 夜雨聆风
夜雨聆风
招商银行基于 HAMi 构建统一异构算力底座,实现超节点双芯模组适配(GPU 入池率 100%)、vNPU-Core 软切分(1G 显存 / 1% 算力级别精细供给)、三层拓扑感知调度(跨机调度概率降低 30%),方案已反哺 HAMi 开源社区。
「不卷算力卷效率 | HAMi 社区 Meetup」深圳站由 HAMi 社区发起,密瓜智能主办,2026 年 4 月 25 日在深圳圆满结束。本文为 HAMi 社区 Meetup 深圳站回顾系列第四篇。招商银行研发工程师苏茜分享了金融行业异构算力底座建设的深度实践,聚焦超节点硬件适配、vNPU-Core 软切分、以及网络拓扑感知调度算法。
核心亮点:
• 超节点双芯模组适配,GPU 入池率提升至 100%,消除跨模组驱动异常 • vNPU-Core 软切分:1G 显存 / 1% 算力级别精细供给 • 三层拓扑感知调度,跨机调度概率降低 30% • 确定性哈希防并发打散,任务碎片化显著减少 • 方案已反哺 HAMi 开源社区,从「可用」到「可高效使用」
演讲嘉宾: 苏茜(招商银行研发工程师)

视频回放及 PPT 下载
• B 站:基于 HAMi 的异构 AI 算力调度优化实践 - 苏茜[1] • 下载 PPT:GitHub[2]
一、金融行业异构算力的特殊挑战
招商银行面临的核心挑战是算力池多源化:
• 多种 GPU/NPU 型号并存,资源碎片化严重 • 不同业务线(风控、客服、投研)对算力需求差异巨大 • 金融场景对稳定性与安全隔离有极高要求 • 运维成本随异构规模增长而快速攀升
基于 HAMi,招行建设了统一的异构算力底座,实现多种芯片的统一纳管与调度优化。
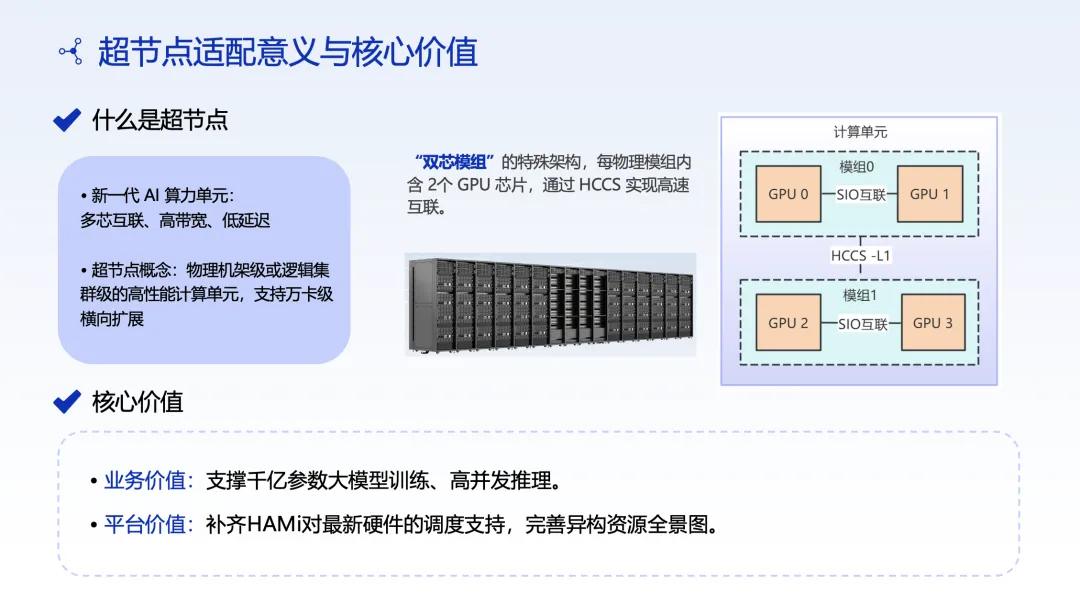
二、超节点硬件适配:双芯模组架构的挑战
什么是超节点?
超节点是一种将多颗芯片通过高速互联组合成一个逻辑单元的硬件架构。招行采用了双芯模组(Dual-Chip Module)架构,每个模组内包含多张计算卡,模组内部通过高速总线互联。
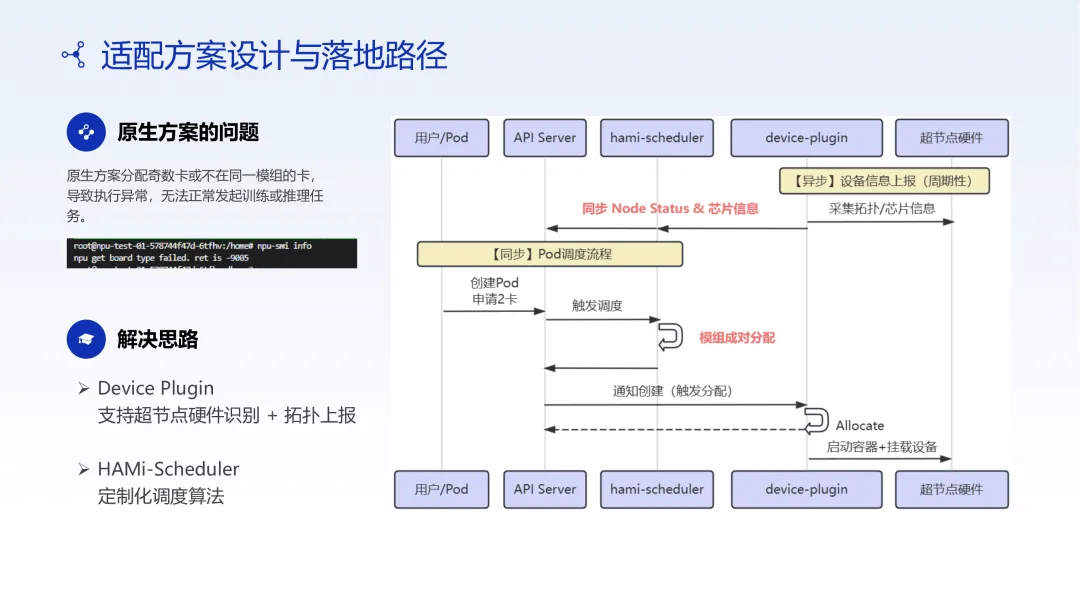
原生方案的问题
使用 Kubernetes 原生调度时,超节点架构暴露了严重问题:
• 单数卡分配: 分配单数张卡可能跨越两个模组,导致驱动异常 • 跨模组通信: 跨模组的通信延迟显著高于模组内通信 • 硬件入池率低: 由于分配不合理,部分硬件无法正常使用
HAMi 解决方案
通过增强 Device Plugin 和调度器,实现了对物理模组的识别与成对分配:
• 调度器感知模组拓扑,确保卡分配在同一模组内 • 避免单数卡跨模组导致的驱动异常 • 硬件入池率提升至 100%
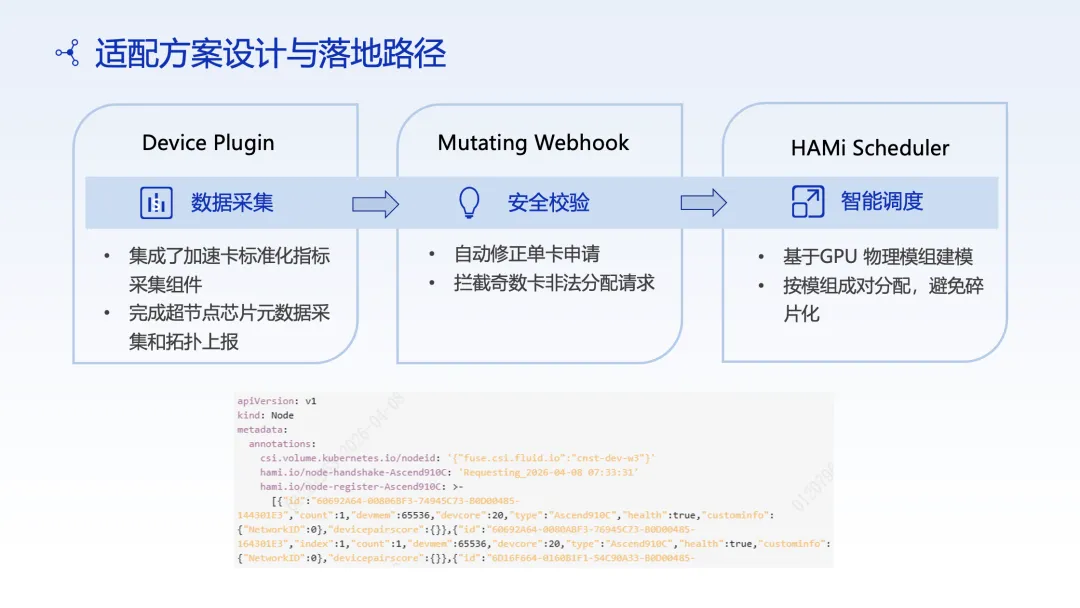
超节点适配——成效与收益
生产落地
在双芯模组架构下,传统 Kubernetes 调度缺乏对 GPU 物理拓扑的感知,导致资源分配与实际硬件结构不匹配。基于 HAMi 的超节点适配方案,通过引入模组级感知与调度约束,实现了从"逻辑资源分配"到"物理一致性调度"的转变。
核心成效包括:
• 算力利用率显著提升通过模组对齐分配策略,避免跨模组资源碎片化与不可用资源残留,整体 GPU 入池率提升至 100%,有效释放存量算力。 • 任务稳定性大幅增强消除了因单数卡跨模组分配导致的驱动异常与训练失败问题,大规模训练任务的运行成功率与稳定性显著提升,降低人工干预与运维成本。 • 通信效率优化(隐性关键收益)调度策略确保任务尽可能在同一模组内或最优拓扑路径上运行,降低跨模组通信带来的带宽争用与延迟放大问题,为分布式训练提供更稳定的性能基础。
开源社区贡献
该方案不仅在内部生产环境验证,还反哺至 HAMi 开源社区,形成可复用能力:
• 首次实现国产 AI 加速卡在"超节点架构"下的精细化调度能力 • 沉淀模组感知调度模型(Topology-aware Scheduling Primitive) • 推动异构算力从"可用"向"可高效使用"演进

三、vNPU-Core 软切分:1G 显存 / 1% 算力级别的精细切分

针对中小模型微调与推理任务,招行利用 HAMi 的 VNPU Core 组件实现了软件层面的算力切分。
技术原理
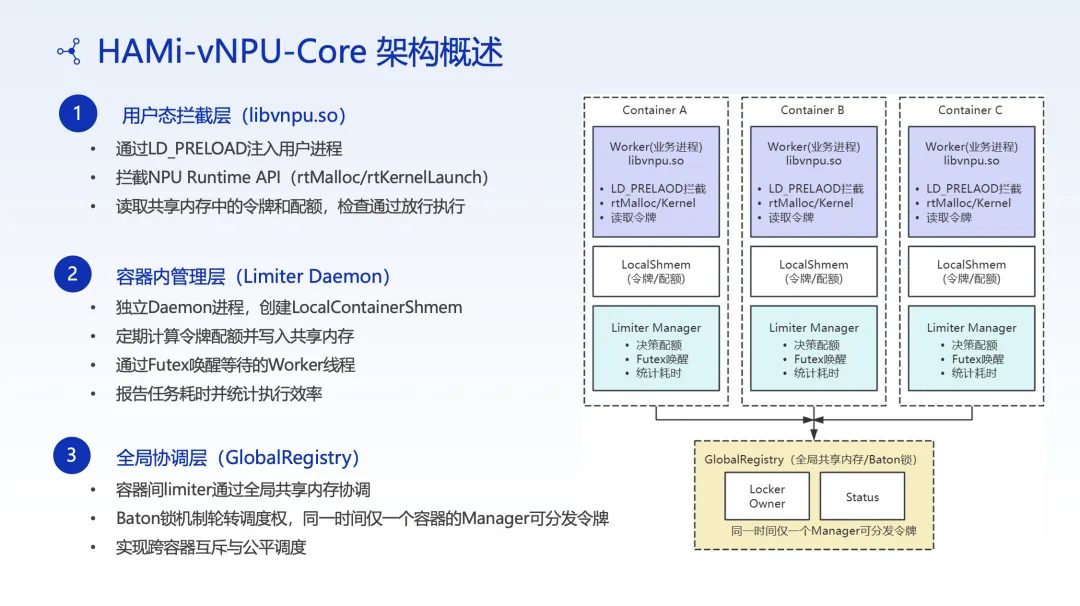
在用户态拦截算子 API,通过令牌机制(Token Bucket)和共享内存实现算力的按比例分配:
• 令牌机制: 控制每个任务的算力使用配额,超限后排队等待 • 共享内存: 在用户态管理显存分配,实现显存的细粒度切分
切分粒度
• 支持最小 1G 显存 的切分 • 支持最小 1% 算力 的切分 • 可根据任务需求灵活组合
这一能力对于银行场景尤为重要:许多风控模型和客服模型的参数规模并不大,无需整卡资源,细粒度切分可以显著提升资源利用率。
四、网络拓扑感知调度算法
这是本次分享中最具技术深度的部分。招行设计了一套多级拓扑感知调度算法,专门优化分布式训练任务的通信效率。
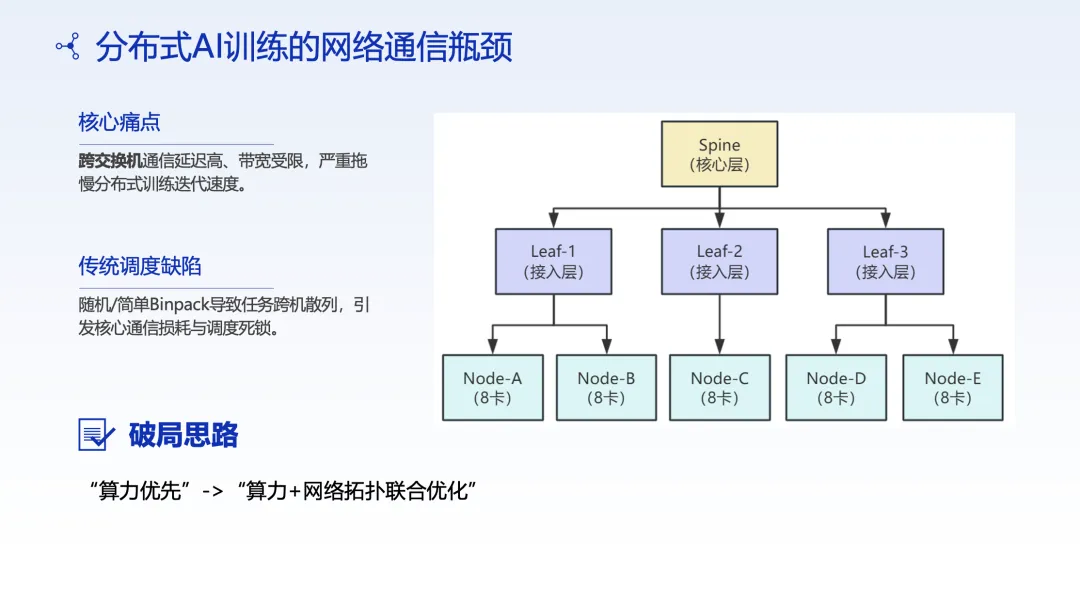
分布式 AI 训练中,由于任务跨 Leaf/节点随机分布,导致跨交换机通信成为瓶颈,需从算力优先调度转向算力与网络拓扑协同优化。
三层拓扑抽象
将物理网络拓扑抽象为三个层级:
Level 1: 同节点(Same Node) —— 通信延迟最低Level 2: 同 LEAF 交换机(Same LEAF) —— 延迟较低Level 3: 跨 LEAF 交换机(Cross LEAF) —— 延迟最高多级拓扑打分
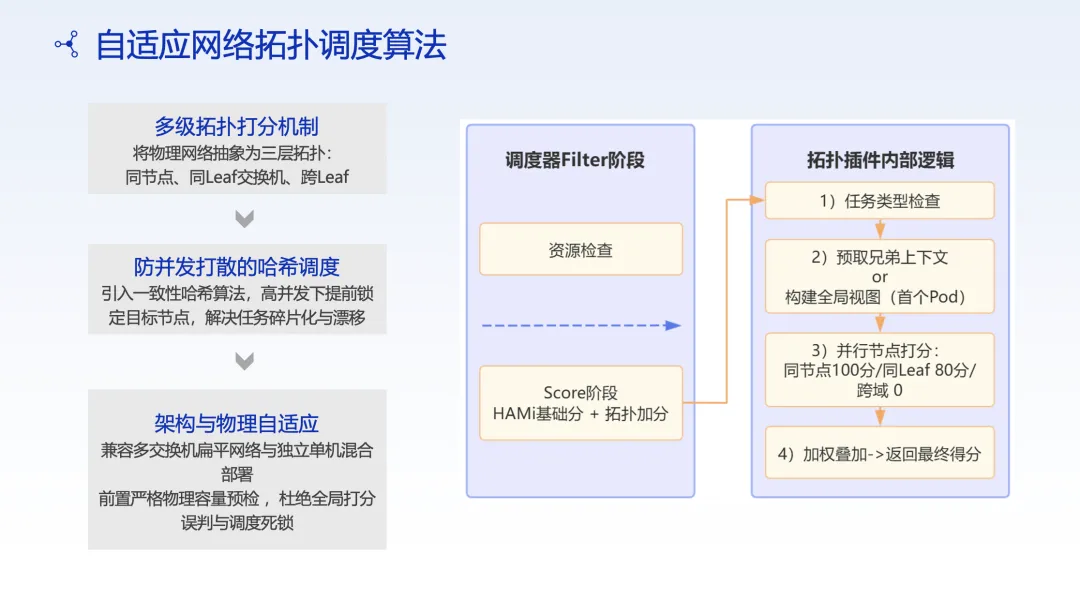
在调度器打分阶段加入拓扑加分:
• 同节点内分配:最高优先级 • 同 LEAF 交换机内分配:中等优先级 • 跨 LEAF 交换机分配:最低优先级
效果:跨机调度概率降低 30%,显著减少了分布式训练中的通信瓶颈。
防并发打散机制
一个实际生产中的问题:同一批次任务的不同 Pod 可能被调度器分散到不同节点,导致任务碎片化。
招行通过基于控制器 UID 的确定性哈希,确保同一批次任务的不同 Pod 能优先聚合到同一目标节点。
效果总结
• 硬件入池率: 提升至 100% • 跨机调度概率: 降低 30% • 最小切分粒度: 1G 显存 / 1% 算力 • 任务碎片化: 显著减少
五、总结

苏茜的分享从金融行业异构算力的实际痛点出发,展示了招商银行基于 HAMi 构建统一算力底座的实践路径:通过超节点硬件适配解决双芯模组架构下的资源对齐问题,实现硬件入池率 100%;结合 vNPU-Core 软切分能力,在昇腾 NPU 场景下实现 1G 显存 / 1% 算力级别的精细化资源供给;并引入网络拓扑感知调度,通过三层拓扑抽象与多级打分机制,将跨机调度概率降低 30%,显著优化分布式训练的通信效率。
整体来看,这一方案打通了从硬件适配、资源切分到调度优化的关键链路,使异构算力从"可用"走向"可高效使用",在大模型训练与批量推理等核心场景中实现了资源利用率与训练效率的同步提升。与此同时,招商银行将相关能力贡献回 HAMi 开源社区,也体现了金融行业在 AI 基础设施领域由"使用者"向"共建者"的转变。
面向未来,随着 AI 工作负载持续碎片化与多样化,算力调度将进一步向细粒度与弹性化演进:一方面需要持续深化软切分能力以提升资源调度灵活性与多租户隔离能力;另一方面,也需要依托 HAMi 等开源生态推动标准化与行业实践的持续沉淀与扩展。
引用链接
[1] 基于 HAMi 的异构 AI 算力调度优化实践 - 苏茜: https://www.bilibili.com/video/BV1MfozBvEsS/[2] GitHub: https://github.com/Project-HAMi/community/blob/main/hami-meetup/03-shenzhen-20260425/heterogeneous-ai-scheduling-hami-suxi.pdf
关于HAMi
HAMi,全称是 Heterogeneous AI Computing Virtualization Middleware(异构算力虚拟化中间件),是一套为管理 Kubernetes 集群中的异构 AI 计算设备而设计的“一站式”架构,能够提供异构 AI 设备共享能力,提供任务间的资源隔离。HAMi 致力于提升 Kubernetes 集群中异构计算设备的利用率,为不同类型的异构设备提供统一的复用接口。HAMi 当前是 CNCF Sandbox 项目,已被 CNCF 纳入 CNAI 类别技术全景图。
