 夜雨聆风
夜雨聆风AI知识库的构建是一个系统工程,涉及多模态数据的摄入、语义理解、高效检索与安全隔离,最终输出精准、可信的回答。以下从核心架构选型、ETL与索引设计、检索优化、安全与部署以及前沿演进五个方面系统展开。
一、核心架构选型
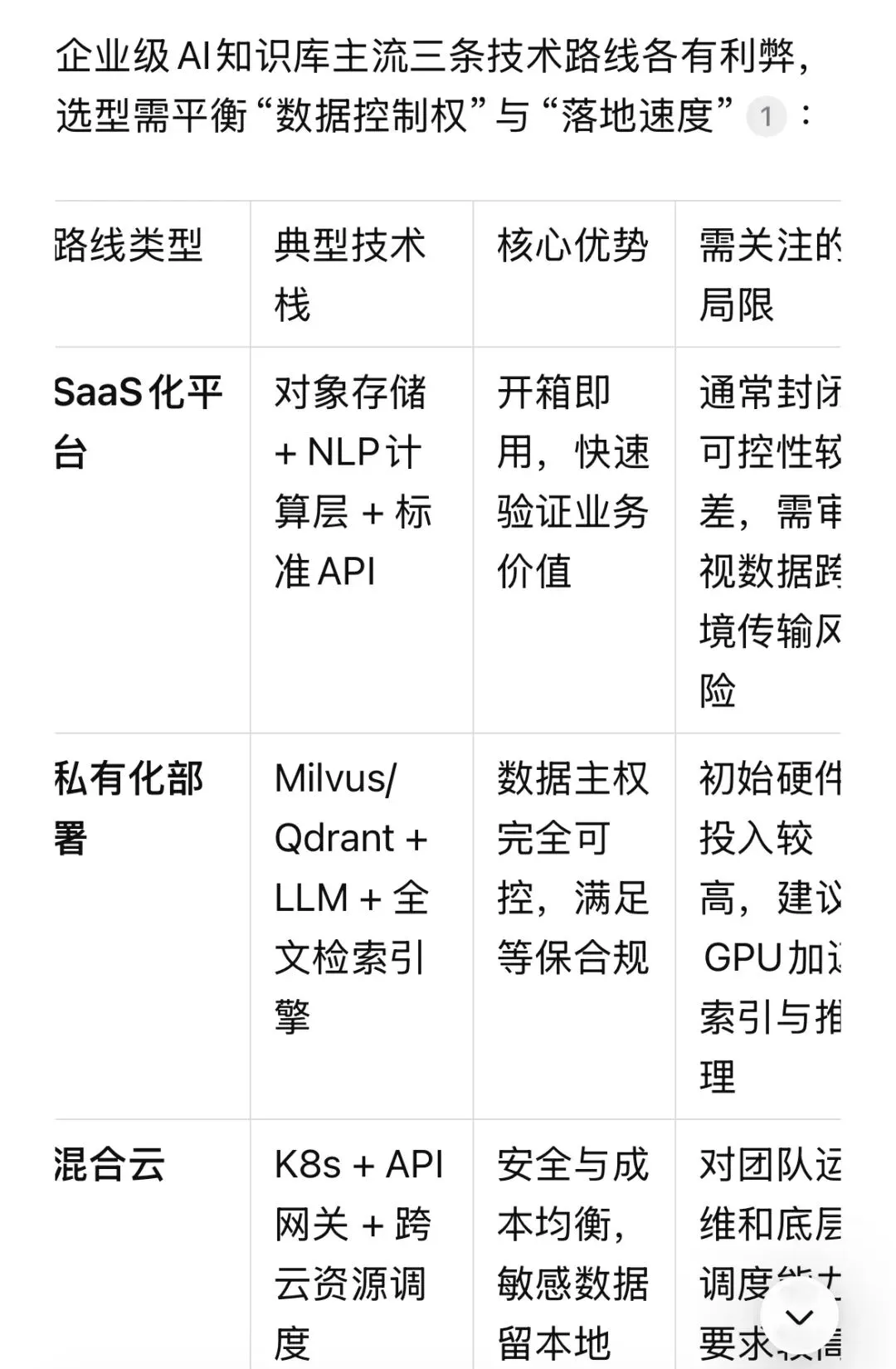
企业级AI知识库主流三条技术路线各有利弊,选型需平衡“数据控制权”与“落地速度”:
路线类型 典型技术栈 核心优势 需关注的局限
SaaS化平台 对象存储 + NLP计算层 + 标准API 开箱即用,快速验证业务价值 通常封闭可控性较差,需审视数据跨境传输风险
私有化部署 Milvus/Qdrant + LLM + 全文检索引擎 数据主权完全可控,满足等保合规 初始硬件投入较高,建议GPU加速索引与推理
混合云 K8s + API网关 + 跨云资源调度 安全与成本均衡,敏感数据留本地 对团队运维和底层调度能力要求较高
在私有化路线中,以RAG为核心的“检索+生成”双阶段架构是主流范式。相比微调大模型,RAG无需频繁重训即可对接企业知识,推理成本往往可降低70%以上。
二、ETL与索引设计
知识库的质量上限由上游ETL(数据提取、转换、加载)决定,可关注以下三个环节。
1、文档解析:夯实数据底座
文档需统一标准化处理,涉及多格式支持与清晰的结构识别。特别是对于PDF中的半结构化内容,建议采用分层解析策略,保留图文对照表的空间信息与合并单元格的层级关系,必要时结合DeepDoc等引擎进行复杂结构还原。
2、语义分块策略:避免“词不达意”
分块过程要保证块内语义完整,减少信息断裂:
· 固定大小分块:实现简单,方便引入重叠区保持上下文连贯,但容易破坏自然语义边界;
· 语义分块:通过计算相邻句子Embedding的相似度来决定分割点,能够构成主题连贯的完整知识单元;
· 递归分块:优先按段落等大粒度分割,再依句子逐级降级拆分,较好兼顾全局语义与局部粒度。
3、数据清洗与向量化
数据清洗时需要注意规范化操作,如统一大小写、校正拼写错误并去除停用词。之后选择合适的嵌入模型进行维度转换,可选择通用模型(如BGE)或基于垂直领域数据进行微调,以满足对细粒度语义匹配有高要求的场景。
在向量化后,选择适宜的数据库支撑检索。2026年主流选择如下:
· Milvus:开箱多租户隔离,支持GPU加速,适合超大规模企业场景;
· Pinecone:全托管无运维,适合追求极致敏捷、不愿投入基础设施成本的团队;
· Qdrant/Weaviate:开源灵活,自带优秀的元数据过滤能力,对数据主权敏感的企业首选。
三、检索优化与增强生成
用户在实际问答中不能仅靠相似度匹配,需引入多层机制提升精准度。
· 混合检索与重排序:可结合BM25等关键词精确匹配与向量语义相似度的双通道召回,再通过Reranker模型在首次召回结果中精准筛选。这种“先粗筛再精排”的两阶段策略,能有效弥补单路召回在语义粒度与交叉交互上的不足。
· 动态参数调整:根据用户问题的复杂程度弹性调整首次召回的数量(如简单50条、复杂问题200条),从而优化资源分配与检索效果。
四、安全与多租户部署
在成熟的知识库建设中,数据隔离是排在第一位的基石:
· 多租户架构:不同客户或部门共享一套系统实例,但数据和配置逻辑需完全隔离,通过访问控制与加密确保隐私安全。在技术路径上,Milvus等专业向量数据库在Collection与Partition键等维度提供了灵活的分层策略,适配从简单租户分离到精细化资源调度的各种场景。
· 细粒度权限:对于金融、政务等强合规场景,可结合JWT与属性访问控制实现索引级乃至文档级的权限划分与操作追溯。
五、前沿演进:GraphRAG与传统RAG的取舍
随着知识库走向3.0时代,以GraphRAG为代表的图增强方案正成为关键延伸。其主要区别在于:
· RAG(向量检索) :擅长处理宽泛的语义查询,适合从大量文档中快速定位相关段落,部署速度快,但在处理“XXX公司的关联方是否出现非正常财务波动”这类多跳逻辑时容易出现孤立召回;
· GraphRAG(图增强) :将文档碎片转化为实体间的结构化图谱,支持深层多跳推理与路径追踪。在处理法律或合规场景的多源关联查询时,准确率通常较传统RAG提升20%以上,但前期的实体抽取与图谱构建成本也相应提高。
对于大多数企业,短期内仍建议以稳定高效的RAG为核心,如果需要处理复杂的显式关联知识,可将GraphRAG作为特定主题或难题的增量插件,而非全面推翻现有方案。
六、选型决策框架
企业在实际决策时,建议依次评估以下三个维度:
数据安全等级:是否有本地化合规要求(如等保、医疗/金融数据不出域)?是 → 私有化方案;否 → 可考虑SaaS。
查询复杂度:以跨文档的关联推理为主,还是以片段类事实检索为主?前者 → GraphRAG或混合索引;后者 → 标准RAG。
团队运维能力:是否愿意投入K8s、GPU等基础设施成本?愿意 → 开源组件组装(Milvus + Reranker);希望快速上手 → 优先考量成熟的Agent编排平台(如Dify/RAGFlow)。
总的来说,AI知识库的构建需要经历从“异构数据解析”到“语义分块构建”,再经“混合检索与多租户隔离”,最终从RAG向GraphRAG逐步演进的完整链路与思维模式。从业务价值最高、需求最迫切的场景起步(如智能客服或内部文档助手),通过小范围验证选型并持续迭代索引与检索参数,再逐步扩展到权限隔离、多模态处理等复杂支撑能力,是当前比较稳妥的实施路径。
