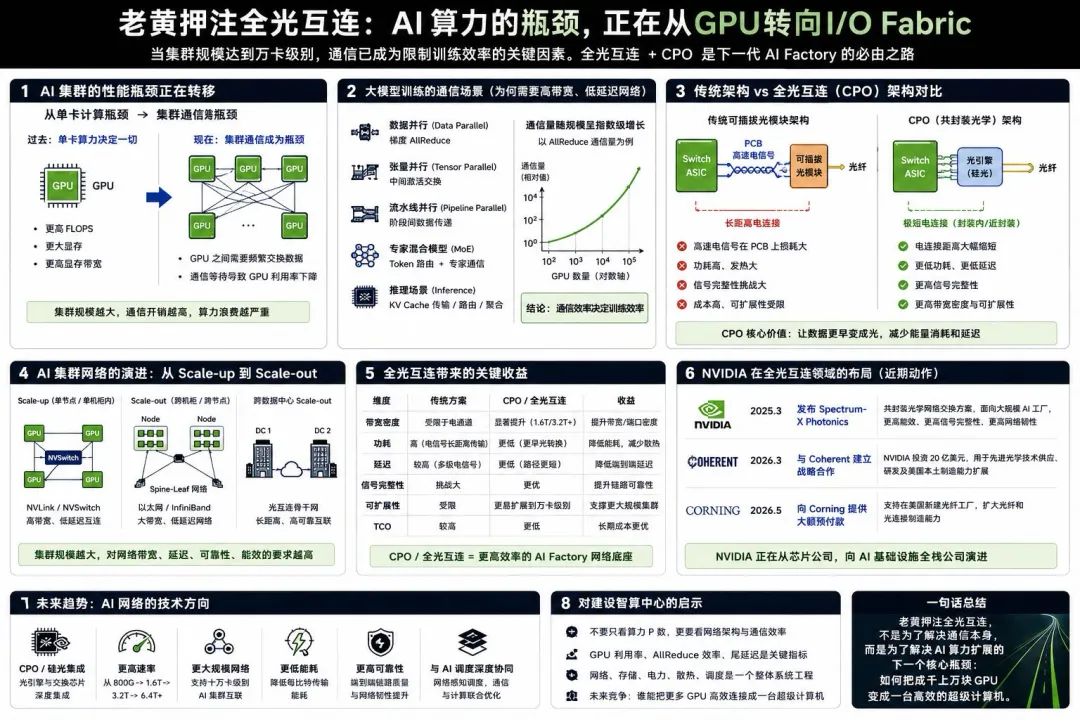
过去几年,AI基础设施的核心叙事是GPU。
H100、H200、B200、GB200,大家关注的是算力、显存、HBM带宽、FP8/FP4性能、NVLink带宽。但随着模型规模和集群规模继续扩大,一个更底层的问题开始变得明显:
GPU单点算力已经很强,但GPU之间的数据交换越来越贵。
大模型训练不是单卡任务,而是典型的分布式并行计算。
数据并行需要同步梯度。
张量并行需要频繁交换中间激活。
流水线并行需要跨阶段传递数据。
专家混合模型需要动态路由Token。
多节点推理还需要KV Cache、路由、调度和结果聚合。
这些过程都会产生大量GPU间通信。
所以,在大规模AI集群里,真正影响训练效率的,不只是FLOPS,而是端到端系统效率:
Compute + Memory + Network + Storage + Scheduling。
其中Network正在变成越来越关键的一环。
NVIDIA近两年对光互连的动作明显加速。2025年,NVIDIA发布Spectrum-X Photonics共封装光学网络交换方案,官方称其相比传统方案可实现更高能效、更高信号完整性和更高规模网络韧性。  2026年3月,NVIDIA又宣布与Coherent建立战略合作,计划投资20亿美元,用于先进光学技术供应、研发和美国制造能力扩展。  2026年5月,Reuters报道,NVIDIA还向Corning提供额外的大额预付款,用于支持其美国光纤制造能力扩张。 
这些动作说明,NVIDIA关注的已经不是单一GPU,而是AI Factory里的整体互连架构。
技术上看,问题主要出在三个地方。
第一,AI集群规模扩大后,通信开销会吃掉越来越多的有效算力。
在单机8卡、单机多GPU场景下,可以依赖NVLink、NVSwitch等高带宽互连解决GPU间通信。但当集群扩展到多机柜、多Pod,甚至跨数据中心时,通信链路开始变长,网络层级增加,延迟、拥塞、丢包、重传、同步等待都会影响训练效率。
大模型训练里,经常不是GPU不够快,而是GPU在等通信完成。
尤其在AllReduce、AllGather、ReduceScatter这类集合通信场景中,网络带宽和尾延迟会直接影响训练step time。只要有部分节点通信慢,整个同步过程就会被拖住。
所以,AI集群不是简单把GPU堆起来,而是要把GPU组织成一个低延迟、高带宽、可预测的计算织网。
第二,传统可插拔光模块架构开始接近功耗和信号完整性的边界。
现在数据中心交换机通常采用可插拔光模块。交换ASIC在设备内部,光模块插在前面板,中间需要通过PCB走高速电信号。
问题是,交换芯片速率越高,SerDes越快,电信号在PCB上的损耗、串扰、均衡复杂度和功耗都会上升。
也就是说,数据在变成光信号之前,仍然要先走一段高频电连接。
这段“电连接距离”越长,功耗越高,信号完整性越难做,系统成本也越高。
共封装光学,CPO,解决的正是这个问题。
它的核心思路是:
把光引擎从前面板光模块位置,搬到交换ASIC附近,尽量缩短高速电信号路径,让数据更早完成电光转换。
传统路径大致是:
Switch ASIC → PCB高速走线 → 前面板光模块 → 光纤
CPO路径则变成:
Switch ASIC → 封装内/近封装电连接 → 光引擎 → 光纤
这个变化的意义不是“换一种光模块形态”,而是把互连架构从板级优化推进到封装级优化。
NVIDIA在硅光页面中也明确把CPO描述为面向Agentic AI时代的网络方案,强调用同封装硅光替代传统可插拔收发器,以提升能效和网络韧性。 
第三,AI数据中心正在从Scale-up走向Scale-out,再走向跨站点Scale-out。
Scale-up解决的是单节点或单机柜内GPU如何互联。
Scale-out解决的是多个节点、多个机柜如何组成训练集群。
跨站点Scale-out解决的是多个数据中心之间如何协同提供算力。
传统云计算网络主要承载东西向业务流量和南北向访问流量。AI网络不一样,它承载的是高强度、同步性很强、对尾延迟敏感的训练和推理流量。
这类流量有几个特点:
带宽需求极高。
通信模式集中。
突发性强。
同步等待明显。
尾延迟影响整体效率。
网络不稳定会直接拖慢GPU利用率。
所以,AI网络不是传统意义上的“数据中心网络升级”,而是AI计算系统的一部分。
黄仁勋强调AI Factory,本质上是在重新定义数据中心:
数据中心不再是服务器的集合,而是一台被网络连接起来的巨型计算机。
如果这样理解,光互连就不是通信配套,而是这台巨型计算机的系统总线。
为什么NVIDIA要把手伸向Coherent、Corning这类光学供应链?
因为未来AI数据中心的关键约束不只在GPU供给,也在光学器件供给。
大规模AI集群需要大量光模块、光纤、连接器、激光器、硅光器件。集群规模越大,光连接密度越高。网络从800G走向1.6T、3.2T,交换芯片radix提高,端口数量上升,光学供应链的重要性会快速提升。
NVIDIA投资Coherent,是在锁定先进光学技术和制造能力。 
NVIDIA支持Corning扩产,是在锁定AI数据中心内部和之间所需的光纤与光连接基础材料能力。 
这说明NVIDIA的战略已经从“卖GPU”变成了“定义AI基础设施栈”。
这个栈包括:
GPU。
HBM。
NVLink / NVSwitch。
InfiniBand / Ethernet。
Spectrum-X。
BlueField DPU。
CPO / Silicon Photonics。
整机柜系统。
AI集群调度软件。
模型训练和推理软件栈。
从这个角度看,光互连不是一个孤立技术点,而是NVIDIA控制AI基础设施效率曲线的一部分。
对于技术博主来说,这里最值得讲透的是一个判断:
AI算力竞争正在从FLOPS竞争,转向Fabric竞争。
FLOPS解决“单点能算多少”。
Fabric解决“多少GPU能像一台机器一样算”。
CPO和硅光解决“这个Fabric能不能继续扩展”。
这也是为什么AI数据中心会越来越像HPC系统,而不是传统云主机资源池。
传统云资源池追求资源池化、弹性、隔离、多租户。
AI Factory追求同步效率、通信确定性、低尾延迟、高带宽密度、低功耗互连。
两者底层逻辑不一样。
如果把这个话题落到国内智算中心建设,也有很现实的提醒。
很多智算中心建设还停留在“多少P算力、多少张卡、多少机柜”的汇报口径。但真正决定平台能力的,是这些GPU能不能被高效组织起来。
技术上至少要看几项指标:
GPU利用率。
训练step time。
AllReduce效率。
网络拥塞情况。
RDMA性能。
东西向流量模型。
交换网络oversubscription比例。
端到端尾延迟。
存储到GPU的数据供给能力。
单位Token能耗和成本。
如果只堆GPU,不看网络、不看存储、不看调度、不看通信效率,最后很可能形成“账面算力很高,实际产出不高”的问题。
所以,“老黄押注全光”真正值得关注的地方,不是光通信概念本身,而是它揭示了AI基础设施的下一阶段方向:
GPU之后,网络成为算力放大的关键杠杆。
单卡性能决定下限。
集群互连决定上限。
光互连决定这个上限还能不能继续往上抬。
一句话总结:
黄仁勋押注的不是“全光概念”,而是AI Factory的下一代I/O Fabric。谁能把GPU、交换网络、光互连、存储和调度系统打成一个整体,谁才能真正把大规模GPU变成大规模有效算力。
