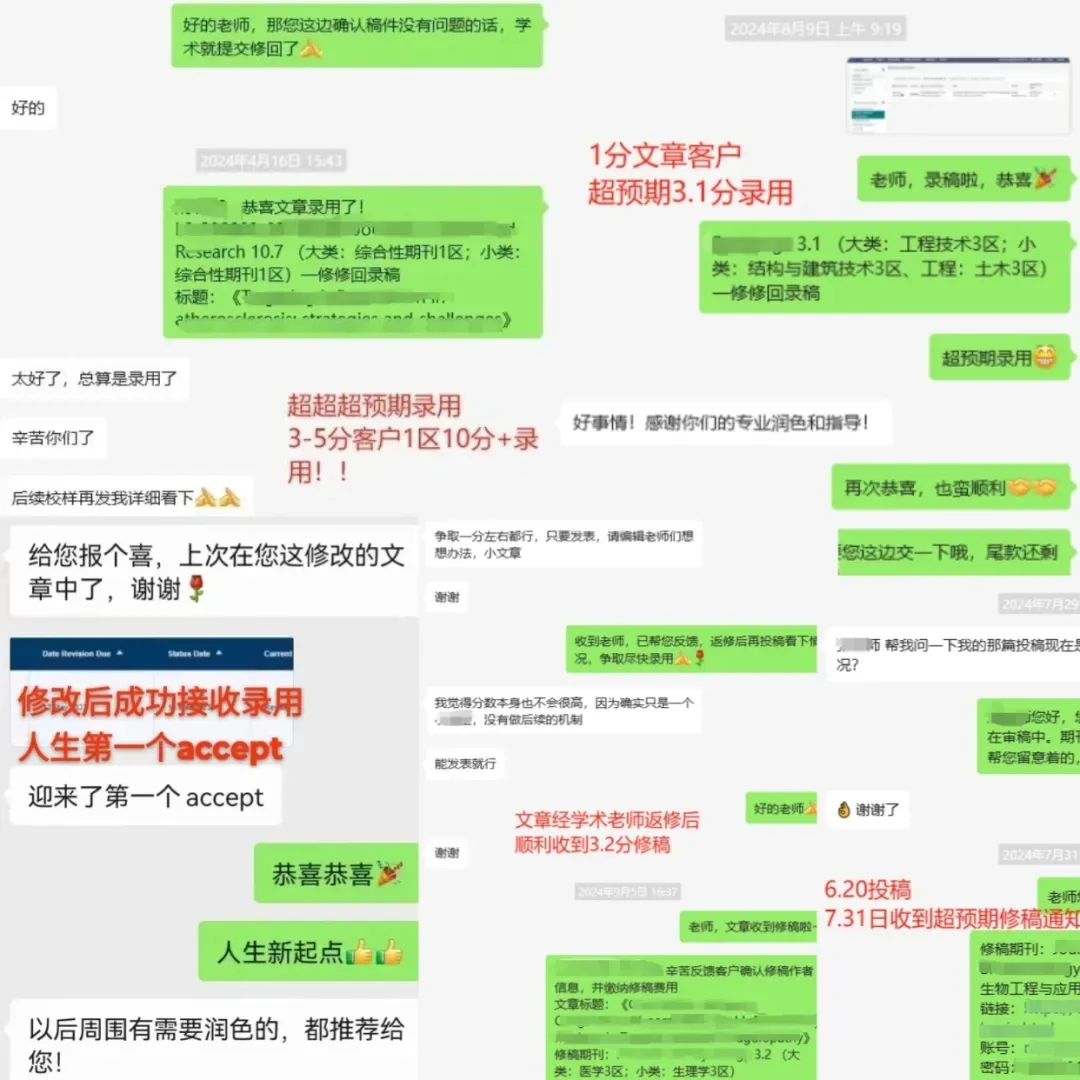
夜雨聆风
夜雨聆风
随着人工智能工具在科研文书撰写中的普及,2026年国家自然科学基金函评工作正经历一场悄无声息的变革。
AI的介入,不仅抹平了科研标书在形式层面的差距,更重塑了评审专家的评价逻辑与筛选标准——曾经靠“硬伤”筛除、凭文字辨优劣的评审模式逐渐失效,新的评价锚点、隐性门槛与现实困境同步浮现。

一、所有本子都"没问题",反而成了最大的问题
今年函评里最刺眼的变化,不在于"大家写得更好了",而在于"大家看起来都差不多好"。
有位正在审本子的专家说得很直白:"以前还能从硬伤筛掉一批,今年这些硬伤几乎消失了。"
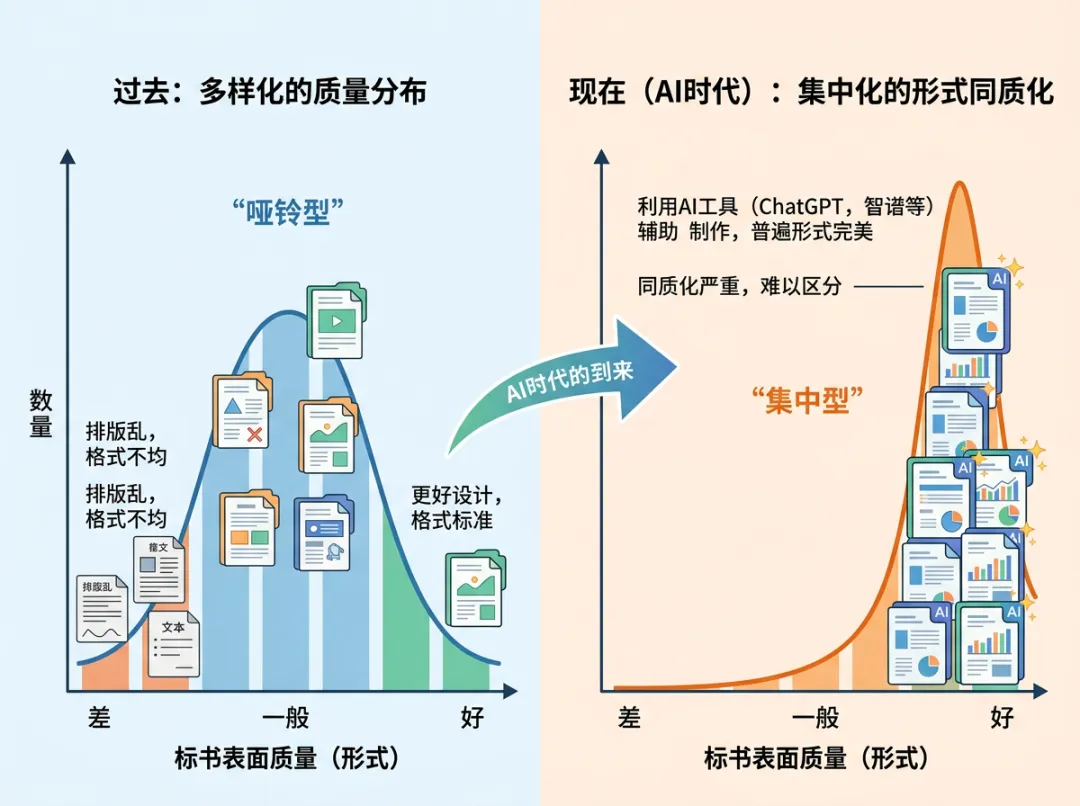
逻辑混乱、表述不清、图表粗糙——这些过去一眼就能判定"准备不足"的信号,现在被AI顺手抹平了。段落结构更工整,句子更顺滑,技术路线图画得跟教程模板似的。对普通本子来说,这种"外观升级"尤其明显,原本写作能力弱、表达不到位的短板,被工具补得七七八八。
问题正出在这儿。
当形式层面的差距被拉平,评审想在短时间内靠文字去抓"谁真的有新东西",反而更难了。创新点本来就稀缺,不会因为语言更漂亮就自动变多。但包装一旦整齐划一,真正的亮点就容易被埋在一堆同样顺滑的叙述里。
专家面对的困境很现实:每份都像"认真准备过",时间有限,怎么快速把真正出挑的那几份挑出来?文字不再是最好用的筛子,评价的重心自然开始漂移。
二、代表作为什么成了更硬的通货
代表作在AI时代被反复拎出来看,说白了,它更像一张"可追溯的成绩单"。
一篇像样的论文,不是把段落写顺、把图画漂亮就能生出来的。实验怎么设计、样本怎么来、数据怎么跑、结果怎么解释,中间还要经得起同行挑刺、补实验、再修改。AI能帮你润色措辞、把示意图画得更规整,但它替不了你在实验台前卡过的那些坑,也替不了你把一套数据从原始记录一路整理到可复现的过程。
更关键的是,代表作已经被期刊的外部评审"验过一次货"。当然也可能漏检,但至少多了一道来自同行的校验。而标书是一次性的、匿名的,函评专家在有限时间里很难把每个细节都掰开揉碎核对。
碰到交叉方向时这一点更明显。专家未必熟到能判断你写的某条通路、某个分子名字有没有问题,这时他最省时也最稳妥的动作,就是回头看你到底做出来过什么。
有会评专家讲得很直白:"遇到不太懂的方向,基本只看代表作,刊物级别和文章内容对口就行。本子里的具体分子名字、通路细节,说实话也来不及深究。"
在这种评审现实里,代表作自然就成了更"干净"、也更硬的通货。
三、"AI味过浓"正在成为一种隐性扣分项
有评审跟我说过一句很形象的话:AI能把一份60分的本子快速抬到75分,让你看起来像个很会写的人;但想冲到95分,靠的就不是写作工整了,而是你对问题的判断、对实验的设计、对坑点的预判。这些东西AI很难替你长出来。
也正因为大家的语言、结构都被工具"拉齐"了,评审反而更容易对"AI味"敏感。
什么算AI味?段落像尺子量出来一样整齐,过渡词一水儿"因此/然而/综上",读起来顺,但没有人的犹豫、取舍和重点。图画得很漂亮,可细节经不起问——比如蛋白定位画错了,信号箭头方向不规范,机制链条里缺了关键的限制条件。熟行一眼就会觉得不对劲。不是你不懂,是你没认真想过。
更麻烦的是,AI痕迹太重时,专家往往会把它解读成"申请人投入不够"。标书写得像模板拼出来的,科学问题像被"润色"过却没被"咬过",那种空滑感会直接影响信任。你到底有没有在这个方向里摔过跤、改过方案、被数据打过脸?
有人会在评语里委婉一点,有人很干脆:看不出你自己的东西,先筛掉。
工具当然可以用,尤其是做语言整理、图形美化这类"体力活"。但到关键段落,最好让评审看到你个人的手感——你为什么这样设对照、哪个步骤最可能翻车、你准备怎么兜底。那才是把"AI帮你省时间"变成"专家愿意给你分"的分水岭。
四、当"都差不多"的时候,评审在找什么锚点
很多评审说今年最难的地方,不在于"差的太差",而在于"都差不多"。
一位老师拿自己收到的12份青C举例:三分之一明显是交差的,三分之一基础薄、写得也虚,真正能坐到桌面上掰手腕的,也就最后四五份。问题是,这四五份往往都能把故事讲圆——格式规整、图也漂亮、路线也像那么回事,彼此之间很难靠几处表述去拉开一档。
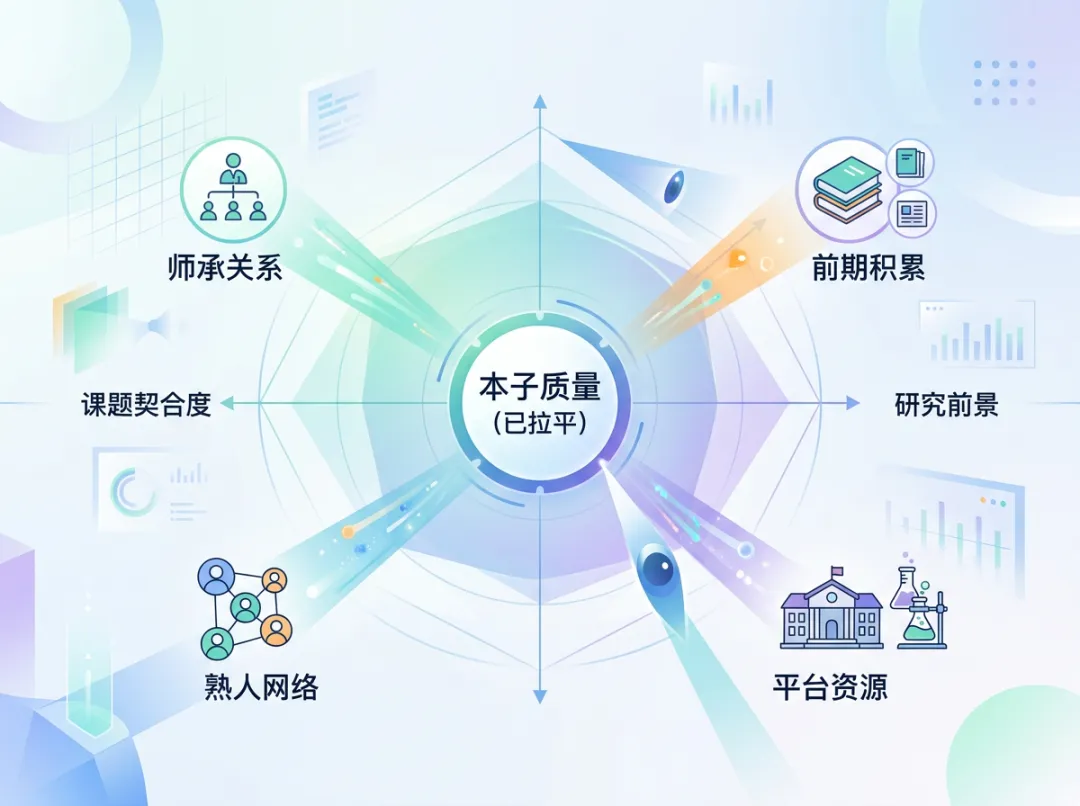
一旦进入这种模糊地带,评审就会本能地去找"额外信息"做锚点。最常见的就是申请人的出身、师门、合作网络。是不是某个组出来的?跟谁长期合作?有没有熟悉的人能间接背书?
很多人不愿意承认这一点,但评审的自白往往更诚实。有人说得很坦率:"遇到熟人的博后或学生的本子,多少会照顾一下。"多数时候不是明目张胆的偏袒,更像是临门一脚的手滑:B犹豫成A,评语多写两句"有潜力"。单看每一次都像小事,叠加起来,就会让同样处在中间梯队的人走向完全不同的结局。
精准送审在这里还会起到放大器的作用。方向越细、圈子越小,越容易"把本子精准送到认识你的人手里",熟人效应就更难避免。对有团队、有大佬圈层的人来说,这可能只是加一点保险;对那些没有平台光环、没在强组训练过的青年学者,就很残酷了——本子写得再工整,也缺少能被快速识别的信用背书。
五、"科研孤儿"的困境与出路
这里也不得不提一个现实:在AI把写作门槛拉平之后,靠"把本子写得更像本子"去赢,空间会越来越小。
所谓"科研孤儿"——博士或博后期间没有进入主流学术圈、导师学术影响力有限、所在平台资源不足的青年学者——他们的本子即使写得不错,也常常面临一个尴尬处境:在没有足够前期成果作为"硬件"支撑的情况下,评审人很难仅凭本子就给出高度评价。而前期成果的积累,恰恰最依赖平台和师承资源。
有评审坦言:"申请人前期没有在大佬组历练过,也没有比较好的求学背景,写的本子的确很粗糙,创新性也很一般。"反过来理解就是:在大佬组历练过的人,写出来的本子通常不至于太粗糙。好的学术训练本身就包含本子写作能力的培养。但当"本子质量"高度包含于学术训练和平台资源之中时,它就不再是一个独立变量了。
这么说不是要把整个函评制度说得一无是处。平心而论,每年能拿到的项目里,绝大多数还是给了那些确实有想法、有积累的人。圈子、关系、师门这些东西确实存在,也在起作用,但还没有大到能把整个系统推倒的程度。真正写得好的本子——科学问题抓得准、逻辑清晰、不靠堆砌文献撑场面的——最终大概率还是会被认出来。

2026年国自然函评的核心变迁,本质上是AI工具打破原有评价平衡后,评审体系的重新校准。AI抹平了形式差距,却无法替代科研本身的积累与思考,这也让评审回归科研本质:代表作所体现的硬实力、科研思路中的独特性、申请人对研究的深度理解,才是穿越AI包装、获得认可的核心。