这两年,AI 编码工具的演进速度,已经快到让整个软件行业重新定义“开发”这件事。今天的大部分开发者,其实已经不再怀疑 AI 能不能写代码,而是开始默认 AI 可以参与绝大多数软件开发场景。从前端页面、移动端业务模块,到服务端接口、数据处理、测试用例、工程脚手架,甚至复杂业务链路的初版实现,AI 都已经具备了相当强的生产能力。很多团队已经不再把 AI 当作“补全工具”,而是开始把它作为研发流程中的重要生产力单元,甚至尝试以 AI First 的方式重组开发流程。一部分更激进的观点,也已经从“AI 辅助开发”,演化到“AI 是否会替代程序员”。但真正进入复杂工程深水区后,很多团队又会逐渐发现,AI 最大的问题,从来不是“不会写代码”,而是“缺乏对复杂系统的长期控制能力”。它可以快速完成前后端、移动端、服务端的代码生成,却未必真正理解历史架构、业务边界、线上兼容逻辑和系统演化路径;它可以写出“看起来正确”的实现,却无法天然保证整个业务链路长期稳定运行。于是,软件工程的核心矛盾开始发生变化。过去大家焦虑的是“如何提高代码生产效率”,而现在真正困难的问题,已经变成了:如何让海量 AI 生成代码,真正安全、稳定、可控地进入生产环境。这其实才是 AI 编码时代真正的深水区。
一、AI 编码真正重构的,不只是“写代码”
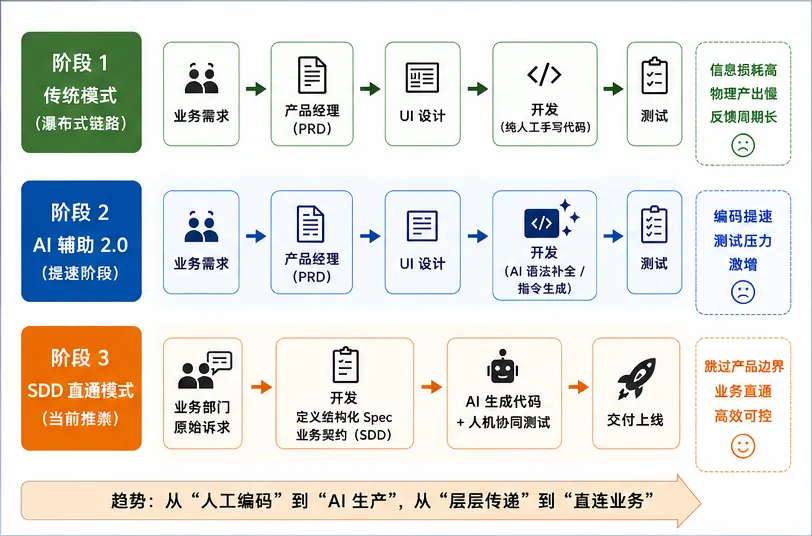
如果回头看过去两年的行业演进,会发现 AI 辅助编程其实已经经历了非常明显的三轮跃迁。最早阶段,本质上还是“高级自动补全”。那时候 AI 更像一个更聪明的 IDE 插件,负责补全函数、生成样板代码、减少重复劳动,开发者依然是逐行代码的绝对掌控者,软件工程的核心能力仍然集中在 API 熟练度、语法记忆和框架经验上。后来,大模型开始具备更强的推理能力,行业逐渐进入“指令驱动开发”阶段。开发者不再只是“写代码”,而是开始“描述意图”。比如直接告诉 AI:“帮我生成一个支付状态机”“基于这个接口生成缓存层”“给这个 ViewModel 补齐单元测试”“按 MVVM 重构当前模块”。软件开发第一次真正进入“自然语言驱动工程”的阶段。但问题也从这里开始暴露。AI 确实能快速生成代码,但它并不真正理解系统,尤其在大型历史工程中,它极度缺乏一种非常关键的能力——对复杂系统演化历史的理解。很多老工程师其实都知道,真实项目里最危险的东西,往往不是那些“写得差”的代码,而是那些明明不优雅却绝不能动的代码,是多年线上事故沉淀出的兼容逻辑,是多端共享状态、历史脏数据适配层,以及老架构与新模块之间脆弱而微妙的平衡。这些东西,本质上都是系统长期演化后的结果,而 AI 并没有这种“系统记忆”。它只能看到当前上下文,却无法真正理解整个系统为什么会演化成今天这样。于是到了 2025 年以后,行业开始逐渐收敛出一个非常重要的新方向:Spec-Driven Development(SDD)。它的核心思想,其实并不是“让 AI 自动写代码”,而是“用契约驱动 AI,而不是直接让 AI 驱动系统”。这也是 AI 工程化最关键的一次思想转变,因为大家开始意识到,AI 最怕的,其实从来不是复杂代码,而是模糊边界。
二、真正被重构的,其实是“开发者角色”
过去传统研发链路通常是“业务 → 产品 → 设计 → 开发 → 测试”,但 AI 出现以后,一个非常明显的变化是,“代码实现”本身开始不再是最昂贵的环节。于是,真正稀缺的能力,开始逐渐变成理解业务、提炼规则、定义边界、建立契约、约束 AI,以及设计验证体系。很多团队现在已经开始出现一个明显变化:越来越多高级开发开始直接对接业务部门。因为真正决定 AI 输出质量的,并不是 Prompt 写得多花哨,而是你有没有把业务边界定义清楚。比如很多需求表面上看非常简单:“退款金额不能超过订单金额。”但真实系统里,后面往往隐藏着大量复杂逻辑,包括多币种换算、部分退款、汇率波动、延迟到账、风控冻结、异常订单状态以及历史脏数据兼容。AI 不会主动理解这些东西,因此开发真正重要的能力,已经开始从“写实现”,逐渐转向“用工程语言,把业务世界翻译成机器可执行的契约(Spec)”。这也是为什么 2025 年以后,Spec-Driven Development 会快速火起来。因为行业逐渐意识到,真正影响 AI 工程质量的,从来不是生成速度,而是契约是否清晰。过去很多开发者的核心价值,在于“实现需求”;而未来越来越重要的能力,则会变成“定义系统”。因为 AI 已经能够承担大量具体实现工作,但它无法天然理解哪些边界不能突破、哪些兼容逻辑不能删除、哪些异常场景必须兜底、哪些线上行为背后隐藏着真实业务约束。换句话说,AI 正在大幅降低“编码门槛”,却反而抬高了“系统设计门槛”。未来真正重要的能力,不再只是“能把代码写出来”,而是“能否在复杂业务与复杂系统之间建立稳定契约”。
三、AI 编码最大的危机,其实不是 Bug
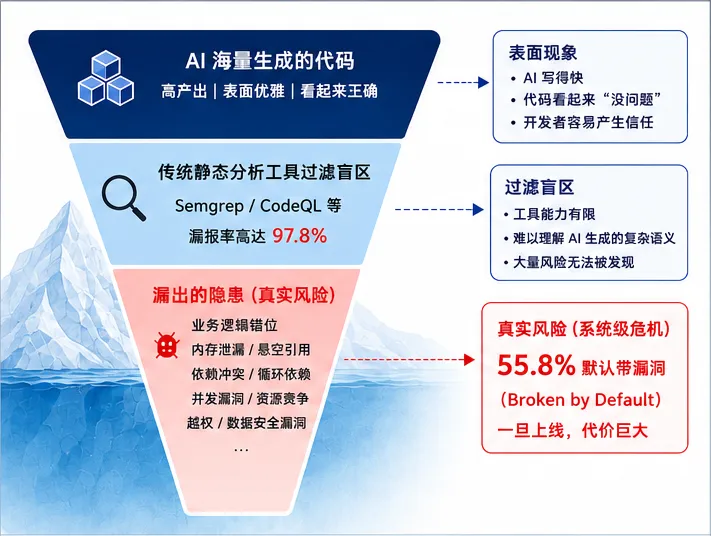
很多人谈 AI 编码风险时,第一反应通常是“AI 写的代码不安全”。但真正做过大型工程的人会知道,低级 Bug 其实不是最危险的问题,真正危险的是系统级失控。尤其在 iPad 与 iPhone 底层工程融合、Obj-C 与 Swift 大规模混编、老架构渐进式重构、多端状态统一、大型模块拆分,以及基础组件现代化升级这些场景里,风险会被急剧放大。AI 在单函数层面可能表现很好,但它极度缺乏“宏观系统感”。它很容易偷偷引入循环依赖、破坏生命周期、忽略线程安全、污染状态流,或者生成隐式内存泄漏。尤其在 Swift 闭包与 Obj-C 生命周期混用场景下,这类问题非常典型。很多时候代码甚至可以编译通过、单测通过、CI 全绿,但线上跑一段时间后,就开始出现随机 Crash、页面不释放、内存暴涨、状态错乱、偶发死锁等问题。这些问题,才是真正危险的地方。因为 AI 非常擅长生成“看起来正确”的代码,但软件工程最难的,从来不是“看起来正确”,而是在复杂历史系统里长期稳定运行。更危险的一点在于,AI 非常容易放大“局部正确、全局错误”的问题。它可以在当前上下文里生成逻辑自洽的实现,但未必真正理解整个系统中的调用链、状态流、线程模型以及历史兼容关系。因此,很多 AI 生成代码的问题,并不会在第一时间暴露,而是会在长周期运行、线上高并发、复杂用户行为或者历史数据回放时逐渐显现。这也是为什么很多团队在 AI 编码初期会产生一种错觉:开发速度确实变快了,但系统复杂度也在以更快速度累积。
四、AI 越强,验证体系反而越重要
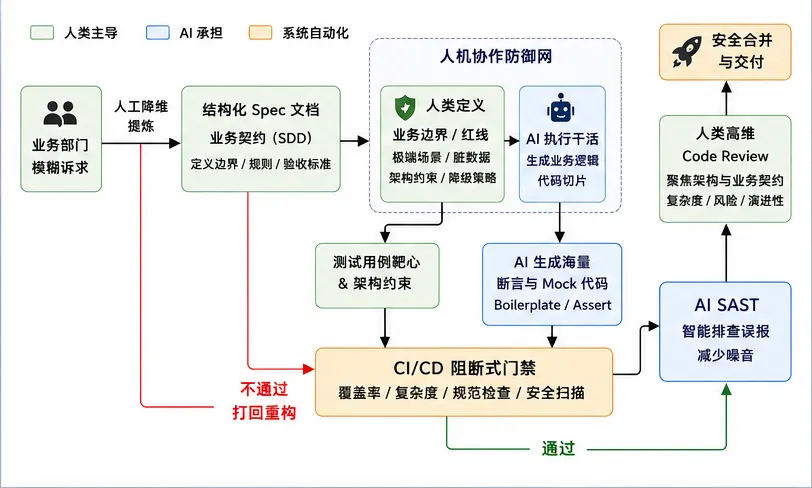
到了这里,整个研发体系会发生一个非常核心的变化:过去研发的重点是“生产代码”,未来研发的重点,会越来越变成“验证代码”。因为当代码生产成本趋近于零以后,真正昂贵的东西,就会变成系统可信度、架构稳定性、业务正确性以及线上可控性。这也是为什么很多真正开始大规模 AI 化的团队,最后都会走向同一个方向:强化测试、强化 CI、强化约束、强化验证。因为 AI 越强,越需要防御体系。而现在很多团队最容易踩的坑,就是让 AI 既当运动员,又当裁判。比如 AI 生成业务代码、AI 生成测试代码、AI 自己跑测试、最后全绿通过直接上线。表面看起来非常先进,但本质上,这是一个非常危险的“回音壁系统”,因为错误逻辑,很可能通过错误测试,最后形成一种非常诡异的局面:CI 全绿,线上全红。所以真正成熟的人机协同,一定是明确分工的。真正重要的东西,必须由人类定义,包括业务红线、极端场景、历史脏数据、异常状态、灰度策略、降级逻辑以及风险边界,因为这些东西,本质上属于“领域隐性知识”,AI 无法凭空理解。而 AI 真正适合做的,则是大规模 Boilerplate 生成、Mock 构建、Assert 补齐、测试样例扩展以及重复性逻辑实现。这也是为什么未来测试的重要性不仅不会下降,反而会大幅提升。过去测试很多时候是在“验证代码是否符合需求”,而未来测试会越来越变成“验证 AI 是否突破系统边界”。测试的本质,也会从传统功能验证,逐渐升级为“系统防御体系”的核心组成部分。
五、复杂工程里,真正重要的是“上下文控制”
很多团队现在还有一个典型误区,就是把整个工程直接丢给 AI。这在大型 Obj-C / Swift 混编工程里尤其危险,因为 AI 一旦上下文失控,就非常容易开始“脑补架构”。真正成熟的做法,反而是主动裁剪上下文。比如只投喂当前模块 Interface、单独提供 Bridging Header、明确声明生命周期规则、强制要求 [weak self],以及限定分层生成顺序。例如严格按照“Model → ViewModel → View → Integration”的顺序逐层生成、逐层验证,而不是一次性生成整个业务链路。因为 AI 最大的问题之一,就是上下文一长,就容易开始幻觉化“合理推断”,而在历史工程里,这种风险尤其巨大。很多真正做过大型 AI 工程化实践的团队,最后都会发现一个核心规律:AI 并不是“上下文越多越聪明”,很多时候恰恰相反。过长、过脏、过历史化的上下文,会让模型不断混入旧逻辑、错误依赖以及历史兼容行为,最终导致输出质量快速下降。所以未来工程体系里,一个越来越重要的新能力,其实是“上下文工程(Context Engineering)”。也就是如何控制 AI 在什么边界内理解系统、如何限制它的推理范围、如何让它聚焦当前问题,而不是无限扩散上下文。这会逐渐成为 AI 工程化里的核心基础设施之一。
六、技术管理者真正该做的,不是“All in AI”
很多团队 AI 落地失败,其实并不是工具问题,而是组织推进方式出了问题。最常见的错误,就是“全员立刻 AI 化”。结果通常会变成 Prompt 混乱、工程风格失控、架构开始漂移、验证体系跟不上、CI 压力暴涨,最后 Bug 数量反而增加。真正成熟的推进方式,其实应该是技术负责人先亲自下场打样,亲自跑通完整链路,包括直接对接业务、编写 Spec、使用 Codex 或 Copilot 约束 AI 生成、人工定义边界、AI 批量生成测试、建立 CI 阻断,以及完成真实业务上线。只有真正踩过坑,才会知道哪些 Prompt 有效、哪些上下文会污染模型、哪些历史模块最危险、哪些验证机制必须前置。最后再逐渐沉淀 SOP、固化模板、输出效能数据、小范围灰度推广,并最终完成团队化落地。这才是 AI 工程化真正合理的推进路径。很多技术管理者现在最大的误区,是把 AI 当成“提效工具”去看。但真正的问题并不只是“提效”,而是整个研发组织结构正在被重构。过去研发团队的瓶颈是“人力不足”,而未来真正的瓶颈,很可能会变成“系统失控速度超过团队治理能力”。因此,未来技术管理的核心,也会逐渐从“项目管理”转向“系统治理”,包括如何建立 AI 约束体系、如何设计验证机制、如何控制架构演化速度、如何防止工程复杂度失控。这些东西,最终都会变成 AI 时代技术管理者最核心的能力。
七、未来真正稀缺的人,会是“全链路工程主理人”
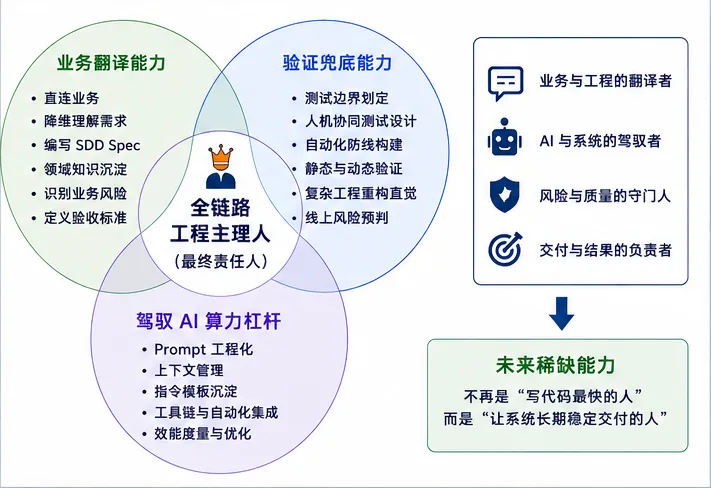
未来的软件工程协作模式,其实已经开始逐渐收敛为:AI 批量生成 + 契约前置约束 + 人机协同验证 + 人类最终拍板而这背后最大的变化,并不是“程序员会不会被替代”,真正被重构的,其实是高级工程师的定义。未来真正稀缺的人,不再只是“代码高手”,而是能够同时理解业务、架构、AI 与系统风险的人,也就是所谓的“Engineering Owner(全链路工程主理人)”。他们需要同时具备业务理解能力、系统架构能力、AI 驾驭能力、风险控制能力以及验证体系设计能力。因为在 AI 编码时代,语法错误会越来越少,Boilerplate 会被彻底自动化,CRUD 会逐渐被 AI 接管,但真正危险的问题,会越来越集中于业务逻辑错误、系统边界失控、历史架构腐化、多端状态不一致以及大规模重构风险。所以未来工程师最核心的竞争力,不再是谁代码写得快,而是谁能在模糊商业诉求与复杂系统现实之间,建立一套“契约明确、边界清晰、防御完备”的可信交付体系。这,才是 AI 编码时代真正的核心壁垒。
基本文件流程错误SQL调试
请求信息 : 2026-05-09 04:37:00 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/592114.html
 夜雨聆风
夜雨聆风