 夜雨聆风
夜雨聆风过去这一年,几乎所有人都在谈论 CUDA[1]。它是深度学习的底座,是新硬件很难与 NVIDIA 竞争的重要原因,也是 NVIDIA 的护城河和市值飙升的核心所在。DeepSeek 又提醒我们一个耐人寻味的事实:它的突破,部分正是靠绕开 CUDA、直接下探到 PTX 这一层[2]才实现的。可这到底意味着什么?每个人似乎都想打破这种锁定效应,但在动手之前,我们得先弄清楚面对的究竟是什么。
CUDA 在 AI 里的统治地位毋庸置疑,但大多数人并不真正清楚 CUDA 到底是什么。有人觉得它是一门编程语言,有人说它是一个框架,也有很多人把它理解成能让 NVIDIA GPU 变快的东西。这些说法都不能算全错,而且也有很多非常聪明的人正在努力解释这件事[3],但都还没有真正覆盖 CUDA 平台的完整范围。
CUDA 从来都不是单独的一样东西。它是一个庞大、分层的平台,由一整套技术、软件库和底层优化组成,共同构成了一个大规模并行计算生态系统。它至少包括:
一套底层并行编程模型,让开发者可以用接近 C++ 的语法调动 GPU 的原始算力。 一组复杂的软件库和框架,也就是支撑关键垂直场景的中间件,比如 AI 里 PyTorch 和 TensorFlow 依赖的 cuDNN。 一批更高层的解决方案,例如 TensorRT-LLM 和 Triton。即使你没有深厚的 CUDA 专业知识,也能通过这些方案让 AI 工作负载(例如大语言模型推理服务)顺利跑起来。
但这些还只是表层。
本文会逐一说明 CUDA 平台的关键层次,回看它一路演化的历史,也会解释为什么它会在今天的 AI 计算里占据如此核心的位置。这也会为本系列下一篇铺路,到时我们会继续讲 CUDA 为什么会如此成功。先剧透一句:这里面跟市场激励的关系,恐怕比跟技术本身的关系还要大得多。
CUDA 之前的路:从图形处理到通用计算
在 GPU 成为 AI 和科学计算的主力之前,它本质上还是图形处理器,也就是专门负责渲染图像的芯片。早期 GPU 会把图像渲染流程直接硬编码进硅片里,这意味着渲染的每一步,比如变换、光照和光栅化,都是固定的。这样的设计处理图形很高效,却也很不灵活,因为它根本没法拿去做别的计算任务。
真正的转折点出现在 2001 年,那时 NVIDIA 推出了 GeForce3,这是第一款支持可编程着色器(Programmable Shaders)的 GPU。这是计算史上的一次巨大转向:
🎨 之前:固定功能 GPU 只能套用预先定义好的效果。 🖥️ 之后:开发者可以自己编写着色器程序,图形流水线第一次真正变得可编程。
随着 Shader Model 1.0 的出现,开发者从此可以为顶点和像素处理编写由 GPU 执行的小程序。NVIDIA 也由此看到了未来的方向:GPU 不该只是一块越来越快的图形芯片,它还可以成为可编程的并行计算引擎。
与此同时,研究人员也很快开始追问:
“🤔 如果 GPU 能为图形运行小程序,那它能不能也拿来做非图形任务?”
最早认真尝试这件事的项目之一,是斯坦福的 BrookGPU Project[4]。Brook 提出了一种编程模型,让 CPU 可以把计算任务卸载到 GPU 上,这正是为 CUDA 铺路[5]的关键思想之一。
这既是一次战略选择,也彻底改变了方向。NVIDIA 没有把计算当作边缘实验,而是把它提升为第一优先级,从硬件、软件到开发者生态,全都围绕 CUDA 深度整合。
CUDA 并行编程模型
到了 2006 年,NVIDIA 推出了 CUDA(Compute Unified Device Architecture),这是第一套面向 GPU 的通用编程平台。CUDA 编程模型实际上由两部分构成:一个是 CUDA 编程语言,另一个是 NVIDIA Driver。
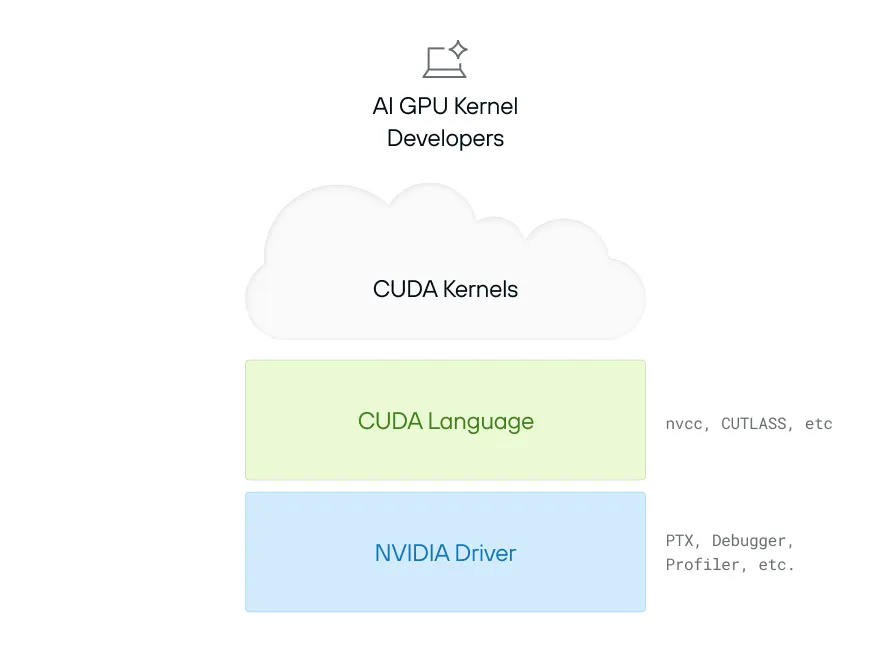
CUDA 语言从 C++ 演化出来,并进一步暴露了 GPU 的一些底层能力,比如 GPU Threads 和内存模型。程序员可以用它定义一个 CUDA 内核(Kernel),也就是一段在 GPU 上运行的独立计算逻辑。最简单的例子大概像这样:
__global__ voidaddVectors(float *a, float *b, float *c, int n){int idx = threadIdx.x + blockIdx.x * blockDim.x;if (idx < n) { c[idx] = a[idx] + b[idx]; }}CUDA 内核让程序员可以定义一段自定义计算逻辑,访问本地资源(例如内存),并把 GPU 当成超高速的并行计算单元来使用。CUDA 语言最终会被编译成 PTX,这是一种类似汇编的语言,也是 NVIDIA GPU 当前支持的最低层接口。
但程序到底是怎么真正把代码跑到 GPU 上的?这就轮到 NVIDIA Driver 出场了,它是 CPU 和 GPU 之间的桥梁,负责内存分配、数据传输和内核执行。下面是一个简单例子:
cudaMalloc(&d_A, size);cudaMalloc(&d_B, size);cudaMalloc(&d_C, size);cudaMemcpy(d_A, A, size, cudaMemcpyHostToDevice);cudaMemcpy(d_B, B, size, cudaMemcpyHostToDevice);int threadsPerBlock = 256;// Compute the ceiling of N / threadsPerBlockint blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;addVectors<<>>(d_A, d_B, d_C, N);cudaMemcpy(C, d_C, size, cudaMemcpyDeviceToHost);cudaFree(d_A);cudaFree(d_B);cudaFree(d_C);可以看到,这一切都非常底层,到处都是繁琐细节,比如指针和各种魔法数字(也就是含义不直观、只能靠上下文理解的固定数值)。只要哪一步写错,你得到的往往不是清晰提示,而是很难理解的崩溃。除此之外,CUDA 还暴露了很多 NVIDIA 硬件特有的细节,例如一个 Warp 里到底包含多少 Threads(这一点我们这里先不展开)。
尽管困难不少,这套模型还是让整整一代硬核程序员第一次用上了 GPU 在数值计算上的强大能力。一个典型例子是 AlexNet[6],它在 2012 年点燃了现代深度学习。这一切之所以成为可能,靠的是为卷积、激活、池化、归一化等 AI 操作手写的 CUDA 内核,以及 GPU 能提供的那股原始算力。
很多人一听到 CUDA,想到的通常就是 CUDA 语言和 Driver。可它们离完整答案还差得很远。如果硬要打个比方,这还只是馅料,不是整张饼。随着时间推移,CUDA 平台逐渐长出了更多层次,原来那个缩写本身,也越来越不足以描述今天的 CUDA 到底是什么。
高层 CUDA 软件库:让 GPU 编程更容易上手
CUDA 编程模型打开了通用 GPU 计算的大门。它能力很强,但也带来了两个问题:
CUDA 很难用,而且更糟的是…… CUDA 解决不了性能可移植性(Performance Portability)问题。
大多数为第 N 代 GPU 写出来的内核,到了第 N+1 代通常还能继续跑,但性能往往很差,远远达不到第 N+1 代硬件本来能给出的峰值表现。但在 GPU 领域,最看重的偏偏就是性能。这让 CUDA 成了专家工程师手里的强力工具,却也在大多数开发者面前竖起了一条陡峭得可怕的学习曲线。更现实的问题是,每当新一代 GPU 发布,通常都要做大量重写(例如 Blackwell 这一代现在就已经来了)。
随着 NVIDIA 规模越来越大,它也越来越希望 GPU 不只服务于 GPU 专家,而是让那些在自己领域里很专业、却并不懂 GPU 的人也能用。为此,NVIDIA 的做法是构建一整套丰富而复杂的闭源高层软件库,把底层 CUDA 细节都封装起来,其中包括:
cuDNN(2014):加速深度学习任务,例如卷积和激活函数。 cuBLAS:优化线性代数运算。 cuFFT:在 GPU 上执行快速傅里叶变换(FFT)。 以及很多别的库[7]。
有了这些软件库,开发者就能不自己编写 GPU 代码,也照样吃到 CUDA 的能力红利。而为每一代新硬件重写这些库的负担,则由 NVIDIA 自己承担起来。这是一笔很大的投入,但它确实奏效了。
其中,cuDNN 尤其关键。它为 Google 的 TensorFlow(2015)和 Meta 的 PyTorch(2016)铺平了道路,让深度学习框架真正起飞。更早之前当然也有 AI 框架,但 TensorFlow 和 PyTorch 是最早真正做出规模的那一批。今天的 AI 框架里,已经有成千上万个这样的 CUDA 内核,而每一个都很难写。随着 AI 研究爆炸式增长,NVIDIA 也在持续激进地扩展这些软件库,去覆盖新的关键场景。

NVIDIA 对这些强大 GPU 软件库的投入,让全世界可以把注意力放在构建 PyTorch 这样的高层 AI 框架,以及 Hugging Face 这样的开发者生态上。接下来,它又往前走了一步:不只是提供库,而是直接提供整套可以开箱即用的解决方案,让人们根本不必理解 CUDA 编程模型本身。
为应对 AI 和 GenAI 爆发而出现的全栈垂直方案
AI 的热潮早已越过研究实验室,如今几乎无处不在。从图像生成到聊天机器人,从科学发现到代码助手,生成式 AI(Generative AI,GenAI)已经在各行各业迅速扩张,把大量新应用和新开发者一起带进了这个领域。
与此同时,新一代 AI 开发者也随之出现,需求和过去完全不同。在早期,做深度学习往往需要高度专业化的工程师,他们懂 CUDA、懂 HPC(高性能计算),也懂底层 GPU 编程。可现在,出现了一类新的开发者,通常被叫作 AI 工程师(AI Engineers)。他们可以构建和部署 AI 模型,却不必亲手碰任何底层 GPU 代码。
为了满足这批人的需求,NVIDIA 已经不只是提供软件库,而是进一步推出了把底层复杂性封装起来的一站式方案。这些框架不再要求开发者具备深厚的 CUDA 专业知识,而是让 AI 开发者可以用很小的代价完成模型优化和部署,例如:
Triton Serving:面向 AI 模型的高性能服务系统,支持团队在多块 GPU 和 CPU 上高效运行推理。 TensorRT:深度学习推理优化器,能够自动调优模型,让它们在 NVIDIA 硬件上高效运行。 TensorRT-LLM:更进一步的专用方案,专门面向大语言模型的大规模推理。

这些工具几乎把 CUDA 的底层复杂性完全挡在 AI 工程师的视野之外,让他们可以把注意力放在模型和应用本身,而不是硬件细节上。这种系统级杠杆,正是 AI 应用得以横向扩张的重要原因之一。
完整来看,CUDA 平台到底是什么
很多人把 CUDA 理解成一种编程模型、一组软件库,或者干脆理解成 NVIDIA GPU 用来跑 AI 的那套东西。但实际上,CUDA 远不止这些。它既是一个统一的品牌,也是一整套极其庞大的软件集合,还是一个经过高度调优的生态系统,并且与 NVIDIA 的硬件深度绑定。正因如此,CUDA 这个词本身其实有歧义。我们更愿意说“CUDA 平台”,因为它更接近 Java 生态,甚至更接近操作系统,而不只是某种编程语言加运行时库。
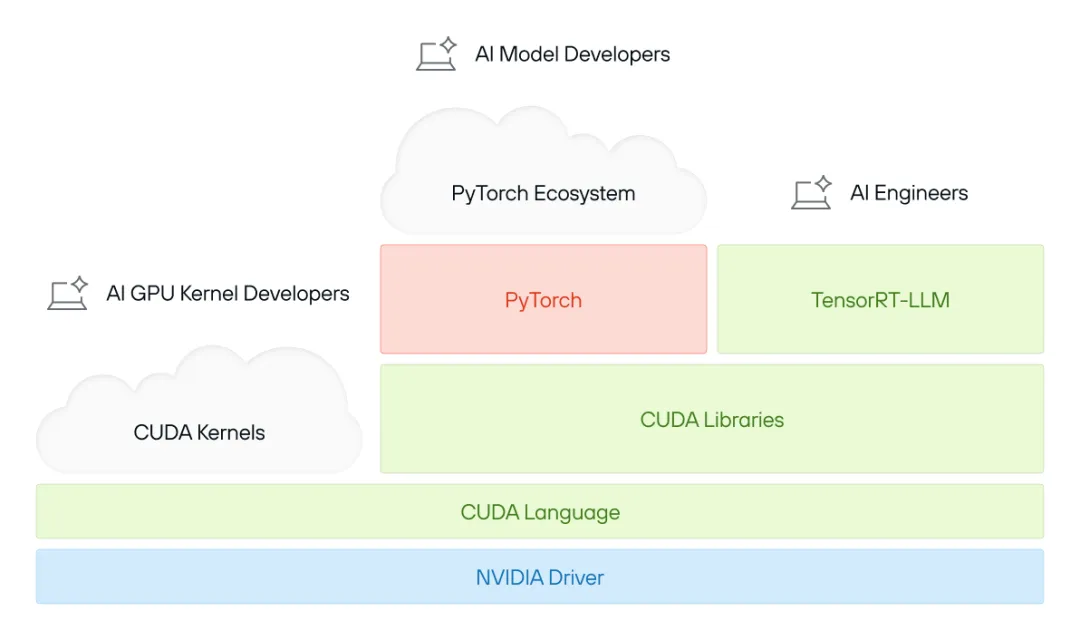
从核心来看,CUDA 平台至少包括:
一套庞大的代码库:数十年积累下来的 GPU 优化软件,从矩阵运算一直覆盖到 AI 推理。 一个巨大的工具和软件库生态:从用于深度学习的 cuDNN 到用于推理的 TensorRT,CUDA 覆盖了极其广泛的工作负载。 与硬件深度调优的性能:每一次 CUDA 发布,都会围绕 NVIDIA 最新 GPU 架构做深度优化,以保证顶级效率。 专有而不透明的内部实现:当开发者调用 CUDA 库的 API 时,底层实际发生的很多事情都是闭源的,而且深度绑定在 NVIDIA 生态里。
CUDA 是一组强大但也庞杂的技术集合,它不只是几项工具,而是整套支撑现代 GPU 计算的软件平台,影响甚至早已超出 AI 本身。
现在我们已经知道 CUDA 到底是什么,接下来就该理解它为什么会如此成功。先透露一点:CUDA 的成功,真正关键的并不只是性能,而是策略、生态和势能。在下一篇博客里,我们会继续讨论,NVIDIA 的 CUDA 软件到底靠什么塑造并巩固了现代 AI 时代。
下篇见。
关于作者
本文作者 Chris Lattner 是 Modular 联合创始人兼首席执行官(CEO)。他长期从事编译器、开发者工具和 AI 基础设施工作,曾创建并推动 LLVM、Clang、MLIR、Swift 和 Cloud TPU 等关键技术,也曾在 Apple、Google、SiFive 和 Tesla 参与或领导底层系统与 AI 平台相关工作。
更多资源
官网:https://www.modular.com/ GitHub:https://github.com/modular/modular Discord:https://discord.gg/modular 论坛:https://forum.modular.com/ 博客:https://www.modular.com/blog 文档:https://docs.modular.com/
参考资料
CUDA: https://en.wikipedia.org/wiki/CUDA
[2]PTX: https://www.tomshardware.com/tech-industry/artificial-intelligence/deepseeks-ai-breakthrough-bypasses-industry-standard-cuda-uses-assembly-like-ptx-programming-instead
[3]Ian Cutress 对 CUDA 的解释: https://x.com/IanCutress/status/1884374138787357068
[4]BrookGPU Project: http://graphics.stanford.edu/projects/brookgpu/
[5]为 CUDA 铺路: https://www.nvidia.com/content/GTC/documents/1001_GTC09.pdf
[6]AlexNet: https://en.wikipedia.org/wiki/AlexNet
[7]NVIDIA CUDA 库: https://developer.nvidia.com/gpu-accelerated-libraries
